
Method Article
Purificazione genoma a livello di extrachromosomal circolare DNA dalle cellule eucariotiche
In questo articolo
Riepilogo
This paper presents a sensitive method called Circle-Seq for purifying extrachromosomal circular DNA (eccDNA). The method encompasses column purification, removal of remaining linear chromosomal DNA, rolling-circle amplification and high-throughput sequencing. Circle-Seq is applicable to genome-scale screening of eukaryotic eccDNA and studying genome instability and copy-number variation.
Abstract
DNA circolare extrachromosomal (eccDNAs) sono elementi genetici comuni in Saccharomyces cerevisiae e sono riportati in altri eucarioti pure. EccDNAs contribuiscono alla variazione genetica tra le cellule somatiche negli organismi multicellulari e all'evoluzione degli eucarioti unicellulari. metodi sensibili per la rilevazione eccDNA sono necessari per chiarire come questi elementi influenzano la stabilità del genoma e come i fattori ambientali e biologici inducono la loro formazione nelle cellule eucariotiche. Questo video presenta un metodo eccDNA-purificazione sensibile chiamato Circle-Seq. Il metodo comprende colonna di purificazione del DNA circolare, eliminazione delle ultime DNA cromosomico lineare, l'amplificazione rolling-cerchio di eccDNA, sequenziamento profondo, e la mappatura. trattamento esonucleasi Ampio è stato richiesto per la degradazione del DNA cromosomico lineare sufficiente. Il passo di laminazione cerchio amplificazioneine-height:. normal; "> φ 29 polimerasi arricchito per il DNA circolare su DNA lineare convalida del metodo Circle-Seq su tre popolazioni di S. cerevisiae CEN.PK di 10 10 cellule rilevato centinaia di profili eccDNA in dimensioni più grandi di 1 kilobase . scoperte ripetute di ASP3-1, COS111, CUP1, RSC30, HXT6, HXT7 geni sul DNA circolare sia in S288c e CEN.PK suggerisce che circularization DNA è conservata tra i ceppi in questi loci. in sintesi, il metodo Circle-Seq dispone di un ampio applicabilità per lo screening del genoma scala per eccDNA negli eucarioti, nonché per la rilevazione di tipi eccDNA specifici.
Introduzione
Rilevare l'amplificazione presto o transitoria cromosomica è difficile perché richiede l'individuazione alterazioni singole molecole di DNA in grandi popolazioni di cellule. Cromosomiche variazioni copia-numerici (CNV) sono generalmente rilevate ben dopo la loro istituzione, lasciando solo la struttura finale CNV come prova del meccanismo che ha generato la variazione 1,2. Rilevamento e recupero del DNA extracromosomici circolare (eccDNA) nelle precedenti fasi di formazione CNV potrebbe spiegare i processi in corso in riarrangiamenti genomici.
In precedenza, de novo scoperta di eccDNA era di microscopio elettronico 3, Giemsa colorazione dei cromosomi in metafase 4 o bidimensionale elettroforesi su gel 5. Questi metodi forniscono poche o nessuna informazione sulla sequenza del DNA circolare. Tecniche mirate quali la Southern assorbente 6,7, inversa PCR 8, o in situ fluorescente hybridization 9 fornire la prova solo su elementi eccDNA specifici. Nessuno di questi metodi fornisce la sequenza di tutti i tipi eccDNA esistenti in una popolazione di cellule.
Divergenza genomica in un pool di cellule può essere caratterizzata da sequenziamento del genoma e / o array piastrelle 10,11. Rilevare una delezione o amplificazione mediante metodi di purificazione del DNA convenzionali di solito richiede che un allele mutato rappresentino almeno 0,1-1% della popolazione cellulare 12,13. Acentrico eccDNAs dovrebbero essere ancora più transitoria in una coltura cellulare a causa della loro mancanza di centromeri e potenziale assenza di sintesi del DNA in replicazione. Così, poiché la maggior parte eccDNAs sono presumibilmente in quantità basse e le loro sequenze assomigliano genoma, sono necessari metodi di estrazione del DNA alternativi per rilevare eccDNAs.
Diverse tecniche di purificazione del DNA circolari sfruttano le differenze strutturali tra cromosomi e DNA circolare. Per esempio, ultracentrifug ad alta velocitàzione in gradienti di cesio-cloruro viene utilizzato per isolare 350-3000 paia di basi (bp) grandi eccDNAs dalla linea di cellule di cancro umano HeLa 14. Tuttavia, ad alta velocità in grado di rompere o nick la spina dorsale delle strutture del DNA circolare supercoiled, alterando la velocità di sedimentazione 15 e il rendimento eccDNA. Dutta e colleghi hanno sviluppato un metodo per de novo, identificazione genoma scala di DNA circolare da tessuti di topo e da colture di pollo e cellule umane 16,17. Il loro metodo è l'estrazione di nuclei dal tessuto omogeneizzato da ultracentrifugazione saccarosio seguita da purificazione plasmide e diversi cicli di reazioni enzimatiche ed estrazioni di DNA. Il loro protocollo individua principalmente 200-400 eccDNAs bp, chiamati microDNAs. Dutta e colleghi anche tentato di purificazione di microDNAs da Saccharomyces cerevisiae, ma non erano in grado di registrare microDNA da questa specie di lievito 16.
Abbiamo sviluppato un nuovo metodo perde novo rilevazione di eccDNA da lievito chiamato Circle-Seq. Questo metodo consente sondaggi genoma scala per le molecole di DNA circolare abbastanza grande per trasportare geni interi e grande come il 86 kilobase (kb) DNA mitocondriale (mtDNA). Il metodo Circle-Seq è stato sviluppato da un procariote plasmide metodo di purificazione consolidata 18,19, ottimizzato per le cellule di lievito eucariotiche e combinato con sequenziamento profondo. Utilizzando l'approccio Circle-Seq, 1756 diversi eccDNAs, tutti più grandi di 1 kb, sono stati rilevati da dieci S. cerevisiae S288c popolazioni 20. Una dimensione di cut-off è stato scelto di concentrarsi su eccDNA che erano abbastanza grande per trasportare geni interi. Circle-Seq era molto sensibile; ha rilevato un unico eccDNA all'interno migliaia di cellule 20. Nel corso di studio, Cerchio-Seq è stato utilizzato per isolare ed identificare 294 eccDNAs da tre repliche biologiche di un altro S. cerevisiae ceppo di lievito, CEN.PK. I dati rivelano che eccDNA è un eleme genetica comunent a S. ceppi di cerevisiae.
Protocollo
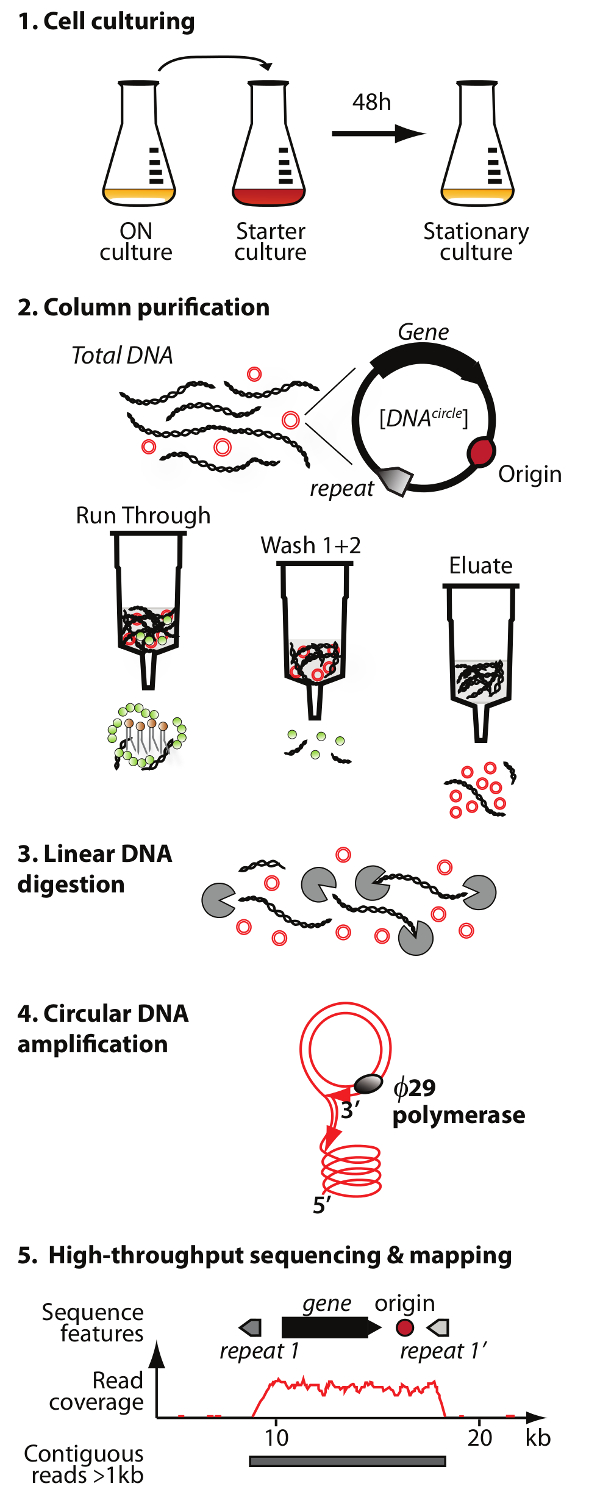
NOTA: Una panoramica della purificazione DNA circolare e metodo di sequenziamento (Circle-Seq) è illustrato in Figura 1.
1. La coltivazione, Cell Raccolta e membrana plasmatica Turbativa
- Seminare cellule di lievito (ad esempio Saccharomyces cerevisiae) da un / cultura O N in 50 ml di mezzo nutriente completa di lievito peptone destrosio (YPD). Inoculare a bassa densità cellulare iniziale di 1-3 x 10 5 cellule / ml o una densità ottica di circa 0,01 OD 600.
- Incubare le cellule a 30 ° C con agitazione a 150 giri al minuto (rpm) fino cellule raggiungono la massima densità cellulare di circa 1 x 10 10 cellule, dopo circa 24 a 48 ore o una densità ottica a OD 600> 10.0.
NOTA: Il tempo di coltivazione non è fondamentale in quanto le concentrazioni di cellule inferiore può essere utilizzata.
- Incubare le cellule a 30 ° C con agitazione a 150 giri al minuto (rpm) fino cellule raggiungono la massima densità cellulare di circa 1 x 10 10 cellule, dopo circa 24 a 48 ore o una densità ottica a OD 600> 10.0.
- Trasferire la cultura superato di un tubo conico da 50 ml, agglomerare le cellule per centrifugazione a800 xg per 3 minuti e scartare il surnatante.
- Lavare il pellet con 25 ml di soluzione tampone di 10 mM Tris-Cl, 1 mM EDTA, pH 8,0, ri-agglomerare le cellule per centrifugazione a 800 xg per 3 min e scartare il surnatante.
- Risospendere il pellet di cellule in 1,2 ml di tampone risospensione fornita da un kit plasmide colonna di purificazione.
- Passaggio facoltativo: Aggiungere plasmidi altamente diluite come controlli per la purificazione degli elementi di DNA circolare 20.
NOTA: il set di dati corrente, una miscela plasmide 7,7 microlitri è stato applicato per ciascun campione contenente 10 10 cellule. La miscela plasmide magazzino consisteva di tre plasmidi in diverse concentrazioni; pBR322 a 38 ng / campione, pUC19 a 0,5 ng / campione, e pUG72 a 0.01 ng / campione. - Trasferire la sospensione cellulare in due provette micro-centrifuga 2 ml, ciascuna completato con perle di vetro 0,5 mm ad un rapporto 1: 3 del volume totale della sospensione.
- Vortex ogni tubo alla massima velocità per 10 minuti per interrompere cellule del plasmamembrane. Pellet le sferette per centrifugazione a 268 xg per 30 sec e trasferire 1,2 ml surnatante combinato da due provette da microcentrifuga in una nuova provetta.
NOTA: Alternative al passo 1,6-1,7, usare zymolyase per distruggere le cellule in soluzione tampone 0,6 ml risospensione. Dieci unità di zymolyase possono interferire con 5 x 10 7 cellule entro 1,5 ore a 35 ° C.
2. EccDNA arricchimento mediante cromatografia su colonna
- Seguire il protocollo da un kit per la colonna di purificazione di plasmidi. In breve, il trattamento di ogni campione con 1,2 ml di soluzione alcalina, mescolare delicatamente e incubare 3 minuti a temperatura ambiente.
- Aggiungere 1,2 ml di tampone di neutralizzazione, mescolare delicatamente e centrifugare a 9650 xg per 5 min.
- Caricare la soluzione su una colonna equilibrata con soluzione 1 ml equilibrazione e consentire al liquido di fluire attraverso la colonna per gravità.
- Lavare la colonna con una soluzione di lavaggio 4 ml. Quando la soluzione è passata attraverso la resina, aggiungere accuratamente 0,3 ml eluizione cosìluzione per sostituire la maggior parte del volume vuoto 0,35 ml colonna.
- Eluire il DNA in un nuovo tubo di raccolta con la soluzione 1 ml di eluizione e precipitare il DNA con l'aggiunta di 0,8 ml di miscela di precipitazione. Centrifugare a 9650 xg per 10 min.
- Lavare il pellet di DNA con 0,5 ml di etanolo al 70%, centrifugare a 9650 xg per 5 min, aria secca per 5 a 15 min e sciogliere il DNA purificato in 25 microlitri di acqua sterile.
NOTA: Solo conservazione a breve termine del DNA in acqua è raccomandato. Preferibilmente, passare direttamente al punto 3.
3. La digestione del rimanente lineare DNA cromosomico
- Passaggio facoltativo: per facilitare la digestione specifica di DNA lineare esonucleasi, trattare il DNA purificato con una endonucleasi rara taglio come Noti. Per 5 mg DNA, usare 1 unità NotI, 5 microlitri 10x tampone di digestione e acqua sterile fino ad un volume totale di 50 microlitri. Incubare la reazione a 37 ° C per 16 ore e calore inattivare l'endonucleasi a 80 ° C per 5 min.
- Aggiungere 20unità esonucleasi (2 ml), 4 microlitri ATP (25 mM), 34 microlitri di acqua sterile e 10 microlitri 10x tampone di reazione direttamente al DNA endonucleasi-spaccati 50 microlitri di raggiungere un volume di reazione 1x di 100 microlitri, usando l'esonucleasi ATP-dipendente kit.
- Eseguire idrolisi di DNA a singolo filamento e doppio filamento lineare a 37 ° C per 5 giorni o più. Aggiungere un ulteriore ATP 4 microlitri (25 mM), 0,6 microlitri tampone di reazione 10x e 20 unità esonucleasi ogni 24 ore per continuare la digestione DNA enzimatica a un volume di reazione 1x.
- Dopo la rimozione di DNA lineare, campione 2 microlitri dalla soluzione esonucleasi trattata per confermare l'eliminazione di DNA lineare cromosomico mediante reazione a catena della polimerasi quantitativa (qPCR), utilizzando un marcatore cromosomico come l'actina gene ACT1 20.
- Ogni volume di reazione qPCR 20 ml contiene 2 ml campione esonucleasi-trattati, 150 Nm ACT1 primer 5'-TCCGTCTGGATTGGTGGTTCTA-3 'e 5'-TGGACCACTTTCGTCGTATTC-3 ', 2% (volume / volume) dimetilsolfossido, e master mix fluorescente 10 ml verde.
- Utilizzare la condizione di reazione; 3 min a 95 ° C, seguita da 45 cicli di 15 secondi a 95 ° C e 30 secondi a 60 ° C.
NOTA: ACT1 è un indicatore particolarmente adatto per DNA lineare in quanto le variazioni del numero di copie di questo gene sono deleteri 21-23 così eccDNA non dovrebbe portare ACT1. - Alternative alla analisi della digestione del DNA di qPCR sono standard PCR (4.3) o ioduro di propidio colorazione (4.4).
- Utilizzare campione esonucleasi trattati con 2 ml come modello PCR con primer ACT1 5'-TGGATTCTGGTATGTTCTAGC-3 'e 5'-GAACGACGTGAGTAACACC-3'. Poiché il controllo ACT1 positivo, usare 50-100 ng genomica S. DNA cerevisiae come modello. Condizioni di reazione della PCR; 3 min a 95 ° C, seguita da 35 cicli di 30 secondi a 95 ° C, 30 sec a 56 ° C e 1 min a 72 ° C.
- Le reazioni di PCR Run di gel electrophoresis on 1% agarosio con 0,5 ug / ml di bromuro di etidio. Cercare un 0,8 kb ACT1 band.
- L'assenza o la presenza di DNA lineare possono essere esaminati anche dal propidio ioduro colorazione prima e dopo l'amplificazione del DNA.
- Mescolare ciascun campione di DNA in un 1: Volume 1 con 1: 1,000 H 2 O-soluzione diluita di 20 mM propidio ioduro di magazzino. Lasciare soluzione al buio per 10-20 min a temperatura ambiente e analizzare colorazione del DNA mediante microscopia a fluorescenza ad ingrandimento 100x utilizzando un filtro di eccitazione di fluorescenza rossa a 663-738 nm ed un tempo di esposizione di 5 a 30 sec. Come il controllo del DNA-colorazione, uso Ø29-amplificato DNA genomico da lieviti e / o plasmide Ø29-amplificato.
- Calore inattivare la soluzione esonucleasi a 70 ° C per 30 min.
4. DNA Amplificazione
- Amplifica il purificata e arricchita eccDNA dal punto 3.5) con Ø29 DNA polimerasi 24-26 accordozione al protocollo del produttore polimerasi.
- In breve, mescolare 5 ml arricchiti eccDNA con tampone di denaturazione 5 ml.
- Dopo 3 minuti a temperatura ambiente, aggiungere tampone di neutralizzazione 10 ml. Mescolare delicatamente e aggiungere 30 ml master mix contenente tampone di reazione 29 ml e 1 ml Ø29 DNA polimerasi. Incubare la reazione a 30 ° C per 16 ore o più (fino a 72 ore). Calore inattivare la polimerasi Ø29 DNA a 65 ° C per 3 min.
5. Sequencing e analisi dei dati
- Tosare il eccDNA amplificato con un ultrasonicatore mirato per una dimensione media di destinazione massima di 300 bp. Utilizzare le seguenti impostazioni per un campione di DNA microlitri 130: potenza 450W di picco di intensità, 60 trattamento sec, fattore lavoro del 30%, a 200 cicli al raffica, temperatura di 7 ° C.
- Aggiungere etichette indice di codici a barre e adattatori per la frammentazione legge per la sintesi di librerie per il sequenziamento, utilizzando un metodo appropriato per la preparazione biblioteca.
- Eseguire sequenziamento profondo, per esempio come 141-nucleotide singolo-end legge su una piattaforma di sequenziamento high throughput.
- Mappa legge al genoma del lievito di riferimento sotto inchiesta e consentire legge per mappare a più regioni. Ad esempio, utilizzare un sistema di workflow liberamente disponibile 27,28 e di breve lettura software di mappatura allineatore 29.
- Identificare legge da regioni del eccDNAs putativi utilizzando contigui si legge, ad esempio, più di sette contigui legge (> 1 kb) senza lacune 20.
NOTA: Il software è disponibile 27,28 per esplorare mappato legge in regioni genomiche di interesse.
Risultati
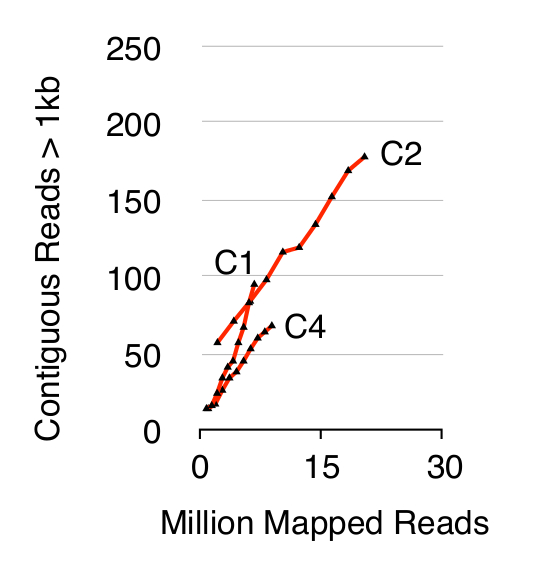
Per validare il metodo Circle-Seq, tre S. popolazioni cerevisiae CEN.PK di 1 x 10 10 cellule sono stati esaminati dopo che le cellule sono state coltivate separatamente in YPD per dieci generazioni. Cromosomica eliminazione DNA lineare è stato confermato dall'assenza di un segnale qPCR ACT1 come descritto in precedenza 20 (dati non mostrati). Purificata e arricchita eccDNA è stato sequenziato fino a 68 milioni di letture (141-nucleotide singolo-end legge) e mappato il genoma di riferimento CEN.PK113-7D (versione da 19 giugno 2012). Registrazioni di eccDNAs putativi dei tre campioni denominate C1, C2 e C4 sono stati assegnati a regioni genomiche mappati dal contigue legge più di 1 kb. Sulla base di 10.000 simulazioni Monte Carlo, il significato di ogni regione mappata contigue legge più di 1 kb è stato stimato. Da questo 79, 159 e 56 regioni sono state annotate come probabili sequenze eccDNA (p <0.1, Dataset 1). Il numero di contiguo registratoci legge> 1 kb aumentata in funzione della profondità di sequenza suggerendo che anche più elementi eccDNA sarebbero stati rilevati se campioni erano stati sequenziati maggiori (Figura 2). Come previsto, il metodo Circle-Seq estratto numerosi legge da un certo numero di elementi conosciuti circolari di DNA, tra cui il plasmide 2μ, il DNA mitocondriale, geni RNA ribosomiale sul cromosoma XII, e le tre plasmidi di controllo interno pBR322, pUC19 e pUG72 che sono stati addizionati in campioni appena prima purificazione colonna (Figura 3).
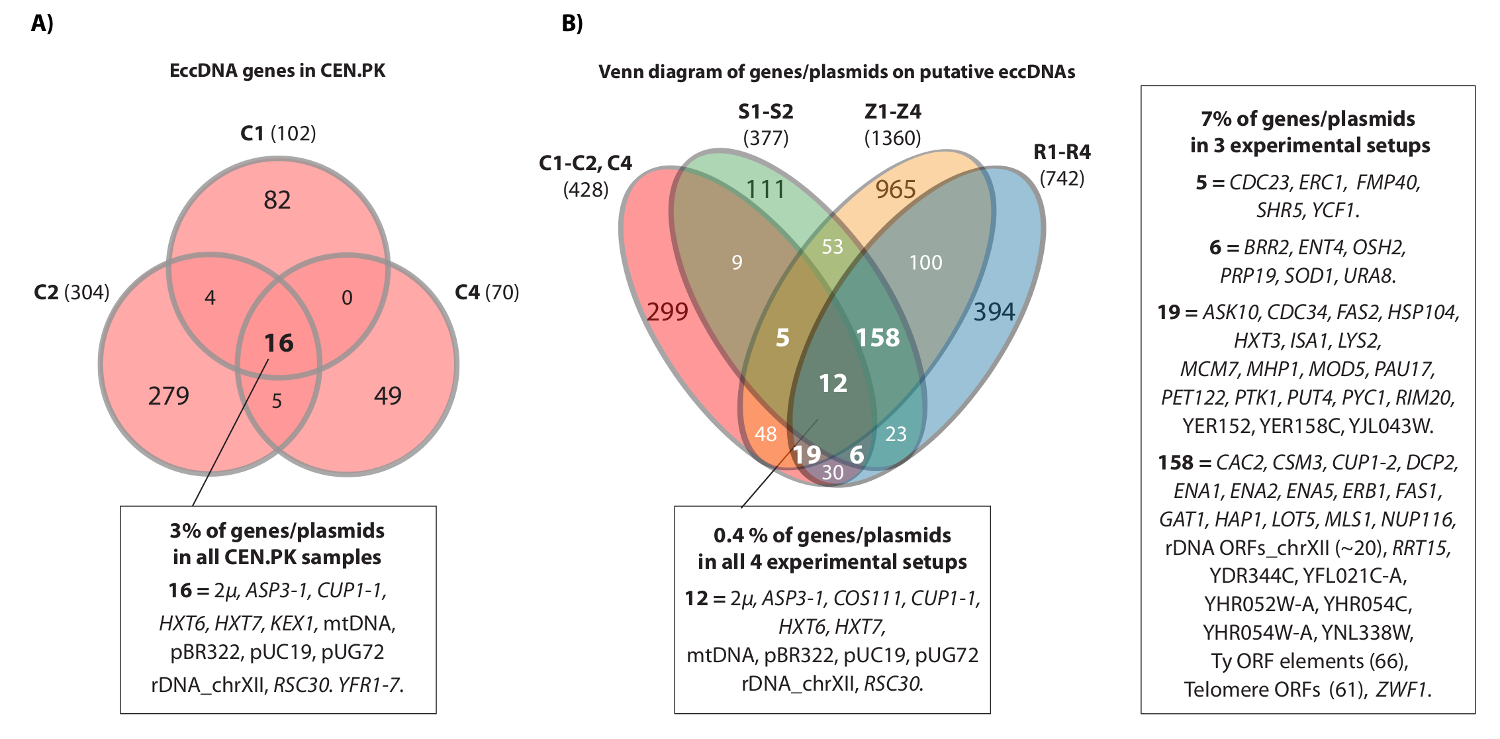
Il video mostra un esempio di contigui legge che mappato il locus HXT7 _ARS432_ HXT6 sul cromosoma IV. In precedenza, il [HXT6 / 7 cerchio] è stato rilevato dal Circle-Seq in dieci popolazioni S288c (ognuna con 1 x 10 10 cellule) e la struttura del DNA circolare è stata confermata da inversa PCR 20. Il [HXT6 / 7 CIicona circolare] è stato registrato anche in ciascuno dei tre popolazioni CEN.PK (Figura 4A). Inoltre, la maggior parte dei comuni geni eccDNA tra campioni ripetitivi CEN.PK sovrapposte eccDNA geni dai set di dati S288c (Figura 4B).
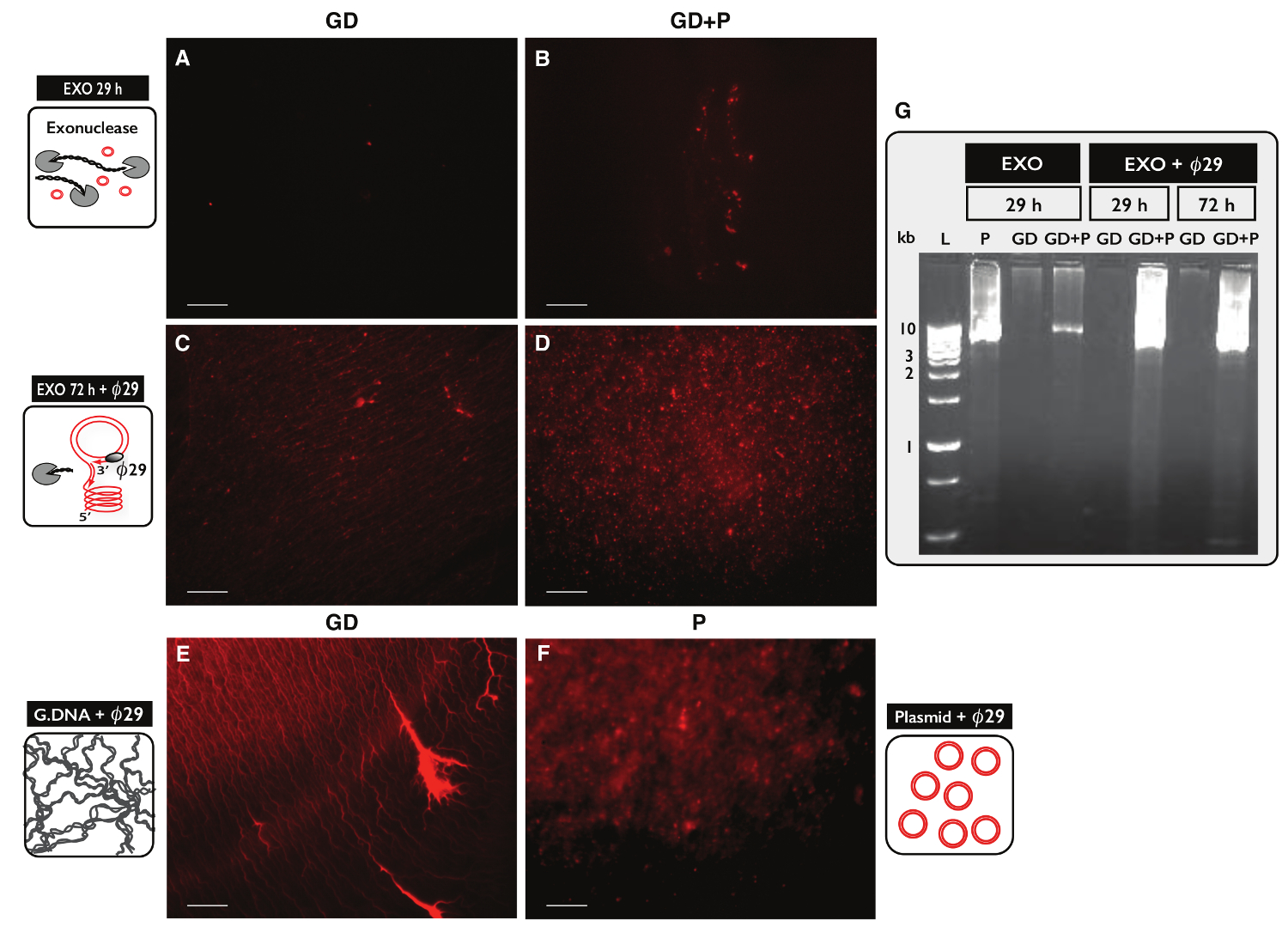
Per verificare la specificità del protocollo Circle-Seq per la purificazione di DNA circolare, due campioni, ciascuno con 30 ug di DNA genomico, sono stati testati. Un campione è stato integrato con 100 ng del plasmide DNA e eccDNA da entrambi i campioni sono stati purificati dal protocollo Circle-Seq. Dopo separazione della colonna, la resa DNA era di 1,27% (380 ng) per il campione senza plasmide (GD) e 1,60% (480 ng) per il campione con il plasmide (GD + P). L'efficacia del trattamento esonucleasi è stato testato per il contenuto di DNA lineare dopo 29 ore e 72 ore mediante PCR contro ACT1. Non ci sono campioni contenuti amplificato ACT1 (dati non riportati). Una frazione di ciascun campione esonucleasi trattato era inoltre unmplified dal Ø29 polimerasi e prodotti di reazioni enzimatiche sono stati analizzati mediante colorazione ioduro di propidio (Figura 5A-F) ed elettroforesi su gel di agarosio (Figura 5G). I campioni dopo il trattamento esonucleasi hanno mostrato il minimo ioduro di propidio-macchia (Figura 5A-B). Il Ø29 - campione amplificato con solo il DNA genomico rivelato strutture filiformi (Figura 5C) simili al campione di controllo (Figura 5E). Il Ø29 - campione amplificato che ha avuto plasmide aggiunto rivelato focolai (Figura 5D) che assomiglia al controllo plasmide (Figura 5F). Le immagini hanno indicato che Ø29 polimerasi arricchito per il DNA circolare su DNA lineare. Più DNA cromosomico lineare è stato rimosso da campioni dopo il trattamento 29 hr esonucleasi (Figura 5A-B, G). Tuttavia, esteso trattamento esonucleasi per più di 100 ore e con più di 100 unità era necessario per rimuovere tutto il DNA cromosomico lineare, come O29 - campioni amplificati ancora mostrato uno sfondo di strutture filiformi, dopo 72 ore di trattamento esonucleasi (Figura 5C-D).

. Figura 1. Schema del metodo Circle-Seq Il protocollo ha 5 fasi: 1) coltura cellulare, 2) la purificazione e l'arricchimento di eccDNA mediante cromatografia su colonna, 3) digestione del restante DNA cromosomico lineare nella frazione di eluato, 4) amplificazione DNA da Ø29 DNA polimerasi, e 5) sequenziamento altamente arricchito eccDNA e mappatura di legge al S. genoma di riferimento cerevisiae. Cliccate qui per vedere una versione più grande di questa figura.
{kind=link}
p_upload / 54239 / 54239fig2.jpg "/>
Figura 2. Attiguo legge> 1 kb come funzione della profondità di sequenza. EccDNA da 1 x 10 10 cellule aumentano in funzione della profondità di sequenza (in milioni di letture mappata). Indicato: triplicato biologiche provenienti dalla aploidi CEN.PK S. popolazioni cerevisiae (C1, C2, C4) separati da 10 10 divisioni cellulari. Cliccate qui per vedere una versione più grande di questa figura.
{kind=link}

Figura 3. Rilevamento di noti elementi di DNA circolare. (AB) Scatter trame di copertura lettura (leggi densità) in percentuale per i plasmidi in CEN.PK biologico repliche C1, C2 e C4. (A) mappato legge ai plasmidi di lievito endogeni sono stati: 2μ; [RDNA cerchio] (geni RNA ribosomiale dal cromosoma XII); e mtDNA (DNA mitocondriale). (B) si legge unico mappato per controllare plasmidi. plasmidi di controllo sono stati addizionati in campioni prima di purificazione colonna. rapporti di plasmidi per cellula erano: pBR322 (segni più) 1: 1, pUC19 (cerchi) 1:50 e pUG72 (triangoli) 1: 2.500.

Figura 4. elementi comuni eccDNA in CEN.PK e S288c. (A) diagramma di Venn visualizzazione sovrapposizione tra i 476 geni 294 elementi eccDNA nei tre campioni CEN.PK (C1, C2, C4). I 16 comuni che si sovrappongono geni eccDNA / plasmidi sono annotati (tutti i nomi del gene sono nel set di dati 1). (B) diagramma di Venn di tutti i geni registrati su eccDNAs putativi dei tre campioni CEN.PK (C1, C2, C4), rispetto a tutti i geni registrati su eccDNAs putativi da 10 S288c campioni: S1-S2, R1-R4, Z1-Z4 (vedi riferimento 20). Indicato sono 13 repliche biologiche (S1-S2, R1-R4, Z1-Z4, C1-C3) con i geni / plasmidi e regioni eccDNA putativi che si sovrapponevano un minimo di 2 ambiti di deformazione e 3 o più sperimentali messe a punto. campioni C, CEN.PK; campioni R e Z, S288c BY4741; Campioni S, S288c M3750. Cliccate qui per vedere una versione più grande di questa figura.
{kind=link}

Figura 5. Visualizzazione di campioni di DNA dopo esonucleasi e Ø 2 9 trattamento. (AF) propidio ioduro colorazione del DNA. barra della scala, 10 micron. (A, C ed E) I campioni con DNA genomico (GD); (B e D) i campioni con GD più plasmide (GD + P). ( ong> AB) Dopo il trattamento esonucleasi 29 ore (Es 29 h); (CD) dopo il trattamento esonucleasi 72 ore seguita da Ø29 amplificazione della polimerasi (EXO 72 h + O29). (E) controllo DNA genomico dopo e: l'amplificazione della polimerasi Ø29; (F) Controllo plasmide (5.5 kb) dopo amplificazione 29 polimerasi; (Ø G) agarosio gel eletrophoresis. Da sinistra: L, 1 kb marcatori; P, il controllo plasmide (5.5 kb) dopo EXO 29 ore; GD, dopo EXO 29 hr (campione in A); GD + P, dopo EXO 29 ore (campione B); GD e GD + P, dopo EXO 29 ore + Ø29; GD e GD + P, dopo EXO 72 ore + Ø29 (campione in CD). Vedi Tabella S1 extra per i dettagli. Si prega di cliccare qui per vedere una versione più grande di questa figura.
{kind=link}
Aset 1 "src =" / files / ftp_upload / 54239 / 54239dataset1.jpg "/>
Set di dati 1. I potenziali regioni di circolari del DNA in CEN.PK. Cliccate qui per scaricare questo file.
vengono riportati i dati di sequenza e analisi per 348 regioni. Le colonne sono dC, la mappatura eccDNA. A (prima colonna da sinistra), campione da cui è stato identificato putativo eccDNA; B, cromosoma; CD, avviare e coordina fine eccDNAs putativi. EH, contenuti eccDNA. E, autonomamente replicare sequenza (ARS) nella regione; F, completa gene nella regione; G, parte del gene incluse nella regione; H, gene BLASTN-identificato. IO, la copertura EccDNA e p-value. I, nella regione più lunga con una sequenza annotato unicamente in bp; J, numero di tutti mappato legge; K, la copertura di tutti mappati legge da frammenti per ogni kb da un milione mappato legge (FPKM); L, p-value per putativo eccDNA rispetto a verificarsi per caso da simulazioni Monte Carlo; M, il numero di uniquely mappato legge; NO; come K e L utilizzando solo mappata univocamente legge (UFPKM). I parametri per la mappatura di legge e simulazioni Monte Carlo sono stati descritti 20.
Discussione
Il metodo Circle-Seq permette la rilevazione del genoma scala di eccDNA da cellule di lievito con risoluzione a livello di sequenza. Il metodo è una purificazione eccDNA lieve che non richiede vortex intensive o pipettaggio e utilizza separazione colonna per gravità per limitare eccDNA rotture che porterebbe ad esonucleasi digestione nel passaggio successivo. Queste caratteristiche del metodo può essere cruciale per il rilevamento di grandi eccDNAs che contengono sequenze geniche. Circle-Seq rilevato numerose eccDNAs tra geni completi (set di dati 1). Ha inoltre rilevato il 86-kb lievito DNA mitocondriale. Così, questo protocollo facilita la purificazione di grandi elementi di DNA circolari. Mantenere il numero di passi di estrazione del DNA al minimo riduce il rischio di perdita eccDNA e massimizza il rendimento. In base ai risultati per il controllo, a spillo-in plasmidi, Cerchio-Seq è molto sensibile, rilevando un unico DNA circolare da 2.500 cellule. Inoltre, la rimozione di abbondanti plasmidi endogeni quali 2μ; plasmide o DNA mitocondriale potrebbe migliorare in modo significativo la sensibilità. Polimerizzazione di 2μ da colture di lievito è stato descritto 30. In alternativa, 2μ e la rimozione del DNA mitocondriale potrebbero essere ottenuti con una endonucleasi rare taglio, ad esempio Swai. Tuttavia, la fase di enzima di restrizione potrebbe colpire altri eccDNAs di interesse e limitare il rendimento totale eccDNA.
Passaggi critici per il rilevamento eccDNA erano rimozione di DNA lineare (fase 3) e sequenziamento del DNA (fase 5) ad una profondità adeguata. Per registrare la maggior parte dei eccDNAs da una popolazione di cellule, sequenziamento potrebbe essere necessaria 20. sequenziamento associati-end dovrebbe fornire anche una maggiore fiducia di rilevazione eccDNA, come giunzioni DNA circolare sono tenuti a produrre abbinato-end legge che mappa discordante. Queste discrepanze supportano la scoperta di strutture di DNA circolare e possono potenzialmente essere utilizzati come filtro eccDNA-rivelazione aggiuntivo.
Il Cerchio-SeMetodo q è stato convalidato utilizzando tre S. indipendenti popolazioni cerevisiae CEN.PK. Sequenze rilevate inclusi precedentemente riportato eccDNAs, plasmidi endogeni ed è stata aggiunta in plasmidi e centinaia di eccDNAs putativi (set di dati 1). Questi risultati sostengono precedenti serie di dati Circle-Seq da S. cerevisiae S288c 20. La scoperta di diversi eccDNAs comuni alle popolazioni CEN.PK e S288c indica che questi loci hanno una propensione a esistere come elementi circolari (Figura 4). Abbiamo precedentemente dimostrato che la [cerchio GAP1] è arricchito sotto azoto condizioni limitate sullo sfondo CEN.PK 8, anche se non è stato trovato prove di [cerchio GAP1] in altri ambiti di deformazione. Ritrovamento eccDNA dal CUP1-1 RSC30, ASP3-1, COS111, e HXT6 HXT7 loci sia S288c e CEN.PK suggerisce che una predisposizione per circularization DNA è conservito tra i ceppi di lievito. Resta da dimostrare se [HXT6 / 7 cerchio], [cerchio ASP3-1], [cerchio COS111], e [cerchio CUP1-1 RSC30] conferiscono vantaggi selettivi per le cellule, o se la loro esistenza è soltanto un effetto di alti tassi di circularization DNA.
Nel loro insieme, i risultati indicano che Circle-Seq è adatto per la rilevazione eccDNAs kilobase dimensioni e presenta vantaggi per l'identificazione eccDNAs con i geni completi. Circle-Seq è un metodo altamente sensibile che consente schermi interi genoma scala di eccDNAs dal lievito. Il metodo Circle-Seq potrebbe aprire un nuovo campo di ricerca volta a chiarire il ruolo di eccDNA nel generare delezioni geniche e amplificazioni. Dato che l'architettura e la struttura del DNA sono in gran parte conservati dal lievito eucariotica a eucarioti superiori, il metodo Circle-Seq dovrebbe, in linea di principio, essere applicablE per tutte le cellule eucariotiche, con lievi modifiche. Allo stato attuale, il metodo non sembra avere alcuna limitazione, anche se la sua capacità di purificare eccDNAs Megabase dimensioni deve ancora essere dimostrato. Inoltre, l'uso di Ø29 DNA polimerasi, che utilizza un metodo di amplificazione rolling-cerchio 31, crea una polarizzazione verso eccDNAs piccole rendendo eccDNA quantificazione più difficile. Circle-Seq rileva eccDNAs grande abbastanza per portare i geni pieno, che lo rende adatto per gli studi sulle doppie minuti-circolari di DNA da cellule somatiche umane. Doppia minuti possono contribuire al cancro quando proto-oncogeni sono amplificati su questi elementi 32-37. Studi di eccDNAs nelle cellule germinali potrebbero essere utilizzati per misurare i tassi di mutazione germinale e valutare la qualità dello sperma, per esempio nel bestiame. Così, Circle-Seq ha il potenziale per produrre intuizioni il tasso al quale variazione genetica pone in forma di variazione del numero di copie, e portare a una nuova comprensione di malattie che coinvolgono gene copiaturanumero di variazione 38-40.
Divulgazioni
The authors declare that they have no competing financial interests.
Riconoscimenti
Thanks to Kenn D. Møller and Claus Sternberg (DTU) for technical assistance and to Tue S. Jørgensen for quantitative PCR analysis.
Materiali
| Name | Company | Catalog Number | Comments |
| Bacto peptone | BD Difco | 211677 | Alternative product can be used. |
| Brilliant III SYBR Green PCR Master Mix | Agilent Technologies | 600882 | For qPCR analysis. Alternative product can be used. |
| Dextrose (D-glucose) | Carl Roth | HN06.4 | Alternative product can be used. |
| Disruptor Beads, 0.5 mm | Scientific Industries, Inc. | SI-BG05 | Glass beads to disrupt plasma cell membranes. Alternative product can be used. |
| Ethidium bromide | Carl Roth | 2218.2 | Agarose gel stain for detecting DNA/RNA. |
| GeneJet plasmid miniprep kit | Thermo Fisher | K0502 | Plasmid purifcation from bacteria. Alternative product can be used. |
| NotI, FastDigest | Life Technologies - Thermo Fisher Scientific, USA | FD0594 | Endonuclease. Alternative product can be used. |
| Plasmid Mini AX kit | A&A Biotechnology, Poland | 010-50 | Plasmid purifcation kit used to purify eccDNA. |
| Plasmid-Safe ATP-dependent DNase kit | Epicentre, USA | E3105K | ATP-dependent exonuclease kit. Alternative product can be used. |
| Propidium iodide | Sigma-Aldrich, USA | 81845 | Alternative product can be used. |
| pUG6 plasmid | EUROSCARF, Germany | P30114 | Marker gene: loxP-PAgTEF1-kanMX-TAgTEF1-loxP. |
| QIAGEN genomic-tip 100/G | Qiagen, USA | 13343 | Genomic DNA purifcation from yeast. Alternative product can be used. |
| REPLI-g Mini Kit protocol | Qiagen, USA | 150023 | Amplification of eccDNA by the phi29 polymerase. |
| Yeast extract | BD Difco | 210929 | Alternative product can be used. |
| Zymolyase 100T (Lyticase, Yeast Lytic Enzyme) | Nordic BioSite, Sweden | Z1004-3 | Alternative product can be used. |
| Data access to sequence files | European Nucleotide Archive | EccDNA dataset from Saccharomyces cerevisiae CEN.PK113-7D. Study accession number PRJEB9684. 2nd accession number is ERP010820. Locus tag prefix is BN2032. | |
| Name | Company | Catalog Number | Comments |
| Strains | |||
| Saccharomyces cerevisiae CEN.PK113-7D | Genotype MATa MAL2-8c SUC2 | ||
| Saccharomyces cerevisiae yeast deletion library pool | EUROSCARF, Germany | S288c BY4741 pool of 4400 viable single-gene deletion mutants disrubted by KanMX module. Genotypes MATa his3Δ1 leu2Δ0 met15Δ0 ura3Δ0 genexxx::KanMX. | |
| Name | Company | Catalog Number | Comments |
| Equipments | |||
| DNA Spectrophotometer | NanoDrop 1000 Spectrophotometer, Thermo Fisher | Measuring DNA concentration. Alternative product can be used. | |
| Fluorescence microscopy | Nikon Optronics Magnafire. Red excitation fluorescence filter, 663-738 nm. | Alternative product can be used. | |
| Robotic library-build system | Apollo 324, IntegenX Inc. | DNA library preparation. Alternative product can be used. | |
| Sequencing platform | Illumina HiSeq 2000 platform, Illumina Inc. | DNA sequencing. Alternative product can be used. | |
| Ultrasonicator | Covaris LE220, microTUBE AFA Fiber tubes | Alternative product can be used. | |
| Name | Company | Catalog Number | Comments |
| Methods | |||
| 2% YPD media | Mix 10 g Dextrose, 10 g Yeast extract, 20 g Bacto peptone and add H2O to a total volume of 1000 ml and autoclave. | ||
| Circle-Seq test on genomic DNA | Genomic DNA was purified (Qiagen) from a pool of the yeast deletion library (Euroscarf). The DNA concentration was measured by nanodrop and 30 µg genomic DNA was pipetted into two micro centrifuge tubes. One micro centrifuge tube was supplemented with 100 nanogram plasmid (pUG6). The DNA samples were purified by Circle-Seq, omitting the protocol steps 1.1-1.3 and 1.5-1.7. The eluted DNA concentrations were measured by nanodrop and the entire DNA yield from sample GD and GD+P was treated with exonuclease for a period of 29 hours. A 10% fraction was collected for phi29-amplification and PCR analysis, while the remaining DNA was subjected to 72 hour exonuclease treatment. The samples were analyzed for linear DNA content by PCR, using the ACT1 gene as chromosomal marker. A 5% fraction of each of the exonuclease treated samples was amplified by the phi29 DNA polymerase for 16 hours (Qiagen). The presence of DNA in each sample was examined by loading an equal amount (7 µl) in wells on an 0.5 µg/ml ethidium-bromide 0.9% agarose gel after running gel-electrophoresis. | ||
| Mapping software | Bowtie2 aligner, John Hopkins University | Ultrafast short read alignment. Reference: 29. | |
| Propidium iodide stain | Images of propidium iodine stained DNA were captured by fluorescence microscopy at 100x magnification (100x/1.30 oil, Nikon) in the RFP channel (red excitation fluorescence filter, 663-738 nm) using identical exposition time (5 seconds). | ||
| Workflow bioinformatic system | Galaxy, Open source. | A free web-based platform for data intensive biomedical research. References: 27-28. |
Riferimenti
- Kugelberg, E., Kofoid, E., et al. The Tandem Inversion Duplication in Salmonella enterica.: Selection Drives Unstable Precursors to Final Mutation Types. Genetics. 185 (1), 65-80 (2010).
- Reams, A. B., Kofoid, E., Savageau, M., Roth, J. R. Duplication Frequency in a Population of Salmonella enterica. Rapidly Approaches Steady State With or Without Recombination. Genetics. 184 (4), 1077-1094 (2010).
- Smith, C. A., Vinograd, J. Small polydisperse circular DNA of HeLa cells. Journal of Molecular Biology. 69 (2), 163-178 (1972).
- Carroll, S. M., DeRose, M. L., et al. Double Minute Chromosomes Can Be Produced from Precursors Derived from a Chromosomal Deletion. Molecular and cellular biology. 8 (4), 1525-1533 (1988).
- Cohen, S., Yacobi, K., Segal, D. Extrachromosomal Circular DNA of Tandemly Repeated Genomic Sequences in Drosophila. Genome research. 13 (6A), 1133-1145 (2003).
- Horowitz, H., Haber, J. E. Identification of Autonomously Replicating Circular Subtelomeric Y' Elements in Saccharomyces cerevisiae. Molecular and cellular biology. 5 (9), 2369-2380 (1985).
- Moore, I. K., Martin, M. P., Dorsey, M. J., Paquin, C. E. Formation of Circular Amplifications in Saccharomyces cerevisiae by a Breakage-Fusion-Bridge Mechanism. Environmental and molecular mutagenesis. 36 (2), 113-120 (2000).
- Gresham, D., Usaite, R., Germann, S. M., Lisby, M., Botstein, D., Regenberg, B. Adaptation to diverse nitrogen-limited environments by deletion or extrachromosomal element formation of the GAP1 locus. Proceedings of the National Academy of Sciences of the United States of America. 107 (43), 18551-18556 (2010).
- Windle, B., Draper, B. W., Yin, Y. X., O'Gorman, S., Wahl, G. M. A central role for chromosome breakage in gene amplification, deletion formation, and amplicon integration. Genes & development. 5 (2), 160-174 (1991).
- Gresham, D., Ruderfer, D. M., et al. Genome-Wide Detection of Polymorphisms at Nucleotide Resolution with a Single DNA Microarray. Science. 311 (5769), 1932-1936 (2006).
- Kidd, J. M., Cooper, G. M., et al. Mapping and sequencing of structural variation from eight human genomes. Nature. 453 (7191), 56-64 (2008).
- Gresham, D., Desai, M. M., Botstein, D., Dunham, M. J. The Repertoire and Dynamics of Evolutionary Adaptations to Controlled Nutrient-Limited Environments in Yeast. PLoS Genetics. 4 (12), 1-19 (2008).
- Lang, G. I., Botstein, D., Desai, M. M. Genetic Variation and the Fate of Beneficial Mutations in Asexual Populations. Genetics. 188 (3), 647-661 (2011).
- van Loon, N., Miller, D., Murnane, J. P. Formation of extrachromosomal circular DNA in HeLa cells by nonhomologous recombination. Nucleic Acids Research. 22 (13), 2447-2452 (1994).
- Vinograd, J., Lebowitz, J. Physical and Topological Properties of Circular Dna. Journal of General Physiology. 49 (6P2), 103(1966).
- Shibata, Y., Kumar, P., et al. Extrachromosomal MicroDNAs and Chromosomal Microdeletions in Normal Tissues. Science. 336 (6077), 82-86 (2012).
- Dillon, L. W., Kumar, P., et al. Production of Extrachromosomal MicroDNAs Is Linked to Mismatch Repair Pathways and Transcriptional Activity. Cell Reports. 11 (11), 1749-1759 (2015).
- Li, L. L., Norman, A., Hansen, L. H., Sørensen, S. J. Metamobilomics - our knowledge on the pool of plasmid encoded traits in natural environments using high-throughput sequencing. Clinical microbiology and infection : the official publication of the European Society of Clinical Microbiology and Infectious Diseases. 18, 5-7 (2012).
- Brown Kav, A., Sasson, G., Jami, E., Doron-Faigenboim, A., Benhar, I., Mizrahi, I. Insights into the bovine rumen plasmidome. Proceedings of the National Academy of Sciences of the United States of America. 109 (14), 5452-5457 (2012).
- Møller, H. D., Parsons, L., Jørgensen, T. S., Botstein, D., Regenberg, B. Extrachromosomal circular DNA is common in yeast. Proceedings of the National Academy of Sciences of the United States of America. , 201508825(2015).
- Drubin, D. G., Miller, K. G., Botstein, D. Yeast Actin-Binding Proteins - Evidence for a Role in Morphogenesis. The Journal of cell biology. 107 (6), 2551-2561 (1988).
- Magdolen, V., Drubin, D. G., Mages, G., Bandlow, W. High levels of profilin suppress the lethality caused by overproduction of actin in yeast cells. FEBS letters. 316 (1), 41-47 (1993).
- Sandrock, T. M., Brower, S. M., Toenjes, K. A., Adams, A. Suppressor analysis of fimbrin (Sac6p) overexpression in yeast. Genetics. 151 (4), 1287-1297 (1999).
- Blanco, L., Bernad, A., Lázaro, J. M., Martìn, G., Garmendia, C., Salas, M. Highly Efficient DNA Synthesis by the Phage ø29 DNA Polymerase. The Journal of biological chemistry. 264 (15), 8935-8940 (1989).
- Dean, F. B. Rapid Amplification of Plasmid and Phage DNA Using Phi29 DNA Polymerase and Multiply-Primed Rolling Circle Amplification. Genome research. 11 (6), 1095-1099 (2001).
- Hutchison, C. A., Smith, H. O., Pfannkoch, C., Venter, J. C. Cell-free cloning using ø29 DNA polymerase. Proceedings of the National Academy of Sciences of the United States of America. 102 (48), 17332-17336 (2005).
- Goecks, J., Nekrutenko, A., Taylor, J., Galaxy Team, T. Galaxy: a comprehensive approach for supporting accessible, reproducible, and transparent computational research in the life sciences. Genome Biology. 11 (8), 86(2010).
- Giardine, B., Riemer, C., et al. Galaxy: A platform for interactive large-scale genome analysis. Genome research. 15 (10), 1451-1455 (2005).
- Langmead, B., Salzberg, S. L. Fast gapped-read alignment with Bowtie 2. Nature Methods. 9 (4), 357(2012).
- Tsalik, E. L., Gartenberg, M. R. Curing Saccharomyces cerevisiae of the 2 micron plasmid by targeted DNA damage. Yeast. 14 (9), Chichester, England 847-852 (1998).
- Norman, A., Riber, L., Luo, W., Li, L. L., Hansen, L. H., Sørensen, S. J. An Improved Method for Including Upper Size Range Plasmids in Metamobilomes. PLoS ONE. 9 (8), e104405(2014).
- Storlazzi, C. T., Lonoce, A., et al. Gene amplification as double minutes or homogeneously staining regions in solid tumors: Origin and structure. Genome research. 20 (9), 1198-1206 (2010).
- Von Hoff, D. D., Needham-VanDevanter, D. R., Yucel, J., Windle, B. E., Wahl, G. M. Amplified human MYC localized to replicating submicroscopic circular DNA molecules. Proceedings of the National Academy of Sciences of the United States of America. 85 (13), 4804-4808 (1988).
- Raymond, E., Faivre, S., et al. Effects of hydroxyurea on extrachromosomal DNA in patients with advanced ovarian carcinomas. Clinical cancer research : an official journal of the American Association for Cancer Research. 7 (5), 1171-1180 (2001).
- Shimizu, N. Extrachromosomal Double Minutes and Chromosomal Homogeneously Staining Regions as Probes for Chromosome Research. Cytogenetic and genome research. 124 (3-4), 3-4 (2009).
- Eckhardt, S. G., Dai, A., Davidson, K. K., Forseth, B. J., Wahl, G. M., Von Hoff, D. D. Induction of differentiation in HL60 cells by the reduction of extrachromosomally amplified c-myc. Proceedings of the National Academy of Sciences of the United States of America. 91 (14), 6674-6678 (1994).
- Vogt, N., Lefèvre, S. -H., et al. Molecular structure of double-minute chromosomes bearing amplified copies of the epidermal growth factor receptor gene in gliomas. Proceedings of the National Academy of Sciences of the United States of America. 101 (31), 11368-11373 (2004).
- Ahn, K., Gotay, N., et al. High rate of disease-related copy number variations in childhood onset schizophrenia. Molecular psychiatry. 19 (5), 568-572 (2013).
- Girirajan, S., Johnson, R. L., et al. Global increases in both common and rare copy number load associated with autism. Human molecular genetics. 22 (14), 2870-2880 (2013).
- Vogt, N., Gibaud, A., Lemoine, F., de la Grange, P., Debatisse, M., Malfoy, B. Amplicon rearrangements during the extrachromosomal and intrachromosomal amplification process in a glioma. Nucleic Acids Research. , (2014).
Ristampe e Autorizzazioni
Richiedi autorizzazione per utilizzare il testo o le figure di questo articolo JoVE
Richiedi AutorizzazioneThis article has been published
Video Coming Soon
Personale delle biblioteche
Copyright © 2025 MyJoVE Corporation. Tutti i diritti riservati