
このコンテンツを視聴するには、JoVE 購読が必要です。 サインイン又は無料トライアルを申し込む。
Method Article
イベントアリーナにおける「日常の記憶」をモデル化し、げっ歯類の同種中心表現を育成するための行動課題
要約
この最適化された「日常の記憶」プロトコルの目標は、イベントアリーナで、同種中心の空間表現の使用を促進する安定したホームベースを採用することでした。この動物モデルは、行動学的および生理学的手法を用いたイベント記憶の形成と保持に関する将来の研究のための効果的なテストベッドを提供します。
要約
イベントアリーナは、学習と記憶を調査するための最適なプラットフォームを提供します。この論文で説明されている食欲的な日常記憶タスクは、げっ歯類のエピソード記憶と空間記憶を調査するための堅牢なプロトコルを提供し、特に同種中心の記憶表現を促進します。ラットは、エンコードフェーズで食物を見つけて掘るように訓練され、時間の遅れの後、ラットには正しい位置で報酬食物ペレットを見つける選択肢が与えられます。このプロトコルでは、同種中心戦略の使用を促進する2つの重要な要素があります:1)ラットはセッション内およびセッション間で異なる開始位置から開始し、2)ラットが食事のために食べ物を運ばなければならない安定したホームベースが展開されます。これらの変更により、げっ歯類が同種中心の空間表現を使用してタスクを実行するように効果的に促します。さらに、このタスクは、被験者内の実験計画に優れたパラダイムを提供し、実験者がさまざまな条件を操作してばらつきを減らすことを可能にします。結果として得られるげっ歯類モデルは、行動学的および生理学的手法と組み合わせて使用することで、記憶の形成と保持に関する将来の研究のための効果的なテストベッドを提供します。
概要
学習と記憶の神経生物学を研究するためには、侵襲的な技術が必要ですが、これは一般的に人間では実現可能ではありません。このように、1世紀以上にわたり、実験動物が人間の記憶のさまざまな形態をモデル化するための行動プロトコルが設計されてきました。タスクと装置の両方の設計と選択は、人間の記憶の効果的なモデルの成功の中心です。単純な古典的および器械的条件付けプロトコル1,2,3から、T-迷路4、ラジアルアーム迷路5、バーンズ迷路6、ウォーター迷路7、チーズボード迷路8などの迷路まで、さまざまな複雑さで多数のパラダイムが開発されてきました。しかし、これらの課題は連想学習と空間ナビゲーションの側面を捉えていますが、瞬間的な出来事の記憶表現(つまり、エピソード的な記憶)を研究するために明確に使用することはできません。そして、新しい物体認識9と、この自発的な記憶課題の順列、例えば物体-場所記憶10は、認識記憶に関する貴重な洞察を提供したが、それらは出来事の明示的な想起をテストしていない。この要求に対処するために、イベントアリーナが特別に開発され、その使用により、長期的なペア付きアソシエイトメモリの符号化と想起11,12,13、および身近な空間で発生する離散イベントの符号化と想起の研究が可能になりました14,15,16,17,18。後者のテーマがこの原稿の焦点です。
イベントアリーナは、げっ歯類のイベントが発生する大きな正方形のオープンフィールドエリアです。アリーナのサイズは、ネズミまたはネズミを収容するようにスケーリングでき、げっ歯類は入場して探索することをお勧めします。アリーナ内で行われるイベントの典型的な例は、特定の場所にある砂井戸から食べ物を見つけて回収することです。イベントアリーナは、ラットやマウスが食べ物を探し、見つけ、掘り起こすように訓練される、そのような食欲をそそるタスクのために設計されています。それは、食べ物を暗い環境(この場合はアリーナに隣接して位置し、そこで食べる)に食べ物を持ち帰るという彼らの自然な傾向を利用しています。餌を掘るための最小限のトレーニングの後、げっ歯類は自然にこのタスクに取り組み、エンコード試行と、短い30分の遅延後にエンコード試行に続くリコール選択試行で優れたパフォーマンスを発揮します。選択型トライアルでは、いくつかの砂井戸(つまり、掘削場所)が利用可能になりますが、報酬が得られるのは1つだけです。
イベントアリーナ内では、さまざまなタスクを実行できます(例:空間記憶、エピソード的記憶、ペア関連学習)。エピソード様記憶の効果的なモデルを開発することに関心が寄せられたため、食物を見つけることができる場所を毎日変更する次のプロトコルが開発されました。このタスクでは、げっ歯類は、食べ物の報酬を掘り、成功裏に回収するイベントが、イベントアリーナ内で最近どこで発生したかを覚えておく必要があります。以下に概説するプロトコルは、ラットが毎日新しい場所で砂井戸を検索するエンコード試験を伴い、その後、遅延して、最近エンコードされた砂井戸の位置が報酬として与えられ、他の異なる場所にある別の代替砂井戸にはアクセス可能な食物が含まれていないリコール選択試験が行われます。前日に食べ物がどこにあったかを覚えておくことは役に立ちません:正しい場所をエンコードし、少なくともしばらくの間、毎日記憶する必要があります。そこで、この課題でモデル化され、私たち人間が日常的に使用している記憶の形を捉えるために、「日常記憶」という用語を導入しました。日常的な記憶の人間の例は、ショッピングモールで車を駐車した場所(図1A)や、家の周りで眼鏡を置いた場所を思い出すことです。このプロトコルでは、すべてのアリーナ内およびアリーナ外の手がかりは、日常生活の設定(つまり、自宅、オフィス、駐車場など)にあるのと同じように、すべて安定しています。したがって、げっ歯類は、身近な環境内で何かが最近起こった場所を覚えている必要があります(図1B)。このタスクは、水迷路19の遅延マッチング・トゥ・プレース(DMP)タスクと類似しているが、改善されている。食欲をそそるタスクであるため、げっ歯類の自然な行動を利用して、水から逃げたいという願望の代わりに、食べ物を探す20。ただし、水迷路7と同様に、正しい位置と正しくない位置を区別する局所的な手がかりはありません。動物は、記憶遅延時間を変化させた後で、正しい砂井戸の位置を特定するために、認識ではなく想起を使用する必要があります。

図1:日常の記憶 (A)人間の日常の記憶。駐車場に駐車されたグリーンカーを示す模式図。遅れて、ドライバーは彼女が車を駐車した場所を正確に思い出そうとします。(B)動物の日常の記憶。ネズミがイベントアリーナ内の場所で砂井戸からペレットを掘って回収する様子を示す模式図。遅延の後、ラットには、複数の誤った砂井戸(灰色)と1つの正しい砂井戸(緑)の選択試行が与えられます。 この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}
このイベントの舞台は、すでに「日常の記憶」の調査に活用されています。これらは、毎日自動的にエンコードされ、長期記憶に保持される記憶ですが、比較的短い期間で忘れられることがよくあります。Bast et al.14 は、短間隔後の優れた記憶から 24 時間後の偶然レベルまで変化する単調な遅延依存イベント記憶を示しました。しかし、メモリの保持は、ポストエンコーディングの新規性によって、または、複数のエンコーディング試行で、拡張された試行間隔15,17によって、首尾よく強化することができる。
イベントアリーナは用途が広く、比較的ストレスを感じません。嫌悪刺激は使用されません。アリーナのサイズとそれが収容するタスクは、ラット14,15とマウス16の両方に適応させることができます。また、陸上での作業として、水迷路21とは異なり、生理学的記録やカルシウムイメージング研究に適している。さらに、3R(Reduction、Refinement、Replacement)の原則に従って、イベントアリーナを使用した研究では、被験者内の実験デザインが実行可能であり(各動物が薬理学的介入、光遺伝学的刺激などの独自の制御として機能する)、モチベーションのための嫌悪刺激を必要としないため、統計的検出力を得るために必要な動物が少なくて済みます。初期訓練は、例えば新規性認識課題よりも多くの時間を必要とし、より多くのセッションにわたって行われるが、動物が安定した漸近的なレベルの課題遂行を達成すると、薬物、ビヒクル制御、または光遺伝学的刺激などの操作が、比較的少数の追加の訓練セッションを挟み込むことができる17.さらに、表現の明確な側面は、タスクを解決するときに使用される空間表現の性質など、イベントアリーナでの直接的な実験的制御下に置かれます。
表象の問題は、ネズミが最近の出来事がどこで起こったかを思い出すときに採用する精神的枠組みに関係している18。彼らは食べ物がどこにあるか覚えていますか、それとも食べ物への行き方だけを覚えていますか?ラットは、アリーナ18内の食欲的な課題を解決するために、同種中心的(地図的)または自己中心的(身体中心的)の空間表現を使用することができる。しかし、課題を遂行する際に各実験対象が採用する空間戦略を制御および特定するために、1つの空間表現のみの使用を選択的に促進することができる明確な訓練プロトコルが存在する。通常、ネズミが餌の報酬をその日の試験を開始したのと同じ場所に戻すときには、自己中心的な表現が採用され、これにより、前後に実行中に報酬の場所を記憶する機会が何度か与えられます。この空間戦略は、開始位置が日ごとに変更されるか、一定に保たれるかに関係なく使用できます。対照的に、ラットがアリーナの側面にある固定されたホームベースの場所に餌の報酬を運ぶ必要がある場合、同種中心の表現が好まれます。同種中心表現には、脳の記憶容量に関して多くの利点があります。
この論文では、同種中心の表現のみの採用を奨励するホームベースプロトコルについて概説しました。このタスクの代表的な結果を提供し、学習と記憶の調査にこの「日常記憶」のげっ歯類モデルを使用する利点を明確に示し、エピソードのような空間記憶の同種中心表現がどのように促進できるかを強調しています。
Access restricted. Please log in or start a trial to view this content.
プロトコル
この論文に記載されている方法は、エジンバラ大学の倫理審査委員会によって承認されています。実験動物の維持管理と科学実験での使用を規定する1986年英国動物(科学的手続き)法および1986年11月24日の欧州共同体理事会指令(86/609/EEC)に準拠しています。
注:以下に概説するプロトコルの実験対象は、Lister-hoodedラットですが、他のげっ歯類の系統にも適応できます。
1.動物の取り扱い、住居、および食品管理
- 到着後、リスターフードのオスのラットが落ち着くまで1週間かかります。この間、ケージの中で優しく撫でたりくすぐったりして、毎日それらに対処してください。彼らが落ち着いたら、毎日約5分間それらを拾い始めます。
- 到着時と週に2〜3日ごとに各ラットの体重を記録します。各ラットの体重が自由摂食体重の約85%〜90%まで徐々に減少するように、食物摂取量を調整します。これは、自由摂食ラットの確立された成長曲線を使用して推定できます。実験中は、ラットをこの食物制限体重範囲内に維持してください。
- ラットを12時間(ライトオン)/ 12時間(ライトオフ)の光サイクルで飼育し、光の段階(午前7時から午後7時)にすべての実験を行います。
2. 装置のセットアップ
- 実験室、制御室、イベントアリーナ
- 実験室と制御室は、2つの部分に分かれた1つの部屋、またはカーテンまたはドアで区切られた2つの隣接する部屋のいずれかであり、この実験に必要です。
注:この分離により、実験者がこの複雑な行動課題を実行し学習する際に、実験者が動物に影響を与えたり混乱させたりするのを防ぐことができます。 - 1つの部屋をイベントアリーナ、静的な環境キュー、および実験手順(つまり、実験室)専用にし、もう一方の部屋を使用して、実験者によるラットのパフォーマンスを記録します(つまり、制御室)。
注:イベントアリーナは、イベントと場所の関連付けを研究できる正方形のオープンフィールドエリアです(図2A)。「イベントアリーナ」という名前は、この装置が「イベント」が発生するアリーナ(つまり、オープンだが制約されたスペース)であるという事実に由来しています(たとえば、砂井に埋もれた食品ペレットを掘り起こす。 図2B)17、18。実験者の過労や怪我(背中の負担など)を防ぐために、アリーナは床面から高くなっています(~1m)。 - 透明なプレキシガラスを使用して、正方形(160 cm x 160 cm)のアリーナを構築します。アリーナの床は、49枚の可動式の白いプレキシガラスタイル(20 cm x 20 cm;図 2A,B)。中央に穴(直径6 cm)のある5つのタイルを追加で変更する:これらはアリーナ内の砂井戸を保持します。これらの変更されたタイルの 5 つの場所は、各セッションの砂井マップで概説されている構成で配置されています。
注意: 5つの砂井の位置の構成は、新しいセッションごとに変更されます(手順4.2を参照)。 - イベントアリーナを指定された実験室に配置します。アリーナ内の2つの場所:アリーナ内の2つの場所:4行目、2列目、4行目に、明確な触覚面を持つ2つのランドマーク(例:ゴルフボールの接着されたスタック(30 cm(高さ)x 11 cm(幅)x 11 cm(長さ)x 11 cm(奥行き))と黒いウォーターボトル(22 cm(高さ)x 9 cm(奥行き)))を配置します。 列 6 (図 2C)。
- アリーナ内のキューに使用されるオブジェクトとその位置は、実験全体を通して一定に保ちますが、70%エタノールで毎日清掃します。
- 3Dエクストラアリーナの手がかりを設定します:特徴的なランドマーク(例:模様のある球形のランタン(40 cm(d))、赤い星のランタン(60 cm(w))、青いランタン(70 cm(h)x 35 cm(w)))と、実験室の中央に配置されたイベントアリーナの周囲にパターンを配置します(図2D)。
- アリーナ外の手がかりに使用するオブジェクトとその位置は、実験全体を通して一定に保ちます。
- 実験室と制御室は、2つの部分に分かれた1つの部屋、またはカーテンまたはドアで区切られた2つの隣接する部屋のいずれかであり、この実験に必要です。
- ブラックボックス
- 動物がアリーナにアクセスできるようにするには、黒いプレキシガラスから4つの同一の黒いボックスを作成します(長さ:30 cm、幅:25 cm、高さ:35 cm/ボックス。 図2E)。各ブラックボックスには、1つの長さの表面にリモコンのスライドドアが必要です。これにより、実験者はラットのアリーナへの入場を制御できるようになります。
注:黒いプレキシガラスは暗いインテリアを作り出し、オープンフィールドのイベントアリーナの明るい環境よりもネズミに好まれます。 - これらのブラックボックスをアリーナの4つの壁のそれぞれの中央に配置します。これらのブラックボックスは、イベントアリーナの北(上)、東(右)、南(下)、西(左)の基本点を使用して、カメラでキャプチャされ、制御室のコンピューターで受信されるライブビデオフィードの上部に対する相対的な位置によって識別されます。
- ラットがスタートボックスと呼ばれる3つのブラックボックス(例:東、南、西)のいずれかからアリーナに入ることを許可します。 図 2A、オレンジ色の長方形)。残りのブラックボックス(例:北; 図2A、青い長方形)をホームベースとして、ラットはアリーナから回収した食物報酬(すなわち、ペレット)を食べるためにこれに入ります。
注:任意のブラックボックスの位置(すなわち、北、東、南、西)をホームベースとして指定することができますが、実験全体を通して一定に保つ必要があります:その位置の安定性は、同種中心の空間表現を成功裏に奨励するために重要です。 - スタートボックスとホームベースに、水用と餌用ペレットの2つの小さくて透明な平らな井戸(ホームベースの場合は、慣れ段階でのみ報酬に使用されます)を置き、各スタートボックスとホームベースにおがくずを置きます。
- 動物がアリーナにアクセスできるようにするには、黒いプレキシガラスから4つの同一の黒いボックスを作成します(長さ:30 cm、幅:25 cm、高さ:35 cm/ボックス。 図2E)。各ブラックボックスには、1つの長さの表面にリモコンのスライドドアが必要です。これにより、実験者はラットのアリーナへの入場を制御できるようになります。
- サンドウェルズ
- 内径(d)6 cm、総深さ(h)6 cmの透明なアクリルプラスチックを使用して、ネズミが回収する食物報酬を隠すために使用される砂井戸を作成します(つまり、見つけて掘り起こし、ホームベースに持って行って食べます)。球形の穴あきプラスチックボウルを上から4cmのところに挿入します。アリーナ内の適応されたタイルに砂井戸を挿入します。
注:プラスチック製のボウルは、ラットがアクセスできる報酬ペレット用のアクセス可能な部分(6 cm(d)x 4 cm(h))と、ラットがアクセスできないアクセスできないセクション(6 cm(d)x 2 cm(h))を作成します(図3A、B)。 - 報酬付き砂井戸では、エンコード試行とリコール選択試行の両方で、アクセス可能なセクションに 4 つの 0.5 g ペレットを、アクセスできないセクションに 8 つの食品ペレットを配置します (図 3C)。報酬のない砂井戸では、アクセスできないセクションに12個のペレットを置きます(図3C)。
注:報酬のある砂井戸と報酬のない砂井戸の両方に合計12個のペレットが含まれており、特別に準備された砂で満たされているため、砂井戸にペレットが隠されています。 - 砂とマサラパウダー(マサラ2.5 g / 砂2.5 kg)の混合物を砂井戸に充填して、食品ペレットから発せられる臭いを隠します。各セッションの開始時に、砂とマサラの混合物を新たに準備します(図3D)。
注:ステップ2.3.2および2.3.3は、エンコードおよび選択試行中に砂井戸から発せられる嗅覚アーティファクトを隠すように設計されています。これにより、ネズミの正しい砂井戸の位置の検索とその結果としてのタスクパフォーマンスは、餌が掘り出された場所の記憶のみによって導かれ、報酬のある砂井戸から発せられる匂いの手がかりによって導かれることが保証されます。 - 以前に報酬を得た1つの砂井戸の位置についてラットの記憶をテストするプローブ試験中に、アリーナ内に存在する5つの砂井戸すべてを非報酬として(つまり、アクセス可能なセクションに食料ペレットが利用できない)ようにします。正しい砂井戸の位置を含みます。
注:アリーナ内に存在するすべての砂井戸には、アクセスできないセクションに同じ数のペレット(n = 12)が含まれています。
- 内径(d)6 cm、総深さ(h)6 cmの透明なアクリルプラスチックを使用して、ネズミが回収する食物報酬を隠すために使用される砂井戸を作成します(つまり、見つけて掘り起こし、ホームベースに持って行って食べます)。球形の穴あきプラスチックボウルを上から4cmのところに挿入します。アリーナ内の適応されたタイルに砂井戸を挿入します。
- 全体的なセットアップとソフトウェア
- 壁掛けハロゲンランプ(115-125ルクス)を用いて実験室の照明を適度な明るさに保ち、室温を19-23°Cに維持する。
- 実験室のイベントアリーナの上に電荷結合デバイスカメラを設置して、ラットの動きと行動を記録および監視します(図4A)。カメラは、カスタムビデオキャプチャとカスタムコンピューターソフトウェア(エジンバラ大学のP.A.スプーナーによって開発された)の両方のために、隣接する制御室にライブフィードを提供します。
- ラットの時間を計るために使用されるカスタムコンピュータソフトウェアを使用して、ラットの動きを監視します(図4B)。このプログラムは、各ブラックボックスのドアを制御し、実験者が隣接する制御室からアリーナへのラットの出入りをリモートで管理できるようにします。各動物の遅延を記録して、正しい砂井戸を特定し、選択とプローブの試行中に各砂井戸を掘るのに費やした時間を記録します。

図2:イベントアリーナとキュー(A)イベントアリーナを示す概略図(略語:N =北、E =東、S=南、W =西)。(B) アリーナ内およびアリーナ外の手がかりがあるイベントアリーナ。(C) 2つの3Dイントラアリーナキュー(左から右):ゴルフボールスタックと円筒形の黒いボトル。(D)いくつかの3Dエクストラアリーナの手がかり(左から右へ):パターン化された球形のランタン。赤い星のランタン;ブルーランタン。(E) 4つのブラックボックスのうちの1つは、各イベントアリーナの壁の中央に配置されています。これらのブラックボックスのうち3つはスタートボックスとして機能し、各試行の開始時にラットの開始位置を提供します。4つ目のブラックボックスは、ネズミがアリーナから回収した餌を消費するホームベースです。この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}

図3:砂井戸 (A)空の砂井戸を示す図で、アクセス可能なセクションとアクセスできないセクションにラベルが付けられています。(B)アクセス可能なセクションとアクセスできないセクションがある空の砂井戸。(C)報酬あり(左)と非報酬(右)の砂井内のペレット配置を示す概略図。報酬のある砂井戸と報酬を得ない砂井戸の両方に合計12個のペレットが含まれており、特別に準備された砂で満たされているため、砂井戸にペレットが隠されています。(D)アクセス可能なセクション(ステップ1-4)へのペレットの正しい配置を含む、報酬のある砂井の準備を示す一連の写真。 この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}

図4:イベントアリーナの実験セットアップ(A)実験室と制御室の実験セットアップを示す概略図。(B)カスタムコンピュータソフトウェアを通じて表示された実験室のライブフィードを示すスクリーンショット。カスタムコンピュータソフトウェアにより、実験者はスタートボックスのドアをリモートで制御し、他の測定を行うことができます。この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}
3. 慣れのプロトコル
注:慣れている間、ネズミは砂井戸を探し、食べ物の報酬を掘り、イベントアリーナを探索するように訓練されています。
- 食べ物の報酬のために掘ることを学ぶ
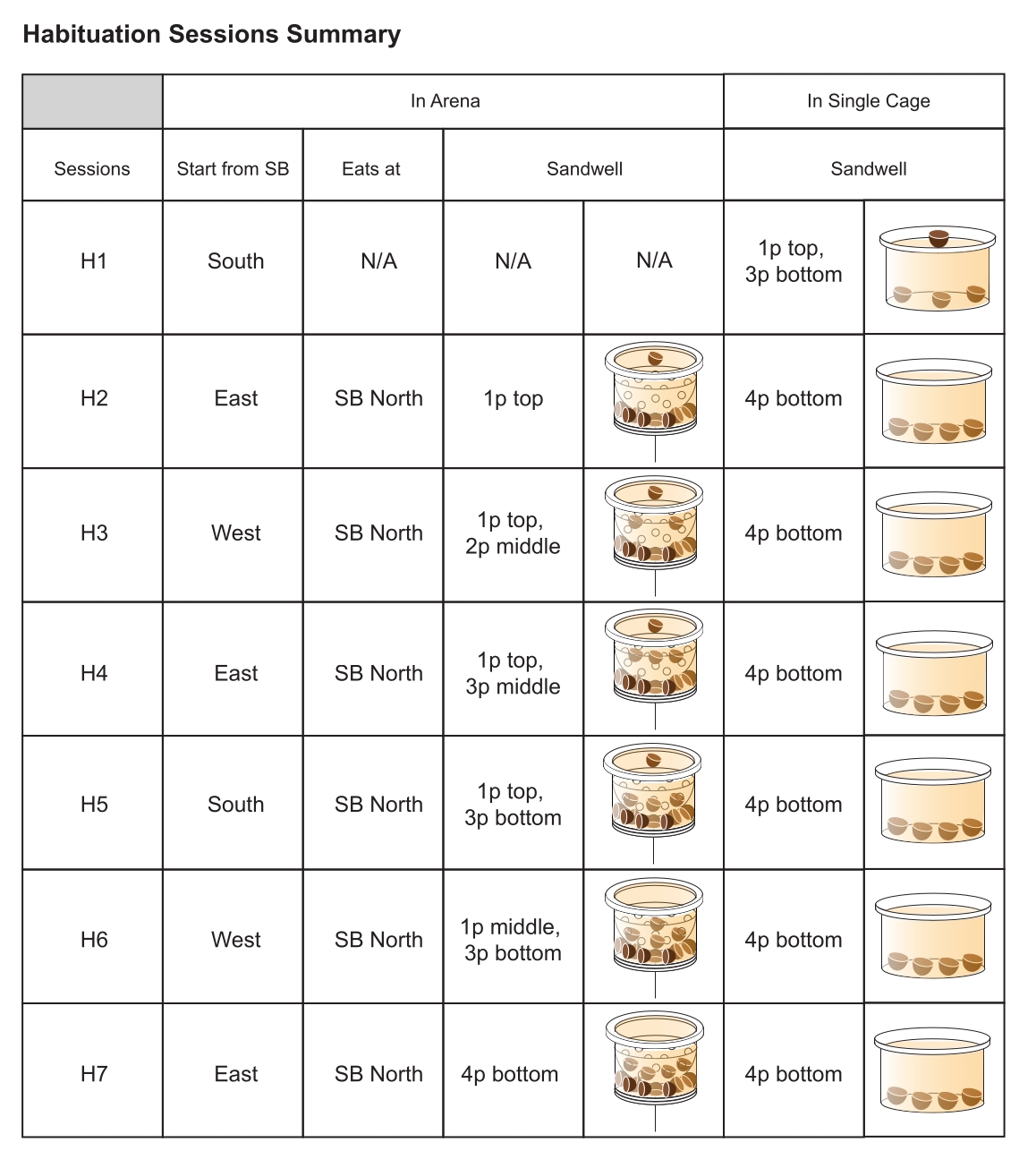
- 砂で満たされた小さな容器を個々のケージに入れます。最初のセッション(つまり、H1)では、砂の表面のすぐ下に0.5 gの食品ペレットを3つ追加し、その上に1つの食品ペレットを置きます。その後、4つのペレットすべてを表面の下に置きます(図5)。
- 各ラットを1つの砂井戸のある個々のケージに入れ、各ラットの砂井戸をリフレッシュします。ネズミが砂井戸から4つのペレットすべてを掘って成功裏に回収するまで、ラットを個々のケージに入れておきます。
- アフォーチュエーション セッション 1
- ラットをスタートボックスの1つ(例:南)に30秒間置き、ペレット(0.5 g)をホームベース(例:北)の小さなフラットベースのフード用に指定された井戸に入れます。配置された餌のペレットは報酬として機能し、ネズミがホームベースに行って食べるように促します。
- スタートボックスのドアを開きます(例:南)。ネズミがスタートボックスを出てアリーナに入り、この新しい環境を探索し始めたら、ドアを閉めます。
- ネズミが5分以内にスタートボックスを離れない場合は、2つの方法のいずれかで介入します。どちらかは、スタートボックスのドアのすぐ外側に絵筆を持って、ラットがアリーナに入るように促します。ネズミが興味を持ったら、ブラシをアリーナにさらに移動させて、ネズミがそれを追いかけるようにします。ネズミがアリーナに入り、スタートボックスのドアから安全な距離に入ったら、スタートボックスのドアを閉じます。
- または、ラットをスタートボックスから取り出し、スタートボックスのドアを閉じて、ラットが入ったはずのスタートボックスのドアのすぐ外側のアリーナに配置します。ラットがやる気がなく、タスクをうまく実行しない場合(たとえば、スタートボックスを補助せずに放置する、効果的に掘るなど)、ラットの体重を確認し、そのフリーフィーディング重量(%)を計算します。
注:フリーフィーディングウェイトが85%をはるかに超えている場合、ラットは空腹ではないかもしれません。この場合、その1日の総食料手当(G)はさらに制限を必要とする場合があります。 - ネズミがアリーナを10分間探索した後、北のブラックボックスドア(つまり、ホームベース)を開きます。ドアを開けてから5分以内にネズミが入らない場合は、ネズミをアリーナから連れ出し、ノースブラックボックスのドアを閉めて、ネズミをホームベースに置きます。
- ラットがセッションの開始時にホームベースに置かれたペレットを食べ終えた後、ラットをホームケージに戻します。
- アフォーチュエーション・セッション2
- イベントアリーナに、4つのフードペレット(0.5 g /ペレット)すべてが砂の表面下に埋もれた砂井を置きます。この報酬のサンドウェルの場所は、今後セッションごとに変更してください。
注:大きな食物ペレット(0.5g)を持っているため、ラットはそれらを彼らが安全と考える環境(すなわち、暗い環境)に運んでそれらを食べることを好むでしょう22。 - 選択したスタートボックス(つまり、東)のフード用に指定されたフラットベースのウェルに1つのキューペレットを置き、続いてラットを置きます。
- ラットがキューペレットを食べ終えたら、約45秒後にスタートボックスのドアを開けます(例:東)。
- ネズミがアリーナに入り、ドアから安全な距離になったら、スタートボックスのドアを閉めます。ラットがスタートボックスから出てこない場合は、手順3.2.3-3.2.4を参照してください。
- ネズミに砂井戸で最初のペレットを探させます。食料報酬を成功裏に回収するには、アリーナ内にある1つの砂井戸を掘る必要があります。
- ラットが最初のペレットを回収したら、ホームベースのドア(つまり、北)を開きます。その後、ネズミは報酬を食べるためにホームベースを見つけて入る必要があります。ラットがアリーナ内でペレットを食べ始めた場合は、そっとホームベースに戻ってペレットを食べるように誘導します。
注:各ラットはホームベースで食べるように奨励されなければならないので、これは重要です。適切なトレーニングを受けていないと、アリーナに入ったトライアルのスタートボックスに戻って食事をする傾向があります。 - ラットがホームベースで最初のペレットを終えた後、ホームベースを離れてアリーナに再入場し、2番目のペレットを回収します。
- 2番目のペレットを回収したら、ラットに再びホームベースを見つけて、餌の報酬を食べさせます。ネズミがホームベースに入ったら、ノースブラックボックスのドアを閉めます。
- ラットがホームベースで2番目のペレットを食べ終えたら、それをホームベースからそっと取り出し、ラットをホームケージに戻します。
- イベントアリーナに、4つのフードペレット(0.5 g /ペレット)すべてが砂の表面下に埋もれた砂井を置きます。この報酬のサンドウェルの場所は、今後セッションごとに変更してください。
- セッション3-7
- 慣れセッション2(ステップ3.3.1-3.3.9)を5回繰り返し、セッションごとにペレットを砂井戸に深く埋めます(図5)。慣れが終わるまでに、すべてのネズミにアリーナ内に存在する報酬のある砂井戸に素早く走るように促し、利用可能な餌のペレットを連続して集め、それらをホームベースに運んで食べます。

図5:慣れセッションの設計。 左の列から右の列へ:慣れセッション(H1-H7);各セッションで使用されるスタートボックス(例:H1:サウススタートボックス(SB))。ネズミが食べ物の報酬を食べる必要がある場所(つまり、ノースホームベース)。報酬のある砂井戸内のアクセス可能なペレットの位置(書面と図解の両方、p =ペレット)は、各セッションの指定された砂井の場所に配置されます。シングルケージ内のフラットベースの砂井戸内のペレットの位置(書面と図解の両方)は、掘削行動を促進し、砂井戸を掘ることと餌の報酬を受け取ることとの間のラットの関連付けを強化することを目的としています。最後の2つの列は、シングルケージ(アリーナの外側)の砂井戸を示しています。略語:N / A =該当しませんこの 図の拡大版を表示するには、ここをクリックしてください。
{kind=link}
4. 主なトレーニングプロトコル
注:各メイントレーニングセッションは、2回のメモリエンコーディング試行(E1、E2)と、短い遅延時間(~30分)の後、1回のリコール選択試行(C1)で構成されます。すべての試験中、ラットは報酬を得た砂井戸から2つのペレットを連続して回収する必要があります。各ペレットを見つけた後、ラットはこの餌の報酬を食べるためにホームベースを見つけて入る必要があります。正しい(つまり、報酬を得た)砂井の位置は、すべてのラットのセッション間で相殺されます(図5)。
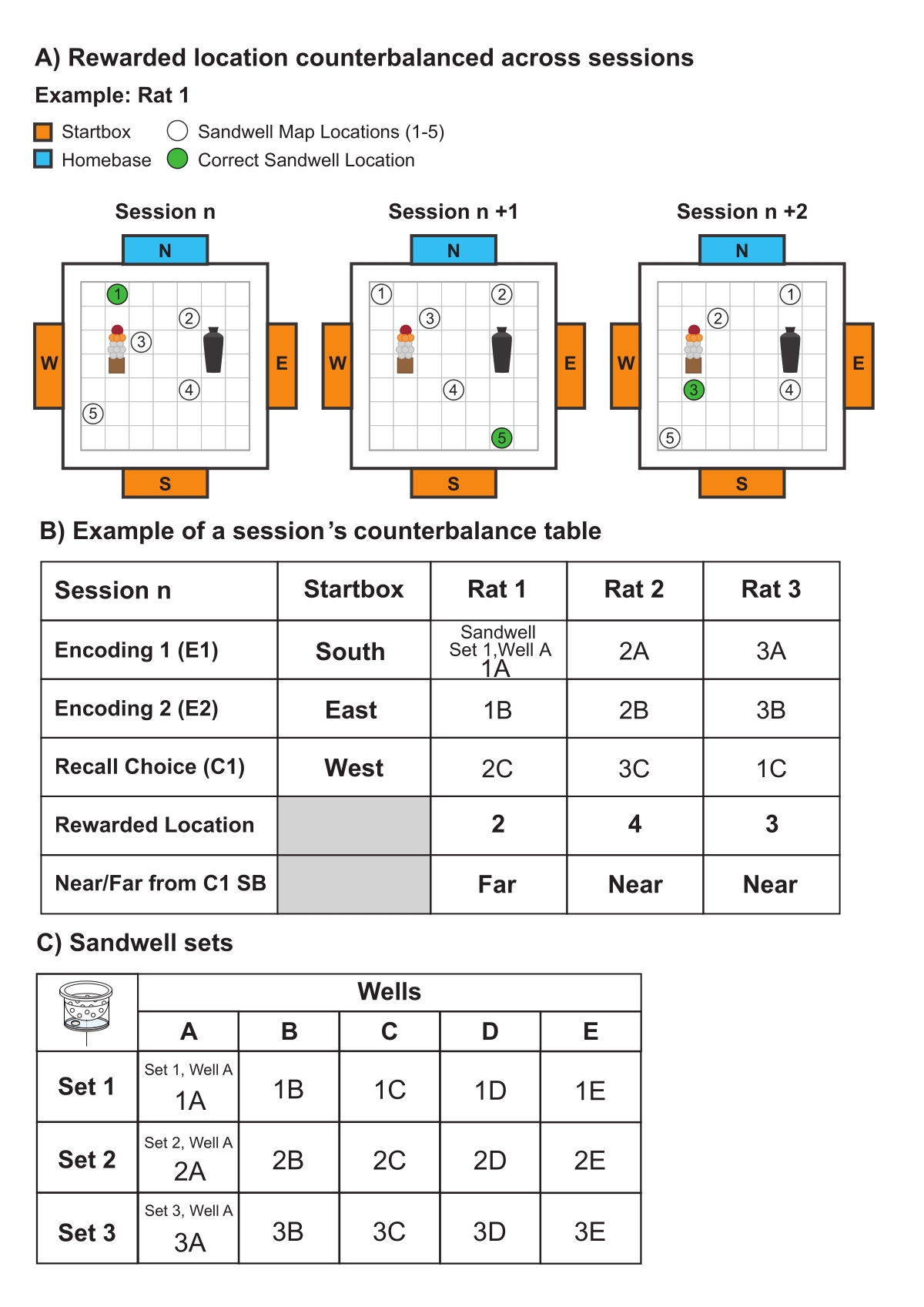
- カウンターバランス対策
- セッション間で使用される砂井の位置の順序とスタートボックスの順序を慎重に相殺します(図6)。各セッションの前に、ロケーションマップを準備します(図6A)。各ラットの正しい砂井の位置を決定しますが、これはセッション間で著しく変化する必要があります(図6B)。カウンターバランスシート(図6B、C)と記録シート(補足図1)を作成します。
- 1セットあたり5つの砂井戸を含む3つの砂井戸セットを作成します(図6C)。各リコール選択試行中にアリーナで 5 つの砂井の位置 (1 つは正解、4 つは不正解) が使用され、各試行で使用される砂井戸を各セッション内で交互に使用できるため、各セットには 5 つの砂井戸が必要です。
- 各セッションでは、ラットの符号化試験用に1つの砂井セットを使用します(図6B、C;エンコーディング1:セット1、井戸A;エンコーディング2:セット1、井戸B)と別の異なる砂井戸セット(図6B、C;リコール選択:セット2、井戸C)のリコール選択試験用。
- 各セッション内では、各ラットの異なるサンドウェルセットの組み合わせを使用し(図6B、C)、セッション間で、各ラットに使用されるサンドウェルセットの組み合わせを交互に使用します。
- エンコードの試行
- 報酬のある砂井戸を、ロケーションマップとカウンターバランスシートに従って正しい場所に置きます(図7)。アリーナ内のキュー位置、中央のタイル、または4つのスタートボックスの真正面にある3つのタイルを砂井の場所として使用しないでください。
- 1つのペレットと続いてラットを、試行1(E1)をエンコードするために指定されたスタートボックス(例:East)に配置します。ペレットはタスクの合図として機能します。試験を開始する前に、ラットがこのキューペレットを食べるのに十分な時間(~30秒)を確保します。
- 画面上の スタート ボタンを押して、社内のビデオキャプチャシステムにトライアルを録画します。
注:(1)研究の透明性(すなわち、各動物のタスクパフォーマンスの生の証拠)、(2)再採点、および(3)将来の参照(すなわち、他のパフォーマンス測定のためのデータを探索し収集すること)のために、ラットの符号化試験の記録を保持することが重要です。 - カスタムコンピュータソフトウェアを使用して、スタートボックスのドアをリモートで開きます(図4B)。
- ネズミがアリーナに入ったら、カスタムコンピューターソフトウェアでタイマーを開始し、スタートボックスのドアを閉じます。
- ラットに200秒を与えて、正しい砂井戸を探し、掘り、最初のペレットを回収します。ラットが正しい砂井戸または200秒後に最初のペレットを見つけていない場合は、砂の下からペレットの1つを取り出して上に置きます。ラットが正しい砂井戸を訪れず、さらに200秒後にこのペレットを回収できない場合は、ブラシを使用して正しい砂井戸に優しく導きます。
- 餌の報酬が見つかったら、ネズミはそれをホームベース(ノースブラックボックスなど)に運び、中に入ったら食べる必要があります。ネズミがホームベースを見つけて入らず、代わりにアリーナ内で最初のペレットを食べることを選択した場合は、すぐにラットをアリーナから取り出してホームベースに置きます。
- ホームベースで最初のペレットを食べた後、ラットをホームベースからアリーナに入れ、正しい砂井戸から2番目のペレットを見つけます。
- 2番目のペレットを回収した後、ラットを見つけてホームベースに入り、それを食べさせます。
- ネズミが安全に中に入ったら、ホームベースのドアを閉め、2番目のペレットを食べるのに十分な時間を与えます。
- カスタムコンピュータソフトウェアでカスタムビデオキャプチャの録画とタイマーを停止します。カスタムビデオキャプチャソフトウェアの画面上の 停止 ボタンを押します。次に、カスタムコンピュータソフトウェアの画面上のタイマーの [停止 ]ボタンをクリックします。
- ラットが食事をしている間、70%エタノール溶液に浸した布でアリーナの床を拭きます。これは、すべての試行の間に行います。
- トライアル 2 (E2) をエンコードするための正しいサンドウェルを準備し、イベント アリーナ内の正しい場所に配置します。
- ホームベースからネズミを取り出し、E2用に指定されたスタートボックス(例:West)に入れます。
注:ネズミはアリーナの静的な視点に頼ることができないか、正しい砂井戸を成功裏に見つけるために以前の経路をたどることができないため、ネズミがタスクを実行するために同種中心の空間ソリューションのみを使用するようにネズミを効果的に奨励するためには、代替スタートボックスの使用が重要です。それどころか、アリーナ内およびアリーナ外の手がかりに注意を向ける必要があり、これにより同類中心の符号化が促進されます。 - 手順4.3.2から4.3.12を繰り返してから、ラットをホームケージに戻します。
- リコール選択試験
注:各ラットの想起選択試行は、2回目の符号化試行(E2)の30〜40分後に実行され、ラットに5つの砂井を含むアリーナを提示します。- 報酬を得た砂井戸をセッションに割り当てられた正しい場所に配置し、報酬を得なかった4つの砂井戸は、セッションと問題のネズミに割り当てられた4つの誤った場所に配置します(図8A)。リコール選択試験の 5 つの砂井の砂井位置マップは、セッションごとに変更され、セッション間で相殺されます。
- 4つのアクセス可能なペレットが入った砂井戸を正しい場所に置きます。さらに4つの砂井戸(それぞれが報酬がなく、アクセス可能なセクションにペレットが含まれていない)を、セッションの砂井位置マップで設定された間違った場所に配置します。
- キューペレットとラットをリコール選択試験のスタートボックスに入れます(例:南)。この開始位置 (例: C1: West) が、2 つのエンコード試行で使用された場所 (例: E1: East、E2: South) と異なることを確認します。
- 社内のビデオキャプチャシステムを使用してトライアルの録画を開始します。
注:(1)研究の透明性(すなわち、論文の補足資料の一部として提出できる各動物のタスクパフォーマンスの生の証拠)、(2)再採点、および(3)将来の参照(すなわち、他のパフォーマンス測定のためのデータを探索し収集するため)のために、ラットのリコール選択試験の記録を保持することが重要です。 - カスタムコンピュータソフトウェアで、この特定のセッションで使用するサンドウェル(サンドウェルタイマー)に一致するタイマーを選択します(図4B)。
- ラットがキューペレットを食べたら(~30秒)、カスタムコンピューターソフトウェアを使用してドアを開けます。ネズミがスタートボックスを出たら、スタートボックスのドアを閉め、カスタムコンピューターソフトウェアでタイマーを開始します。
- ネズミが砂井戸を掘ったら、画面上の 砂井戸 アイコンをクリックして、各砂井戸を掘った時間を記録します。リコール選択試験が終了するまで、訪れた各砂井戸でのラットの掘削時間を記録し続けます。
- その後、ラットがこの餌の報酬を食べるためにホームベースを見つけて入るのを待ちます。
- リコール選択試行で正しい砂井から2番目のペレットを取得するための符号化試行(ステップ4.2を参照)の場合と同じ手順を使用します。
- 2番目のペレットの検索中に訪れた各砂井戸でのラットの掘削時間をクリックして記録しないでください。ラットが報酬を得た砂井戸を正常に見つけて2番目のペレットを回収する前に、訪れた砂井戸の順序(各砂井戸の場所に割り当てられた番号1〜5を使用)のみを記録します。これには集中力が必要です。

図6:代表的なカウンターバランス(A)ラット(例えば、ラット1)が遭遇した砂井の位置マップと正しい砂井の位置がセッション間でどのように変化するかを示す概略図。(B)1つのセッション(例:セッション1)のカウンターバランステーブルの例。1つのセッション内の各試行に異なるスタートボックスが使用されます(つまり、サウススタートボックス(SB)から開始された試行1(E1)をエンコードします)が、それらの使用順序は各動物で同じでした(例:ラット1-3)。正しい位置(例:位置2、4、3)に使用された砂井戸とそれらに関連するセットは、リコール選択試験中に完全に使用され、各セッションの試行(例:エンコード1、エンコード2、リコール選択)とタスクを実行する動物(例:ラット1〜3)で相殺されました。(C)砂井セットを概説する表は、セッション内およびセッション間で相殺されます。全部で15個の砂井戸と3セット(セット1〜3)の砂井戸があり、それぞれに5つの井戸(A〜E)が含まれています。各ラットは、各エンコーディングおよびリコール選択試行で異なるウェルを使用します。例えば、図6Bで述べたように、ラット1は、符号化試行1でSandwell 1Aを使用し、符号化試行2でSandwell 1Bを使用し、リコール選択試行でSandwell 2Cを使用する。この図の拡大版を表示するには、ここをクリックしてください。
{kind=link}
5.リコールプローブテスト
- リコール選択試行と同じ設定を使用しますが、セッションの以前に報酬を得た正しい砂井の位置を含め、5つの砂井のいずれにもアクセス可能なペレットがない点が異なります(図8A、B)。
注:リコール選択試験と同様に、プローブテスト中は5つの砂井戸すべてが利用可能であり、ラットは選択した任意の砂井戸を自由に掘ることができます。ただし、どの砂井戸にもアクセス可能な食物報酬は含まれていません-代わりに、12個のペレットすべてが各砂井戸のアクセスできないセクションに存在します(図3C)。 - アクセス可能なペレットを含まない5つの砂井戸を、セッションの砂井マップに示されている場所のアリーナに置きます(図8)。
- ネズミをキューペレットでスタートボックスに入れます。同じセッションの 2 つのエンコード試行のいずれでも使用されていない開始位置を使用します。
- カスタムコンピュータソフトウェアのサンドウェルタイマーを、セッションのサンドウェルマップに対応するように設定します(図4B)。カスタムコンピュータソフトウェアで設定されたサンドウェルタイマーが、セッションのサンドウェルマップに正しく対応していることを確認します。
- 社内のビデオキャプチャシステムでプローブトライアルの録画を開始します。
注:(1)研究の透明性(すなわち、論文の補足資料の一部として提出できる各動物のタスクパフォーマンスの生の証拠)、(2)再採点、および(3)将来の参照(すなわち、他のパフォーマンス測定のためのデータを探索し収集すること)のために、ラットのリコールプローブ試験の記録を保持することが重要です。 - ラットがペレットを完成させたら、カスタムコンピューターソフトウェアを使用してリモートでスタートボックスのドアを開けます(図4B)。
- ネズミがアリーナに入り、ドアから安全な距離になったら、スタートボックスのドアを閉じて、カスタムコンピューターソフトウェアでタイマーを開始します。
- 120秒のプローブ試験中に訪れた各砂井戸へのラットの掘削時間と潜時を記録するには、訪問した各砂井をクリックし、ラットが掘り続ける限り保持します。この120秒のカウントダウンは、ネズミが最初の砂井戸を掘ったときに始まります。
- 60秒と120秒のタイムマークでカスタムコンピュータソフトウェアのスクリーンショットを撮って、60秒と120秒での掘削時間と遅延を記録します。
- 120秒のプローブ試行が経過した後、記憶の低下を防ぐために、正しいサンドウェル(つまり、エンコード試行における報酬サンドウェルの位置)に3つのペレットを入れます。ラットは、これら3つのペレットのうち2つを回収する必要があります。ペレットが回収されたら、ラットはそれを食べるためにホームベースを見つけて入力する必要があります。
- 120秒のプローブテスト後、カスタムコンピュータソフトウェアの画面上の 停止 ボタンを押します。ファイル名をクリアし、ネズミの待ち時間のみに注意して、報酬が与えられた正しい砂井の場所に置かれた1番目と2番目のペレットを取得します。
注:正しい場所での優先的な掘削は、記憶の指標として使用されます:エンコーディング試行で経験された日常のイベント(つまり、セッションの正しい砂井の位置に遭遇した)の良好な記憶は、間違った場所での掘削に費やされた平均時間よりも正しい場所での掘削に費やされた時間よりも長い時間によって示されます。 - トレーニングの開始時にリコールプローブテストをスケジュールして、パフォーマンスがチャンスレベルにあるかどうかを確認します。その後、特定の間隔(例えば、6回目のセッションごと)でプローブテストをスケジュールするか、またはラットが安定したタスクパフォーマンスに達したときにのみスケジュールします:プローブテストを保証するためには、3回の連続したセッションで平均パフォーマンス指数(%)が60%以上である必要があります。平均パフォーマンス指標は、ステップ7.3.1で定義します。
6. 非符号化制御試験
注:非エンコード試行は、ラットが正しい砂井の位置の記憶ではなく、嗅覚アーティファクトを使用してタスクを実行しているかどうかを判断するために使用される制御手段です。名前が示すように、「非エンコード制御テスト」とは、リコール選択試行の前にエンコード試行が実行されないことを意味します。リコール選択試験のみが実施されます。日常の記憶イベントの位置をエンコードすることが許可されていないため、選択試行でのラットのパフォーマンスは偶然のレベルになることが期待されます。これが当てはまらず、ラットが非符号化制御試験で良好な成績を収める場合、砂井戸、およびそれらのアクセス可能なコンパートメントとアクセス不可能なコンパートメントの再設計が必要になる可能性があります。
- セクション 4.3 (手順 4.3.1 から 4.3.10) の説明に従って、リコール選択試行を実行します。
7. パフォーマンス測定
注:いくつかのパラメータが測定され、 補足図1 にサンプルデータシートが示されています。
- 砂井戸の選択
注:選択は、リコール選択およびリコールプローブ試験中に、ラットが掘り込む砂井戸の数として定義され、正しい砂井戸までです。選択可能な最大値は 5 で、合計で 5 つの砂井があります。- 実験の各試行(想起選択試行および想起プローブ試験)中に、ラットが行った選択の数を決定します:前足を砂の井戸の上に置くか、砂の井戸の中に置くか。ネズミが通り過ぎたり、単に砂井戸の近くで素早く匂いを嗅いだりした場合、これは選択とは見なされません。
- まれに、ラットが選択をしたかどうかをビデオモニターから判断するのが難しい場合(上記で定義)、試験の最後に、掘った痕跡があるかどうか、つまり砂が砂井戸の周りに移動しているかどうかを確認します。わずかであっても、掘り起こした形跡がある場合は、これを選択肢と考えてください。砂井戸で一時停止し、掘らないことは単なる訪問と見なされ、選択として数えられるべきではありません。
- エラー
注:エラーは、ネズミが正しい砂井戸を見つける前に訪れる誤った砂井戸(報酬なし)の数として定義されます。選択は、リコール選択およびリコールプローブの試行中に、ラットが正しい砂井戸まで掘り込む砂井戸の数として定義されます。合計で5つの砂井があるため、エラーの最大数は4つです。- 次の式を使用して誤差を計算します。
エラー = (選択肢 - 1) - ネズミが間違った砂井戸を再訪した場合、合計で5つの砂井戸があるため、エラーの最大数は4であるため、これを別のエラーとしてカウントしないでください。
- 次の式を使用して誤差を計算します。
- パフォーマンス指数(PI)
注:パフォーマンスインデックスは、ラットがリコール選択試行で正しい砂井を見つける前に発生したエラーの数として定義されます。5つの砂井戸では、最大4つのエラーが発生する可能性があります。したがって、5つの砂井の確率レベルは2つの誤差(つまり、50%)です。- パフォーマンス指数は、次の式を使用して計算します。

- ネズミが間違った砂井戸を再訪した場合、合計で5つの砂井戸があるため、エラーの最大数は4であるため、これを別のエラーとしてカウントしないでください。
- パフォーマンス指数は、次の式を使用して計算します。
- 潜在
注:レイテンシーは、正しい砂井戸で掘削が開始されるまでの経過時間として定義されます。- ラットがスタートボックスを離れてから正しい砂井戸に到達するまでのレイテンシを測定します。カスタムコンピュータソフトウェアを使用して遅延を監視および記録します。
- 掘り時間
- リコールプローブ試行で、各砂井戸(正しい砂井戸と間違った砂井戸の両方)でのラットの掘削時間を測定します。
注:日常のイベントに対する良好な記憶は、ラットが正しい砂井戸を掘ること(n = 1)によって定義され、120秒プローブ試行の大きな割合で、間違った砂井戸を掘るのに費やす平均時間(n = 4)よりも高くなります。 - 次の式を使用して、正しいものと正しくないものを計算します。


- リコールプローブ試行で、各砂井戸(正しい砂井戸と間違った砂井戸の両方)でのラットの掘削時間を測定します。
8. 意図しないバイアスの回避
注:この日常的な記憶タスクの再現性と信頼性を確保するために、プロトコル全体で次の制御手段が実装されています。
- セッション間で砂井の位置を釣り合わせます。これにより、イベントアリーナの特定の側面に報酬の偏りが生じるのを防ぐことができます。
- 砂井セットと、正しい位置で使用されるこれらのセット内の砂井戸を、セッション間および各セッション内のラット間で釣り合わせます。これにより、ラットは、前のラットの試験から残っている残留臭気の試験を追跡しようとするのを思いとどまらせます。
- すべてのトライアルの合間に、70%エタノール溶液に浸した布でイベントアリーナの床を拭きます。これにより、前の RAT(s) のパスが後続のタスクのパフォーマンスに影響を与えるのを防ぐことができます。
Access restricted. Please log in or start a trial to view this content.
結果
この安定したホームベースプロトコルは、同種中心表現を使用してラットがこの日常的な記憶課題を学習するように成功裏に訓練するために使用されてきました。このプロトコルには、2つの重要な要素があります。まず、動物はセッション内およびセッション間で異なるブラックボックス(東、南、西など)から開始します(図7A)。セッションご?...
Access restricted. Please log in or start a trial to view this content.
ディスカッション
人間は、日常生活の 1 つのイベントを自動的にエンコードします。私たちはすぐに思い出す出来事もあれば、忘れてしまう出来事もあります。上述のエピソードライクな日常記憶プロトコルは、げっ歯類のこのタイプの記憶(エピソード記憶)を調査したい研究者に堅牢な方法を提供します。このタスクには、定義された場所から食品ペレットを見つけて回収するとい?...
Access restricted. Please log in or start a trial to view this content.
開示事項
著者には、開示すべき利益相反はありません。
謝辞
この研究は、Medical Research Council Programme Grants、European Research Council(ERC-2010-AdG-268800-NEUROSCHEMA)、Wellcome Trust Advanced Investigator Grant(207481/Z/17/Z)の支援を受けた。
Access restricted. Please log in or start a trial to view this content.
資料
| Name | Company | Catalog Number | Comments |
| Camera | CCTVFirst | N/A | |
| Event Arena | University of Edinburgh (designed and built in house) | University of Edinburgh (designed and built in house) | Event arena for everyday memory task |
| Lister-hooded rats | Charles River UK | 603 | |
| Multitimer Labview | University of Edinburgh (designed and built in house) | University of Edinburgh (designed and built in house) | |
| Pneumatics, frames, screws of event arena | RS Components Ltd. | University of Edinburgh (P. Spooner) | Tools for building event arena |
| Sandwells | Adam Plastics (http://www.adamplastics.co.uk) | University of Edinburgh (P. Spooner) | Sandwells for arena |
| Startboxes | Adam Plastics (http://www.adamplastics.co.uk) | University of Edinburgh (P. Spooner) | |
| Video recording | Windows 10 computers with OBS software, Blackmagic Decklink Mini Recorder cards | N/A |
参考文献
- Pavlov, I. P. The work of digestive glands. Bristol Medico-Chirurgical Journal. 21 (80), 158-159 (1903).
- Thorndike, E. L. Animal intelligence: An experimental study of the associative processes in animals. Psychological Review. 5 (5), 551-553 (1898).
- Dickinson, A., Mackintosh, N. J. Reinforcer specificity in the enhancement of conditioning by posttrial surprise. Journal of Experimental Psychology: Animal Behaviour Processes. 5 (2), 162-177 (1979).
- Tolman, E. C., Gleitman, H. Studies in spatial learning: VII. Place and response learning under different degrees of motivation. Journal of Experimental Psychology. 39 (5), 653-659 (1949).
- Olton, D. S., Samuelson, R. J., Wagner, A. R. Remembrance of places passed: Spatial memory in rats. Journal of Experimental Psychology: Animal Behaviour Processes. 2 (2), 97-116 (1976).
- Barnes, C. A. Memory deficits associated with senescence: A neurophysiological and behavioral study in the rat. Journal of Comparative and Physiological Psychology. 93 (1), 74-104 (1979).
- Morris, R. G. M., Garrud, P., Rawlins, J. N. P., O'Keefe, J. Place navigation impaired in rats with hippocampal lesions. Nature. 297 (5868), 681-683 (1982).
- Kesner, R. P., Farnsworth, G., Kametani, H. Role of parietal cortex and hippocampus in representing spatial information. Cerebral Cortex. 1 (5), 367-373 (1991).
- Ennaceur, A., Delacour, J. A new one-trial test for neurobiological studies of memory in rats. 1: Behavioural data. Behavioural Brain Research. 31 (1), 47-59 (1988).
- Ennaceur, A., Neave, N., Aggleton, J. P. Spontaneous object recognition and object location memory in rats: the effects of lesions in the cingulate cortices, the medial prefrontal cortex, the cingulum bundle and the fornix. Experimental Brain Research. 113 (3), 509-519 (1997).
- Day, M., Langston, R. F., Morris, R. G. M. Glutamate-receptor-mediated encoding and retrieval of paired-associate learning. Nature. 424 (6945), 205-209 (2003).
- Tse, D., et al. Schemas and memory consolidation. Science (American Association for the Advancement of Science). 316 (5821), 76-82 (2007).
- Bethus, I., Tse, D., Morris, R. G. M. Dopamine and memory: modulation of the persistence of memory for novel hippocampal NMDA receptor-dependent paired associates. The Journal of Neuroscience. 30 (5), 1610-1618 (2010).
- Bast, T., da Silva, B. M., Morris, R. G. M. Distinct contributions of hippocampal NMDA and AMPA receptors to encoding and retrieval of one-trial place memory. The Journal of Neuroscience. 25 (25), 5845-5856 (2005).
- Wang, S. -H., Redondo, R. L., Morris, R. G. M. of synaptic tagging and capture to the persistence of long-term potentiation and everyday spatial memory. Proceeding of the National Academy of Sciences. 107 (45), 19537-19542 (2010).
- Takeuchi, T., et al. Locus coeruleus and dopaminergic consolidation of everyday memory. Nature. 537 (7620), 357-362 (2016).
- Nonaka, M., et al. Everyday memory: towards a translationally effective method of modelling the encoding, forgetting and enhancement of memory. The European Journal of Neuroscience. 46 (4), 1937-1953 (2017).
- Broadbent, N., et al. A stable home-base promotes allocentric memory representations of episodic-like everyday spatial memory. The European Journal of Neuroscience. 51 (7), 1539-1558 (2020).
- Steele, R. J., Morris, R. G. M. Delay-dependent impairment of a matching-to-place task with chronic and intrahippocampal infusion of NMDA-antagonist D-AP5. Hippocampus. 9 (2), 118-136 (1999).
- Whishaw, I. Q., Coles, B. L. K., Bellerive, C. H. M. Food carrying: a new method for naturalistic studies of spontaneous and forced alternation. Journal of Neuroscience Methods. 61 (1), 139-143 (1995).
- Morris, R. G. M. Spatial localization does not require the presence of local cues. Learning and Motivation. 12 (2), 239-260 (1981).
- Whishaw, I. Q., Nicholson, L., Oddie, S. D. Food-pellet size directs hoarding in rats. Bulletin of the Psychonomic Society. 27 (1), 57-59 (1989).
- Dix, S. L., Aggleton, J. P. Extending the spontaneous preference test of recognition: Evidence of object-location and object-context recognition. Behavioural Brain Research. 99 (2), 191-200 (1999).
- Langston, R. F., Wood, E. R. Associative recognition and the hippocampus: differential effects of hippocampal lesions on object-place, object-context and object-place-context memory. Hippocampus. 20 (10), 1139-1153 (2010).
Access restricted. Please log in or start a trial to view this content.
転載および許可
このJoVE論文のテキスト又は図を再利用するための許可を申請します
許可を申請さらに記事を探す
This article has been published
Video Coming Soon
Copyright © 2023 MyJoVE Corporation. All rights reserved