
Method Article
基于质谱的蛋白质组学分析, 利用 OpenProt 数据库揭开从非规范开放阅读框架翻译的新蛋白质
摘要
OpenProt 是一个可自由访问的数据库, 它实施了真核细胞基因组的多聚模型。在这里, 我们提出了一个在询问质谱数据集时使用 OpenProt 数据库的协议。利用 OpenProt 数据库分析蛋白质组学实验, 可以发现新的和以前无法检测到的蛋白质。
摘要
基因组注释是当今蛋白质组学研究的核心, 因为它绘制了蛋白质组景观的轮廓。开放阅读框架 (ORF) 注释的传统模型施加了两个任意标准: 每个编码器的最小长度为100个密码子和单个 ORF。然而, 越来越多的研究报告了来自所谓非编码区域的蛋白质表达, 这对当前基因组注释的准确性提出了挑战。这些新的蛋白质被发现编码要么在非编码 Rna, 5 ' 或 3 ' 未翻译的区域 (Ucs) 的 Mrna, 或重叠已知的编码序列 (CDS) 在一个替代 ORF。OpenProt 是第一个为真核细胞基因组实施多国模型的数据库, 允许对每个转录体的多个 Orf 进行注释。OpenProt 可免费访问, 并提供10个物种的蛋白质序列的自定义下载。利用 OpenProt 数据库进行蛋白质组学实验, 可以发现新的蛋白质, 并突出真核细胞基因的多因素性质。OpenProt 数据库 (所有预测的蛋白质) 的大小是巨大的, 需要在分析中加以考虑。但是, 通过适当的错误发现率 (FDR) 设置或使用受限制的 OpenProt 数据库, 用户将获得更逼真的蛋白质组景观视图。总体而言, OpenProt 是一个免费可用的工具, 将促进蛋白质组的发现。
引言
在过去的几十年里, 基于质谱 (ms-) 的蛋白质组学已成为破译真核细胞 1,2,3, 4,5的蛋白质组的黄金技术。此方法依赖于当前的基因组注释来生成一个参考蛋白质序列数据库, 该数据库概述了可能性的范围6, 7,8.但是, 基因组注释包含 orf 注释的任意标准, 例如每个转录条 9、10的最小长度为100个密码子和一个 orf。越来越多的研究对目前的注释模型提出了挑战, 并报告了在真核细胞基因组 8、11、12、13中发现的未注释功能 orf。 14岁这些新的蛋白质被发现编码在据称非编码 Rna, 在 5 ' 或 3 ' 未翻译的区域 (UTR) 的 mrna, 或重叠的规范编码序列 (cCDS) 在一个替代的框架。尽管这些发现大多是偶然的, 但它们证明了当前基因组注释的警示和真核基因的多国性质8。
在这里, 我们重点介绍了 OpenProt 数据库在基于 ms 的蛋白质组学中的应用。OpenProt 是第一个保存真核细胞转录多核注释模型的数据库。客房 www.openprot.org15可免费使用。这些预测的 Orf 中有一部分是随机的和非功能性的, 这就是为什么 OpenProt 累积实验和功能证据以增加信心的原因。实验证据包括蛋白质表达 (由 ms) 和翻译证据 (通过核糖体分析)15。功能证据包括蛋白质正畸 (类似偏执狂的方法) 和功能域预测15。
OpenProt 提供了下载多个数据库的可能性, 从只包含支持良好的蛋白质到定制数据库。在这里, 我们将介绍一个用于 OpenProt 数据库的管道, 并将提供有关考虑实验目的的数据库选择的见解。这里介绍的蛋白质组学分析管道是由 galaxy 框架支持的, 因为它是开放访问和易于使用的, 但数据库可以与任何工作流16、17、18 一起使用。我们还将介绍如何利用 OpenProt 网站收集有关 ms 检测到的新蛋白质的进一步信息. 利用 OpenProt 数据库将提供更详尽的蛋白质组学视图, 并将促进蛋白质组学和生物标志物的发现。比目前的方法更系统的方法。
该协议突出了 OpenProt 数据库15在询问 ms 数据集时的使用情况;它不会审查实验本身的设计, 实验已经在其他地方彻底审查了20、21、22.为了保持完全的开源, 该协议是免费提供的 (补充材料 s1-s4)。为了便于阅读, 在 Opopenprot 和本协议中使用的所有术语都在表 1中定义。
研究方案
1. OpenProt 数据库下载
注: 例如, 还可以获取基于 RNA-seq 数据的自定义数据库, 并在本协议的第二部分详细介绍了该过程。如果需要自定义数据库, 请跳到下一节。
- 转到 OpenProt 网站: www.openprot.org 并使用首页菜单中的链接打开 "下载" 页面。
- 根据所分析的实验数据, 点击感兴趣的物种。
- 点击所需的蛋白质类型。
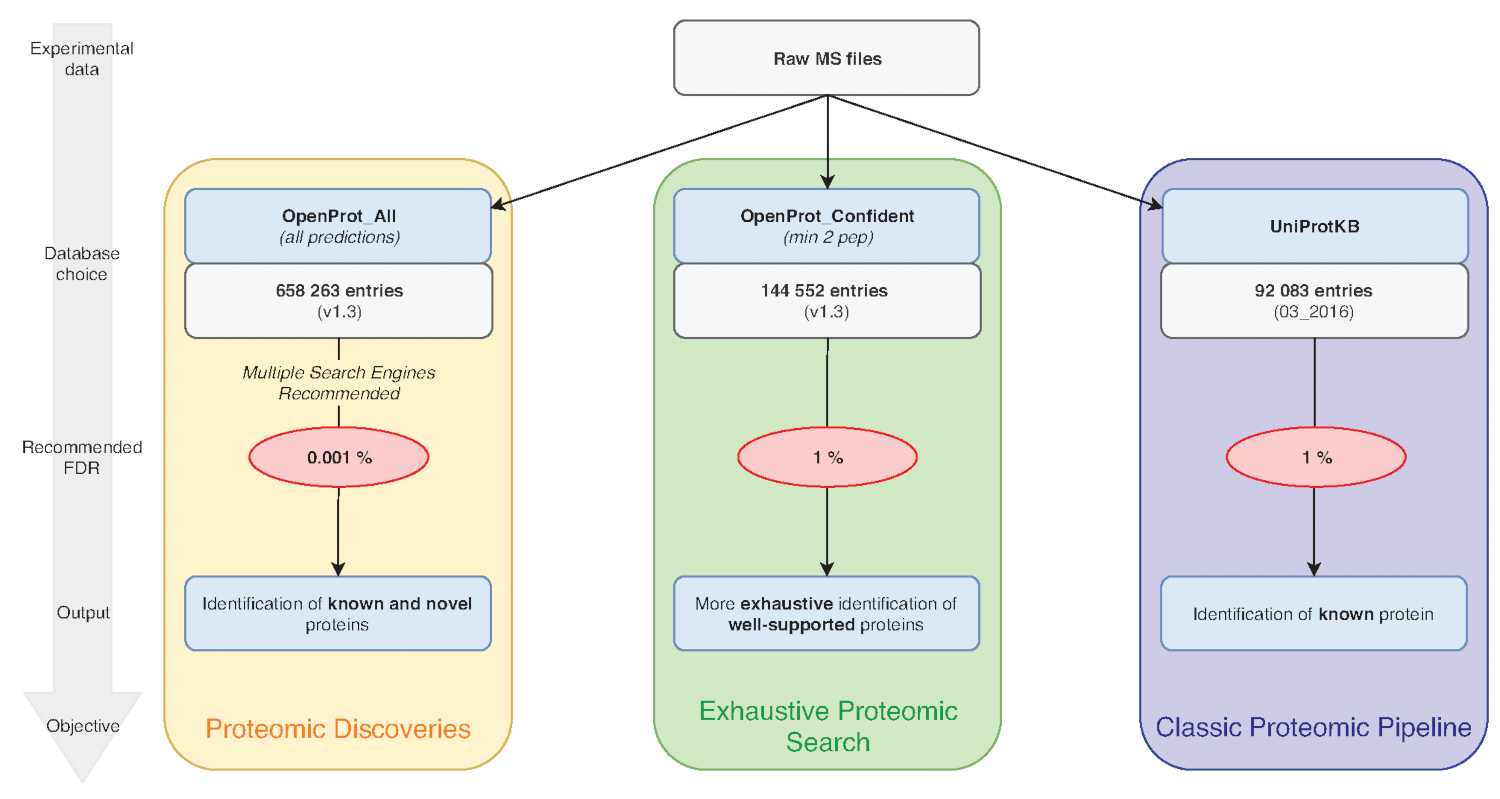
注: OpenProt 提供三种分类: RefProt、等异种和 AltProt。如图 1所示, 此参数将根据研究目标而有所不同。- 单独点击Refprot生成仅包含已知蛋白质的文件。
- 单击altprot 和等位基因生成仅包含新蛋白质的文件--已知蛋白质的新异型 (等位表) 或由替代 orf (AltProt) 编码的文件。请注意, OpenProt 强制至少30个密码子 15个 orf长度。
- 点击altprots、等位表和 RefProts生成包含 openprot 数据库中所有蛋白质类型的文件-已知和新颖的蛋白质。
- 如果可用, 请单击从中绘制蛋白质序列的注释。
注: OpenProt 通过组合多个注释, 提供了更详尽的蛋白质组景观。转录组注释的重叠最小;因此, 所选注释会对可视化的蛋白质组分布 15、23 产生重大影响。 - 点击蛋白质考虑所需的支持证据的水平。如图 1所示, 此参数将根据研究目标而有所不同。
- 点击至少两个独特的肽检测到, 以生成文件只包含最自信的蛋白质。
注: 两个独特的肽的标准目前被认为是蛋白质组学中蛋白质表达的黄金标准。如果实验目的是检测已知和支持良好的蛋白质, 则建议使用此参数。 - 单击检测到的至少一个独特的肽, 生成包含蛋白质的文件, 这些文件在 openprot 重新分析的质谱实验中至少看到过一次。
注: 这允许考虑较短的 AltProts 长度和概率, 其中一些可能包含一个独特的色氨肽8,11。 - 单击所有预测生成包含所有 openprot 预测的文件。
注: 只有当实验目的是发现新的蛋白质时, 才建议使用此设置 (图 1)。随后搜索空间的大幅增加需要一个经过调整的分析管道, 如下文7、15 所述。
- 点击至少两个独特的肽检测到, 以生成文件只包含最自信的蛋白质。
- 单击要下载的所需文件格式。对于蛋白质组分析, 请选择 Fasta (蛋白质) 文件。自述文件包含有关文件格式的所有必要信息。
2. 自定义 OpenProt 数据库下载
注: 本节详细介绍如何获取自定义数据库。如果不需要自定义数据库, 请跳到下一节。
- 转到 OpenProt 网站 (www.openprot.org), 然后使用首页菜单中的链接打开 "搜索" 页面。
- 根据所分析的实验数据, 点击感兴趣的物种。
- 输入感兴趣的基因或成绩单列表。
- 使用基因列表时, 请在"基因查询" 框中输入。
- 使用成绩单列表时, 请在 "成绩单查询" 框中输入。
- 勾选适用于所需数据库的任何框。
- 不要点击任何框, 以获取包含 OpenProt 支持的所有类型的蛋白质的表: RefProt、等异种和 AltProts。
- 单击 "仅显示具有实验证据的蛋白质", 以获得包含 ms 和/或已从核糖体中收集翻译证据的所有类型的蛋白质 (ref公茨、iso窗体和 AltProts) 的表分析数据。
- 同样, 单击 "仅显示由 ms 检测到的蛋白质 " 或 "仅显示核糖体分析检测到的蛋白质", 以获取包含由 ms 或核糖体分析分别至少检测到一次的所有类型的蛋白质的表。
- 单击 "仅显示 AltProts " 或"仅显示异形" 以获取分别包含 altprots 或仅包含等形式的表。
- 单击"仅显示 AltProts " 和"仅显示等位表" 以获取包含这两种类型蛋白质的表。
注: 筛选器的所有组合都是可能的。
- 设置完所有所需参数后, 单击 "搜索"。表输出将显示在搜索查询字段的下方。
- 点击输出表右上角的"下载 Fasta " 按钮。这将生成一个 Fasta 文件, 其中包含从查询的基因或转录列表中产生的所有蛋白质。
- 请注意, 出于计算原因, OpenProt 一次最多可容纳 2, 000个元素 (基因或文字记录)。如果列表高于该限制, 则可以生成多个 fasta, 然后连接 (详见下文);或简单地下载整个 OpenProt 数据库, 并根据需要筛选获得的文件。
- 将整个基因或记录列表输入 2, 000个或更少条目的子列表。对于每个子列表, 请按上述下载 Fasta 文件 (步骤3.3 至 3.6)。
- 登录到欧洲 Galaxy 实例 (或任何其他有蛋白质组学工具的实例), https://usegalaxy.eu/。
- 通过点击屏幕左侧的上传徽标, 创建新的历史记录并导入所有下载的 OpenProt 数据库 (每个子列表中的基因或文字记录一个)。
- 使用 GalaxyP 开发人员开发的Fasta 合并文件和筛选器唯一序列工具 (https://github.com/galaxyproteomics/)。选择 "合并所有 Fasta " 选项并输入所有导入的 openprot 数据库。
注: 可以使用屏幕左侧的查询框搜索每个工具 - 选择加入选项以评估序列的统一并复制 openprot 标识符分析规则 (> (. *)\), 然后单击 "执行"。
- 请注意, 所有文件都已连接到一个唯一的 Fasta 文件中, 现在没有冗余, 现在会出现在屏幕右侧的历史记录面板中。这构成了工作数据库。
3. 数据库处理
注: 从现在开始, 将使用 Galaxy 平台, 但同样的原则可以应用于其他蛋白质组学软件。
- 登录到欧洲 Galaxy 实例 (或任何其他有蛋白质组学工具的实例), https://usegalaxy.eu/。
- 通过单击屏幕左侧的上传徽标, 创建新的历史记录并导入下载的 OpenProt 数据库。
- 转到工作流页面, 然后通过单击中间面板左侧的上载徽标导入数据库处理工作流 (补充材料 s1)。
- 单击"运行工作流" , 然后选择导入的 openprot 数据库作为输入。
注: 此工作流将把协商存储库追加到 OpenProt 快点, 并生成诱饵序列 (反向序列)24。如果需要洗牌诱饵列表, 可以通过在解码数据库工具上更改此参数来完成。 - 将获得的 Fasta 文件重命名为有意义的文件。该数据库已准备好用于蛋白质组学分析。
4. 质谱文件的制备
注: Galaxy 实例上提供的大多数蛋白质组学工具都使用 mzML 格式, 而肽搜索引擎更喜欢质心模式下的数据。
- 从蛋白质向导套件中打开免费可用的 Ms转换工具, 并上传要分析的数据文件25。
- 选择输出的目录和所需的 mzML 文件格式。
- 在 MS1 和 MS2 级别上使用基于小波的算法 (CWT) 设置峰值拾取滤波器, 并启动转换26。
5. 多肽和蛋白质鉴定/定量
注: 管道的这一部分使用 OpenMS 套件中的工具, 这是一个多功能且易于使用的框架18。
- 登录到欧洲 Galaxy 实例 (或任何其他有蛋白质组学工具的实例), https://usegalaxy.eu/。
- 创建新的历史记录, 并使用拖放将以前创建的数据库 (步骤 3.5) 传输到此新历史记录。
- 通过单击屏幕左侧的"上载" 徽标, 导入转换后的 mzML 数据文件 (步骤 4.3)。
- 转到工作流页面, 然后通过单击中间面板左侧的上载徽标导入所需的工作流。
注: MS 实验是基于所需的最终输出设计不同的。这里提供了两种常见的设计工作流: 基于稳定同位素标记 (SIL) 的蛋白质识别和蛋白质定量。然而, galaxy 实例包含许多其他工具, 将支持其他类型的蛋白质组分析27,28。- 对于蛋白质识别设计, 请导入补充材料 S2中提供的工作流程。使用此工作流时, 请不要在转换文件时使用 zlip 压缩 (步骤 4.2)
- 对于基于稳定同位素标记设计的蛋白质定量, 请导入补充材料 S3中提供的工作流程。
- 选择运行工作流并查看不同的参数。
- 选择导入的 mzML 数据文件作为输入, 选择以前创建的数据库 (步骤 3.5) 作为数据库 Fasta 文件。
- 因为工作流使用 X!串联搜索引擎, 导入 X!串联默认配置文件 (在补充材料 S4中提供) 29, 通过单击屏幕左侧的上传徽标。
- 工作流使用多个搜索引擎 (MS-GF + 和 X!串联)。添加其他搜索引擎或选择一个简单的通过添加或删除工作流 30,31中的工具.
注: 建议使用多个搜索引擎, 因为它增加了分析32的敏感性和敏感性。 - 为了在使用整个 OpenProt 数据库时考虑到大小的大幅增加, 请使用严格的 FDR15。默认情况下, 提供的工作流设置为 0.001% FDR, 足以用于整个 OpenProt 数据库的使用。对于其他数据库, 可以将其编辑为任何所需的值。
注: 根据所使用的质谱仪和实验协议 (前体离子和碎片误差、固定和可变修饰、使用过的酶等), 一定要调整不同工具的参数。
- (可选) 通过单击历史记录面板中选择的步骤, 然后单击下面显示的"保存" 徽标, 为存储或质量控制分析工作流的每个步骤下载输出。
6. 质量控制
注: 由于基于 ms 的蛋白质组学是一个复杂过程的结果, 在这个过程中, 每个步骤都需要进行优化以产生可重现的结果, 因此质量控制是工作流33中的一个必要过程。
- 几个指标是常见的性能基准, 如多谱匹配 (PSM) 的数量、已识别的肽和蛋白质的数量。在 IDFilter 输出上运行"文件信息" 工具 ( 如图 2中的绿色所示) 以提供此类指标。
- 虽然不是适用于每一个识别, 特别是对于大型数据集, 新的蛋白质报告应始终仔细评估。检测蛋白质分数、序列覆盖率和支持这一发现的光谱至关重要。使用 OpenMS 框架中的 Topview 工具来执行此操作;它是免费提供的, 并有充分记录18,34,35。
7. OpenProt 数据库挖掘
注: 一旦对 OpenProt 预测的一种新蛋白质 (从 AltProts 的 ip _ 开始, 对于新的等形式的 Ii _) 进行了可靠的识别, 就可以从 OpenProt 网站15中收集到更多的生物信息。
- 转到 OpenProt 网站: www.openprot.org 并使用首页菜单中的链接打开 "搜索" 页面。
- 单击感兴趣的物种 (与识别蛋白质的物种相同), 然后在"蛋白质查询" 框中输入蛋白质加入编号。
- 点击搜索, 将出现一个表格, 其中包含被查询蛋白质的基本信息。该表的特点是: 蛋白质长度 (氨基酸)、分子量 (kDa) 和等电点、ms 或核糖体分析 (翻译证据、TE) 的实验证据以及预测域和蛋白质等功能预测(跨越 OpenProt, v1.3 支持的10个物种)。该表还包含有关相关基因和转录以及转录单干中蛋白质定位的信息。
- 点击"详细信息"链接以收集更多信息。新打开的页面包含一个以查询蛋白质为中心的基因组浏览器, 以及诸如基因组和转录坐标以及科扎克或高效翻译起始位点 (TIS) 主题 36的存在等信息, 37岁
- 点击信息选项卡中的蛋白质或dna链接, 分别获取蛋白质或 dna 序列。
- 浏览有关 MS 证据、核糖体特征分析检测、保护和识别蛋白质域的详细信息, 方法是点击顶部选项卡15。
结果
上述工作流应用于提请使用的用作存储库38、39上的 ms 数据集。最初的研究开发了一种方法 (Imippro), 使用稳定的同位素标记的氨基酸在细胞培养 (SIAC), 以消除假阳性从亲和力纯化 MS (AP-MS) 实验38。简而言之, AP-MS 实验包括使用珠子结合抗体获取感兴趣的蛋白质 (诱饵) 及其相互作用器 (preys)。然后对收集到的蛋白质进行消化, 并为 MS 做好准备。在原始研究和 PRIDE 存储库 (PXD004246) 中介绍了样品制备方法和仪器设置。在这些实验中, 一个挑战是假阳性的丰富, 特别是从与珠子结合的蛋白质, 但不是诱饵。在这里, 我们用 SIAC 生成了真正的猎物和假阳性之间不同的同位素比率: 3个控制样本 (无诱饵) 在轻介质中培养, 1个样本表示在轻介质中培养的诱饵, 1个样本表示在重介质中培养的诱饵, 共用珠子和进一步的质谱分析进行处理。有了这样的设计, 与珠子结合的非特定蛋白质的重光比将为 1:4;当真正的前置将有 1:1 38 的比率。
我们使用 OpenProt 数据库重新分析了他们的 AP-MS 数据;诱饵包括三种内源性蛋白质 (PTPN14、JIP3 和 IQGAP1) 和两种过度表达的蛋白质 (RAF1 和 RNF41)。由于实验使用了 SIAC, 使用了用于蛋白质定量的 galaxy 工作流程 (补充材料 S3,图 2)。工作流使用整个 OpenProt 数据库 (OpenProt _ all) 或受限制的 OpenProt 数据库 (OpenProt_2pep (仅包括以前至少检测到两个独特肽的蛋白质) 运行。
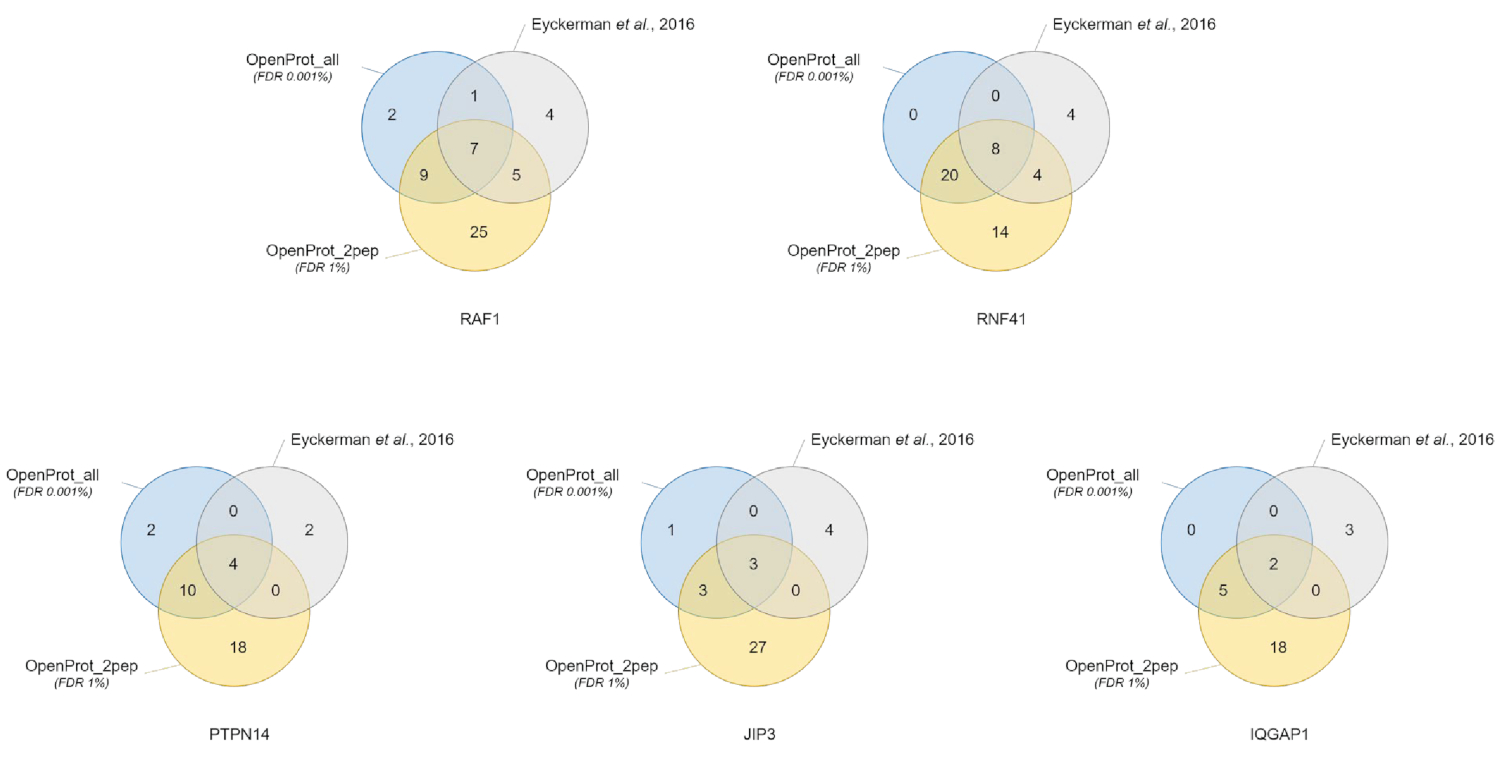
蛋白质鉴定和定量在不同的使用数据库中都是良好和可重现的。如图 3所示, 原始文件中确定的大多数蛋白质也是使用 OpenProt_2pep 或 openprot _ all 数据库识别的 (补充材料 s5中提供了详细清单)。这一结果表明, 此处描述的管道和 OpenProt 数据库能够根据 Unikb Protkb 数据库40进行与当前程序相当的蛋白质识别和定量。然而, 使用 OpenProt 数据库具有独特的优势, 它允许检测新的和以前无法检测到的蛋白质, 正如本案例研究所证明的那样。
利用 OpenProt_2pep 数据库 (所有蛋白质加入以及支持的数量), 在所有数据集中, 在所有数据集中都发现了11种支持良好的蛋白质 (1个等异形体和 10个 AltProts), 这些蛋白质在所有数据集中都有自信的肽多肽, 可在补充材料 S5)。该数据库允许使用传统的 1% FDR, 因为搜索空间的增加保持不变。这11种蛋白质在最初的研究中没有被识别, 因为它们不在数据库中。
使用 OpenProt _ all 数据库, 在所有数据集中发现了29种新的蛋白质 (16个异形和 13个 AltProts), 并使用 opentprot _ all 数据库 (补充材料 S6 中提供了所有蛋白质加入以及支持肽的数量) ).如图 3所示, 推荐的严格的 fdr 并不影响最自信的蛋白质鉴定, 尽管它确实减少了已识别蛋白质的总数。与 OpenProt_2pep 数据库相比, 可以自信地识别出更多的新型蛋白质。所有这些新的蛋白质都不在 OpenProt_2pep 数据库中。这突出了所选数据库在基于 ms 的蛋白质组学中的关键作用。
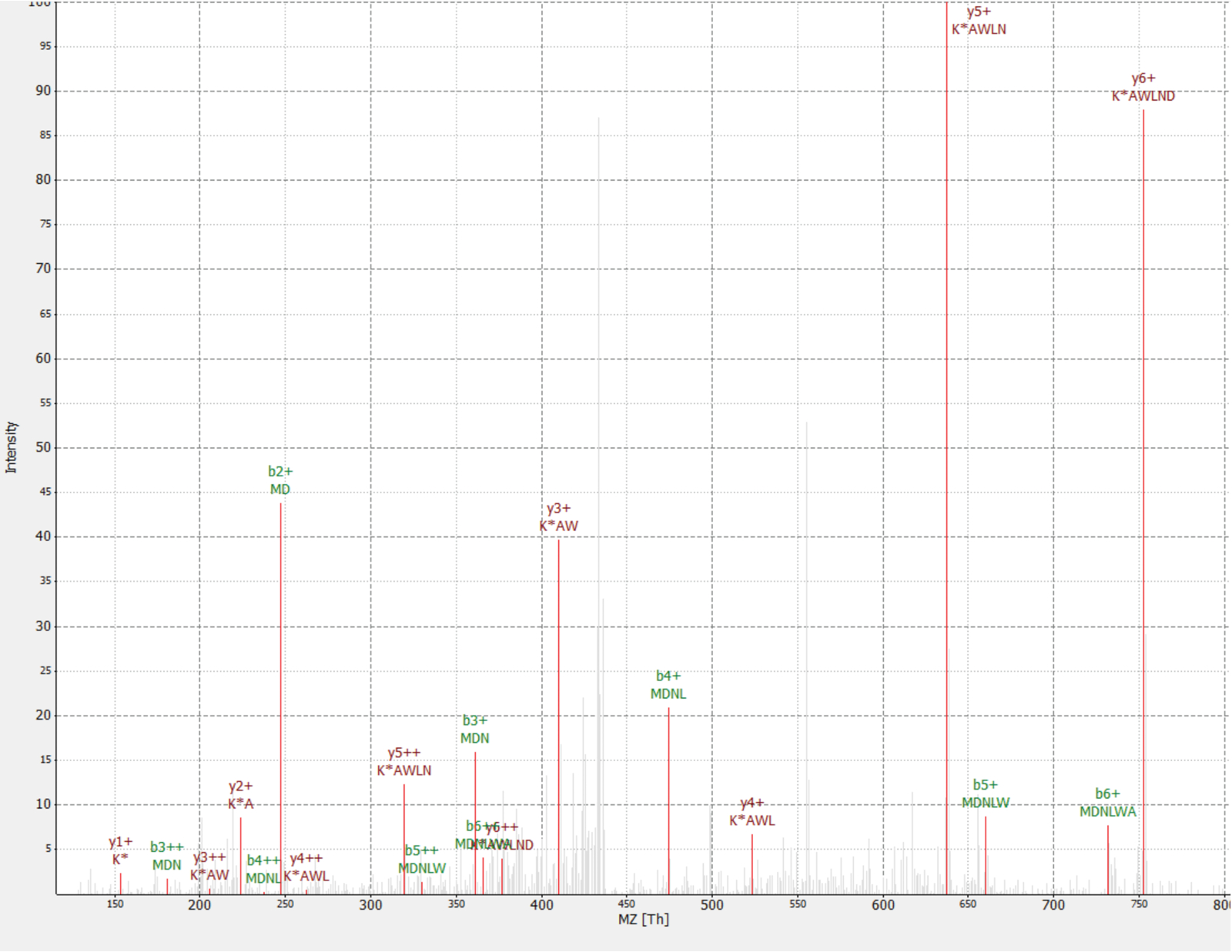
一种新的蛋白质被发现为 RAF1 蛋白 (IP_637643) 的相互作用。使用 OpenProt 网站, 人们可以看到这种蛋白质直到现在还没有被 ms 或核糖体分析检测到 (OpenProt v1.3)。这种蛋白质有46个氨基酸, 在胰蛋白酶消化时只能给予两种独特的肽。在 RAF1 AP-MS 数据集中检测到的肽 (第18部分) 具有良好的质量谱, 如图 4所示, 并显示了 1, 09 的重光比。该蛋白被编码在nanognp1基因中, Nanogn1 基因是Nanognb的伪基因。根据 GTEx 门户网站40, 在多个组织中检测到了记录 (enst00000448444), 该成绩单 (ENST0000044844) 被注释为非编码。该蛋白质包含与 DNA 结合相关的预测功能域 (基因本体论 GO:0003677)41。

图 1: 蛋白质组学分析图的数据库选择.MS 数据的分析, 特别是数据库的选择, 取决于研究目标。三个共同的目标概述了蓝色 (经典的蛋白质组学管道), 绿色 (详尽的蛋白质组学搜索) 和橙色 (蛋白质组学发现)。每个目标都取决于适当的数据库和管道。一个单一的识别工具可用于详尽和经典的蛋白质组学管道。对于蛋白质组发现管道, 我们强烈建议使用多个识别引擎。推荐的 Fdr 以红色表示, 蛋白质数据库大小以灰色框表示。请点击这里查看此图的较大版本.
{kind=link}

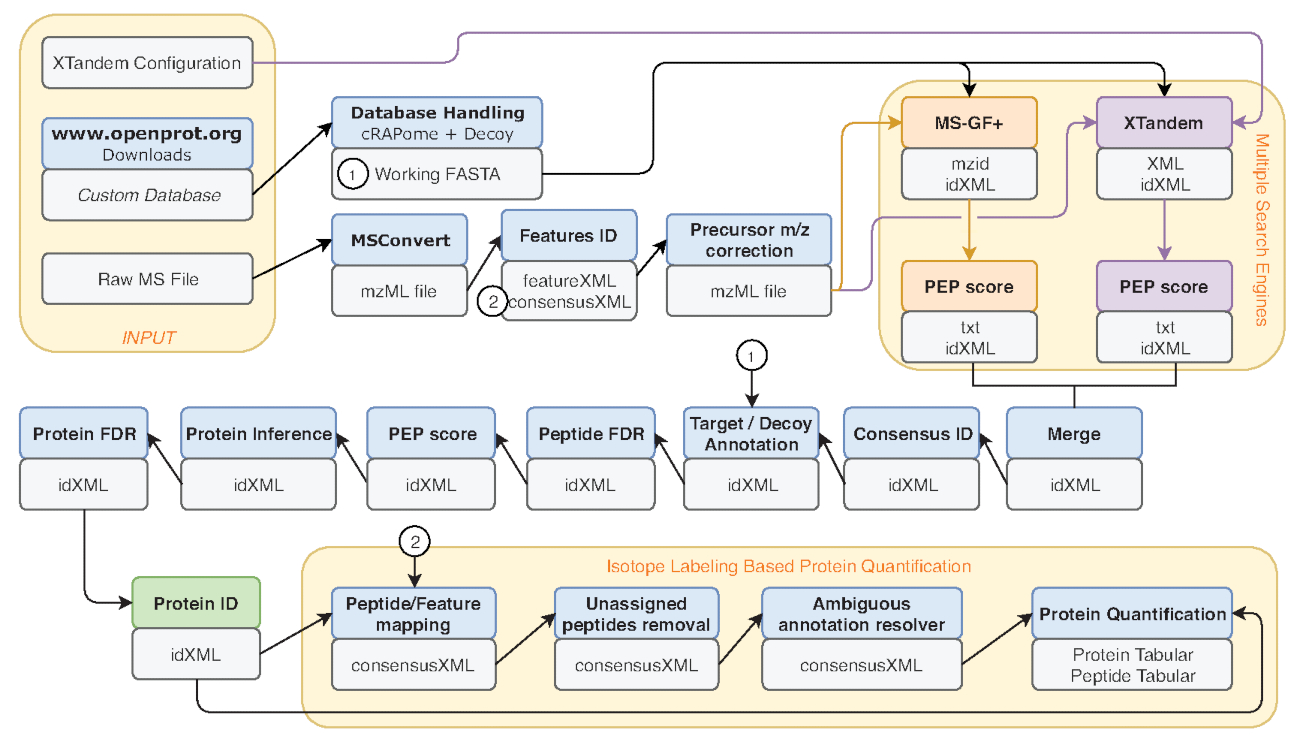
图 2* 使用的银河工作流程的图形表示.用于重新分析 Eyckerman 等人数据38的蛋白质组分析工作流的分步表示。输入文件、肽搜索和蛋白质定量由橙色框表示。蓝色框对应于使用的工具, 灰色框对应于生成的输出文件。不同的搜索引擎 (MS-GF + 和 X!串联) 由不同的颜色 (分别为红色和紫色) 以及表示其必要输入和输出的箭头表示。绿色框突出显示了生成蛋白质识别列表的工具。生成多个输出时, 用于下游步骤的输出将显示为最接近箭头的输出。此工作流程可在补充材料 S2中免费获得。X!"补充材料 S4" 中提供了串联默认参数配置文件。请点击这里查看此图的较大版本.
{kind=link}

图 3: 使用不同的数据库比较每个诱饵的交互器标识.使用最自信的 OpenProt 数据库 (橙色, 至少2个独特肽的支持证据, OpenProt_2pep) 与1% 的 FDR 或整个 OpenProt 数据库 (蓝色, OpenProt _ all) 与0.001% 的 Fdr 或报告的蛋白质识别图, 或报告的蛋白质识别图在原纸 (灰色)38。每个图对应于上述诱饵的已识别的相互关系: RAF1、RNF41、PTPN14、JIP3 和 IQGAP1。请点击这里查看此图的较大版本.
{kind=link}

图 4: 已识别的 MMNLWAK 谱(13c6) 来自新型蛋白质 IP_637643 的肽.强度是相对的 (0到100%)。选定的峰用红色表示, y 离子注解用深红色表示, b 离子注解用绿色表示。从 Topview 软件34中提取。前体错误 = 2.70 ppm, PEP 分数 = 0.12。请点击这里查看此图的较大版本.
{kind=link}
| 术语 | 定义 | 参考 |
| 替代 ORF (AltORF) | 非规范 ORF 目前没有在基因组注释中注释, 但在 OpenProt 中注释。 | 15 |
| 参考 ORF (Refof) | 在基因组注释和 OpenProt 中注释的规范 ORF。 | 15 |
| 替代蛋白 (AltProt) | 由 AltORF 编码的新蛋白质, 与 RefProt 没有明显的相似性。加入前缀: IP _。 | 15 |
| 参考蛋白 (RefProt) | 目前在蛋白质序列数据库 (如 Unidpkb、Ensembl 或 NCBI RefSeq) 中注释的蛋白质, 以及 OpenProt 中注释的蛋白质。 | 15 |
| 新颖的等形 | 由 AltORF 编码的新蛋白质, 与 RefProt 有显著相似之处。加入前缀: II _。 | 15 |
| OpenProt_2pep 数据库 | 包含 Opopenprot 预测的所有 RefProts 和新蛋白质的序列, 它已经检测到至少有2个独特的肽。 | 15 |
| OpenProt_1pep 数据库 | 包含 Opopprot 预测的所有 RefProts 和新蛋白质的序列, 这些蛋白质已经检测到至少有1个唯一的肽。 | 15 |
| 所有数据库 | 包含所有 RefProts 的序列和 OpenProt 预测的新蛋白质。 | 15 |
表 1: OpenProt 和整个协议中使用的术语的定义
补充材料 s1: 用于数据库处理的银河工作流程.这将附加一个框架序列和诱饵序列 (反向) 到输入数据库中。输出是 Fasta 文件。请点击此处下载.
补充材料 s2: 用于蛋白质鉴定的银河工作流程.这将识别蛋白质从质谱数据文件使用两个搜索引擎 (MS-GF + 和 X!串联)。在运行工作流之前, 可以根据需要对每个参数进行调整。请点击此处下载.
补充材料 s3: 使用稳定同位素标记 (SIL) 进行蛋白质定量的银河工作流程.这将识别和量化蛋白质从质谱数据文件使用两个搜索引擎 (MS-GF + 和 X!串联)。在运行工作流之前, 可以根据需要对每个参数进行调整。请点击此处下载.
补充材料 S4:x!串联默认参数配置文件。此 XML 文件是运行 x 所必需的!银河平台上的 TandemAdapter 工具。请点击此处下载.
补充材料 s5: Immispro 数据集中的定量蛋白质.Eyckerman 等人的数据文件来自 2016年 38 人, 使用 OpenProt 数据库进行了处理, 并列出了每种情况下的量化蛋白质。诱饵是 PTPN14、JIP3、IQGAP1、RAF1 和 RNF41。绿色中表示的基因名称与原始论文38中也识别的蛋白质相对应。根据生物网格, 橙色表示的基因名称对应于原始论文中没有报告的已知的相互作用。浅蓝色表示的基因名称对应于被确定为相互作用的新蛋白质 (相应的蛋白质加入编号在括号中表示)。浅灰色和斜体中表示的基因名称对应于可能的污染物 (角蛋白)。请点击此处下载.
补充材料 s6: 从 Immispro 数据集中识别出新的蛋白质.Eyckerman 等人的数据文件于 2016年 38 使用 OpenProt 数据库进行处理, 并列出了每种情况下的新的已识别蛋白质。诱饵是 PTPN14、JIP3、IQGAP1、RAF1 和 RNF41。列出了蛋白质加入数, 从已知蛋白质的新等形式的 II _ 开始, 从 ip _ 开始, 从替代 ORF (AltProt) 的新蛋白质开始。支持肽的数量在括号中表示。请点击此处下载.
讨论
在分析质谱仪的数据时, 蛋白质识别的质量在一定程度上取决于所使用的数据库6,20的准确性。目前的方法传统上使用 Unprotkb 数据库, 但这些数据库支持每个转录件的单个 ORF 和100个密码子的最小长度 (以前演示的示例除外) 的基因组注释模型40.多项研究将这类数据库的缺点与从据称非编码区域8、11、12、13中发现功能 orf 联系起来。现在, OpenProt 允许更详尽的蛋白质识别, 因为它从多个转录体注释中提取蛋白质序列。Openprot 检索 ncbi refseq (grch38. p7) 和 ensembl (grch38.83) 转录本和 uniprotkb 注释 (uniprotkb-swissprot, 2017-09-27)40,42,43。由于当前的注释几乎没有重叠, OpenProt 因此显示了潜在蛋白质组景观的更详尽的视图, 而不是仅限于一个注释15时。
此外, 由于 OpenProt 强制实施了多政务模型, 因此它允许每个转录点具有多个蛋白质注释。出于统计和计算方面的原因, OpenProt 仍然持有30个密码子15的最小长度阈值。然而, 它预测了数千个新的蛋白质序列, 从而扩大了蛋白质鉴定的可能性范围。通过这种方法, OpenProt 以更系统的方式支持蛋白质组的发现。
蛋白质识别的质量也会受到所使用参数的影响。基于 ms 的蛋白质组学分析通常持有1% 的蛋白质 FDR。但是, 整个 OpenProt 数据库包含的条目大约是 6倍 (图 1)。为了解释搜索空间的大幅增加, 我们建议使用更严格的 FDR 0.001%。利用基准研究和对随机选择的光谱15的手动评估对该参数进行了优化。不过, 假阳性仍然是有可能的, 我们鼓励对一种新蛋白质的佐证进行彻底的检查和验证。推荐的标准可以是识别来自两个不同 MS 运行的蛋白质, 因为背景数据和误报在数据集 15之间有所不同。
此处提供并用于案例研究的管道可以根据实验设计和参数进行随意修改。我们建议使用多个搜索引擎, 因为它增加了肽识别32的敏感性和敏感性.此外, 我们鼓励使用与实验目标最对应的数据库 (图 1)。由于使用整个 OpenProt 数据库带有严格的 FDR, 因此可能会丢失真正的标识。因此, 整个数据库应用于发现新的蛋白质, 而经典的蛋白质组学分析应该使用较小的 OpenProt 数据库 (如 OpenProt_2pep 在上面的案例研究中使用)。
Openprot 目前预测的序列从 atg 密码子开始, 而几项研究强调了其他密码子 44,45的翻译开始。当一种新的蛋白质被一个或几个独特的肽识别时, 真正的起始密码子可能不是假定的 ATG。用户可以在 OpenProt 网站上查找翻译证据。目前, OpenProt 仅报告翻译事件, 如果它们涉及整个预测的蛋白质序列 (100% 重叠)15。因此, 缺乏翻译证据并不意味着蛋白质没有被翻译, 但启动密码子可能不是所谓的 ATG。
尽管目前存在局限性, OpenProt 还是提供了对真核基因组编码潜力的更详尽的看法。OpenProt 数据库促进蛋白质组发现和对蛋白质组功能和相互作用的理解。OpenProt 数据库的未来发展将包括对其他物种的注释、来自非 atg 起始密码子的翻译证据以及将新蛋白质纳入全基因组和外显子组测序研究的管道的开发。
披露声明
提交人声明没有利益冲突。
致谢
我们感谢维维安·德尔考特对这项工作的帮助、讨论和建议。Xr. 是由法国和加勒比大学支助的魁北克桑特大学中心基金会的成员。这项研究得到了加拿大功能蛋白质组学和发现 x. r. 和 CIHR 赠款 mop-137056 的研究主席的支持。我们感谢魁北克 Calcul 和加拿大计算公司的团队对 Sherbrooke 大学的超级计算机 mp2 的支持。Mp2 超级计算机的运营由加拿大创新基金会、魁北克科学与创新组织 (MESI) 和《魁北克自然与技术》 (FRQ-NT) 资助。用于一些蛋白质组学计算的 Galaxy 服务器部分由协作研究中心992医疗表观遗传学 (DFG 赠款 sfsfsfs92 1 2012) 和德国联邦教育和研究部 (BMBF 赠款 031 a538c RBC, 031L0101B/031L0101C de。NBI-epi, 031L0106 de。STAIR (de。NBI))))。
材料
| Name | Company | Catalog Number | Comments |
| OpenProt website | open source | n/a | www.openprot.org |
| Galaxy Server | open source | n/a | https://usegalaxy.eu/ |
| TOPPview software | open source | n/a | www.openms.de |
参考文献
- Kim, M. S., et al. A draft map of the human proteome. Nature. 509 (7502), 575-581 (2014).
- Wilhelm, M., et al. Mass-spectrometry-based draft of the human proteome. Nature. 509 (7502), 582-587 (2014).
- Hein, M. Y., et al. A human interactome in three quantitative dimensions organized by stoichiometries and abundances. Cell. 163 (3), 712-723 (2015).
- Huttlin, E. L., et al. The BioPlex Network: A Systematic Exploration of the Human Interactome. Cell. 162 (2), 425-440 (2015).
- Huttlin, E. L., et al. Architecture of the human interactome defines protein communities and disease networks. Nature. 545 (7655), 505-509 (2017).
- Kumar, D., Yadav, A. K., Dash, D. Choosing an Optimal Database for Protein Identification from Tandem Mass Spectrometry Data. Proteome Bioinformatics. , 17-29 (2017).
- Jeong, K., Kim, S., Bandeira, N. False discovery rates in spectral identification. BMC Bioinformatics. 13 (Suppl 16), (2012).
- Brunet, M. A., Levesque, S. A., Hunting, D. J., Cohen, A. A., Roucou, X. Recognition of the polycistronic nature of human genes is critical to understanding the genotype-phenotype relationship. Genome Research. , (2018).
- Brent, M. R. Genome annotation past, present, and future: how to define an ORF at each locus. Genome Research. 15 (12), 1777-1786 (2005).
- Harrow, J., et al. GENCODE: The reference human genome annotation for The ENCODE Project. Genome Research. 22 (9), 1760-1774 (2012).
- Samandi, S., et al. Deep transcriptome annotation enables the discovery and functional characterization of cryptic small proteins. eLife. 6, e27860 (2017).
- Saghatelian, A., Couso, J. P. Discovery and characterization of smORF-encoded bioactive polypeptides. Nature Chemical Biology. 11 (12), 909-916 (2015).
- Delcourt, V., Staskevicius, A., Salzet, M., Fournier, I., Roucou, X. Small Proteins Encoded by Unannotated ORFs are Rising Stars of the Proteome, Confirming Shortcomings in Genome Annotations and Current Vision of an mRNA. Proteomics. , (2017).
- Plaza, S., Menschaert, G., Payre, F. In Search of Lost Small Peptides. Annual Review of Cell and Developmental Biology. 33 (1), (2017).
- Brunet, M. A., et al. OpenProt: a more comprehensive guide to explore eukaryotic coding potential and proteomes. Nucleic Acids Research. , (2018).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2016 update. Nucleic Acids Research. 44 (W1), W3-W10 (2016).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucleic Acids Research. 46, W537-W544 (2018).
- Sturm, M., et al. OpenMS – An open-source software framework for mass spectrometry. BMC Bioinformatics. 9 (1), 163 (2008).
- Carithers, L. J., et al. A Novel Approach to High-Quality Postmortem Tissue Procurement: The GTEx Project. Biopreservation and Biobanking. 13 (5), 311-319 (2015).
- Aebersold, R., Mann, M. Mass spectrometry-based proteomics. Nature. 422 (6928), 6928 (2003).
- Domon, B., Aebersold, R. Mass Spectrometry and Protein Analysis. Science. 312 (5771), 212-217 (2006).
- Hu, J., Coombes, K. R., Morris, J. S., Baggerly, K. A. The importance of experimental design in proteomic mass spectrometry experiments: Some cautionary tales. Briefings in Functional Genomics. 3 (4), 322-331 (2005).
- Wu, P. Y., Phan, J. H., Wang, M. D. Assessing the impact of human genome annotation choice on RNA-seq expression estimates. BMC Bioinformatics. 14 (11), S8 (2013).
- Mellacheruvu, D., et al. The CRAPome: a contaminant repository for affinity purification-mass spectrometry data. Nature Methods. 10 (8), 730-736 (2013).
- Adusumilli, R., Mallick, P. Data Conversion with ProteoWizard msConvert. Proteomics: Methods and Protocols. , 339-368 (2017).
- French, W. R., et al. Wavelet-Based Peak Detection and a New Charge Inference Procedure for MS/MS Implemented in ProteoWizard’s msConvert. Journal of Proteome Research. 14 (2), 1299-1307 (2015).
- Kuenzi, B. M., et al. APOSTL: An Interactive Galaxy Pipeline for Reproducible Analysis of Affinity Proteomics Data. Journal of Proteome Research. 15 (12), 4747-4754 (2016).
- Hoekman, B., Breitling, R., Suits, F., Bischoff, R., Horvatovich, P. msCompare: a framework for quantitative analysis of label-free LC-MS data for comparative candidate biomarker studies. Molecular & Cellular Proteomics: MCP. 11 (6), (2012).
- Bjornson, R. D., et al. X!!Tandem, an improved method for running X!tandem in parallel on collections of commodity computers. Journal of Proteome Research. 7 (1), 293-299 (2008).
- Kim, S., Pevzner, P. A. MS-GF+ makes progress towards a universal database search tool for proteomics. Nature Communications. 5, 5277 (2014).
- Vaudel, M., Barsnes, H., Berven, F. S., Sickmann, A., Martens, L. SearchGUI: An open-source graphical user interface for simultaneous OMSSA and X!Tandem searches. Proteomics. 11 (5), 996-999 (2011).
- Shteynberg, D., Nesvizhskii, A. I., Moritz, R. L., Deutsch, E. W. Combining results of multiple search engines in proteomics. Molecular & Cellular Proteomics: MCP. 12 (9), 2383-2393 (2013).
- Bittremieux, W., et al. Quality control in mass spectrometry-based proteomics. Mass Spectrometry Reviews. 37 (5), 697-711 (2018).
- Bertsch, A., Gröpl, C., Reinert, K., Kohlbacher, O. OpenMS and TOPP: Open Source Software for LC-MS Data Analysis. Data Mining in Proteomics: From Standards to Applications. , 353-367 (2011).
- Pfeuffer, J., et al. OpenMS – A platform for reproducible analysis of mass spectrometry data. Journal of Biotechnology. 261, 142-148 (2017).
- Kozak, M. Pushing the limits of the scanning mechanism for initiation of translation. Gene. 299 (1-2), 1-34 (2002).
- Noderer, W. L., et al. Quantitative analysis of mammalian translation initiation sites by FACS-seq. Molecular Systems Biology. 10, 748 (2014).
- Eyckerman, S., et al. Intelligent Mixing of Proteomes for Elimination of False Positives in Affinity Purification-Mass Spectrometry. Journal of Proteome Research. 15 (10), 3929-3937 (2016).
- Vizcaíno, J. A., et al. 2016 update of the PRIDE database and its related tools. Nucleic Acids Research. 44 (D1), D447-D456 (2016).
- Bateman, A., et al. UniProt: the universal protein knowledgebase. Nucleic Acids Research. 45 (D1), D158-D169 (2017).
- The Gene Ontology Consortium Expansion of the Gene Ontology knowledgebase and resources. Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Research. 45 (D1), D331-D338 (2017).
- O’Leary, N. A., et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation. Nucleic Acids Research. 44, D733-D745 (2016).
- Zerbino, D. R., et al. Ensembl 2018. Nucleic Acids Research. 46 (D1), D754-D761 (2018).
- Andreev, D. E., et al. Translation of 5’ leaders is pervasive in genes resistant to eIF2 repression. eLife. 4, e03971 (2015).
- Jackson, R., et al. The translation of non-canonical open reading frames controls mucosal immunity. Nature. 564, 434-438 (2018).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。