
Method Article
Масса на основе спектрометрии протеомики анализа с использованием базы данных OpenProt откроет новые белки перевод с неканоническим открытом чтения фреймов
В этой статье
Резюме
OpenProt является свободно доступной базы данных, обеспечивающая полицистронная модель эукариотических геномах. Здесь мы представляем протокол для использования OpenProt баз данных, когда допрос наборов данных масс-спектрометрии. Использование OpenProt база данных для анализа proteomic экспериментов позволяет для обнаружения новых и ранее обнаружить белков.
Аннотация
Аннотация геномов имеет центральное значение для сегодняшней протеомических исследований как он рисует контуры proteomic ландшафта. Традиционные модели открытого чтение фрейма (ORF) Аннотация навязать два произвольных критериев: Минимальная длина 100 кодонов и один ORF на стенограмму. Однако, растущее количество исследований доклад экспрессию белков от якобы-кодирования регионов, сложные точность текущей аннотации генома. Эти роман, которые были найдены белки закодированы либо в пределах некодирующих РНК, 5' и 3' непереведенные регионов (необычных) мРНК, или перекрывающихся известный кодирующая последовательность (CD) в качестве альтернативы ORF. OpenProt-это первая база данных, обеспечивающая полицистронная модель для эукариотических геномах, позволяя Аннотация несколько ORFs на стенограмму. OpenProt свободно доступным и предлагает пользовательской загрузки последовательностей белков через 10 видов. С помощью OpenProt базы данных для протеомных экспериментов позволяет обнаружить роман белков и подчеркивает характер полицистронная генов эукариот. Размер базы данных OpenProt (все предсказал белков) является существенным и должны быть приняты в учетной записи для анализа. Однако соответствующие накладные обнаружения (ФДР) настройки или использования ограниченных OpenProt базы данных, пользователи получат более реалистичное представление о proteomic ландшафта. В целом OpenProt является свободно доступные средства, которые будут способствовать proteomic открытий.
Введение
За последние десятилетия масс-спектрометрия (МС-) на основе протеомики стал золотой способ расшифровать протеомов эукариотических клеток в1,2,3,4,5. Этот метод основывается на текущей аннотации генома для создания базы данных последовательности белка ссылку, которая излагается сфера возможностей6,,78. Однако геном аннотации проводить произвольные критерии для аннотации ORF, например, минимальная длина 100 кодонов и один ORF на стенограмму9,10. Все большее количество исследований вызов текущую модель аннотации и отчет открытий unannotated функциональных ORFs в эукариотических геномах8,11,12,13, 14. Эти новые белки находятся закодированные в РНК, якобы-кодирования, в 5' и 3' untranslated регионов (утр) мРНК, или перекрывающихся канонические последовательности кодирования (ПЗС) в кадре альтернативного. Хотя большинство из этих открытий были счастливое, они демонстрируют предостережения текущей аннотации генома и полицистронная характер Гены эукариот8.
Здесь мы подчеркиваем использование OpenProt баз данных для основанных на MS протеомики. OpenProt — первая база данных провести полицистронная аннотации модель для eukaryotic transcriptomes. Она свободно доступна на www.openprot.org15. Доля этих предсказал бы ORFs случайных и нефункциональные, который является, почему OpenProt кумулирует экспериментальных и функциональных доказательств для повышения доверия. Экспериментальные доказательства включают в себя выражения протеина (в мс) и перевод свидетельства (рибосома профилирования)15. Функциональные доказательства включают Гомология белка (с In-параноик, как подход) и функционального домена предсказание15.
OpenProt предлагает возможность скачать несколько баз данных, содержащего только хорошо поддерживается белки для индивидуальных баз данных. Здесь, мы будем представлять трубопровода для использования баз данных OpenProt и будет предлагать идеи в какой базе данных выбрать, учитывая в экспериментальных целях. Конвейер анализа протеомики, представленные здесь поддерживается Галактика рамки как это открытого доступа и easy-to-use, но баз данных можно работать с любого рабочего процесса по16,17,18. Мы также представим как использовать веб-сайт OpenProt для сбора дополнительной информации о новых белков, обнаруженных г-жа OpenProt использование баз данных будет более исчерпывающего представления proteomic ландшафта и будет способствовать протеомики и биомаркеров открытий в более систематическим образом чем текущие методы.
Этот протокол выделяет использование OpenProt баз данных15 при допросе MS наборов данных; Он не будет рассматривать дизайн эксперимента самого, который был тщательно рассмотрен других20,21,22. В попытке оставаться полностью открытым исходным кодом протокол является свободно доступны (Дополнительный материал S1–S4). Для упрощения чтения, все термины, используемые в OpenProt и настоящим этот протокол определены в таблице 1.
протокол
1. OpenProt Загрузка базы данных
Примечание: Пользовательские базы данных, на основе данных РНК seq например также может быть получен и процедура подробно описана во втором разделе настоящего Протокола. Если пользовательские базы данных требуется, перейдите к следующему разделу.
- Перейдите на веб-сайте OpenProt: www.openprot.org и открыть страницу загрузки, используя ссылку в меню вверху страницы.
- Нажмите на вид интереса, основанный на анализируемом экспериментальных данных.
- Нажмите на желаемый тип белка.
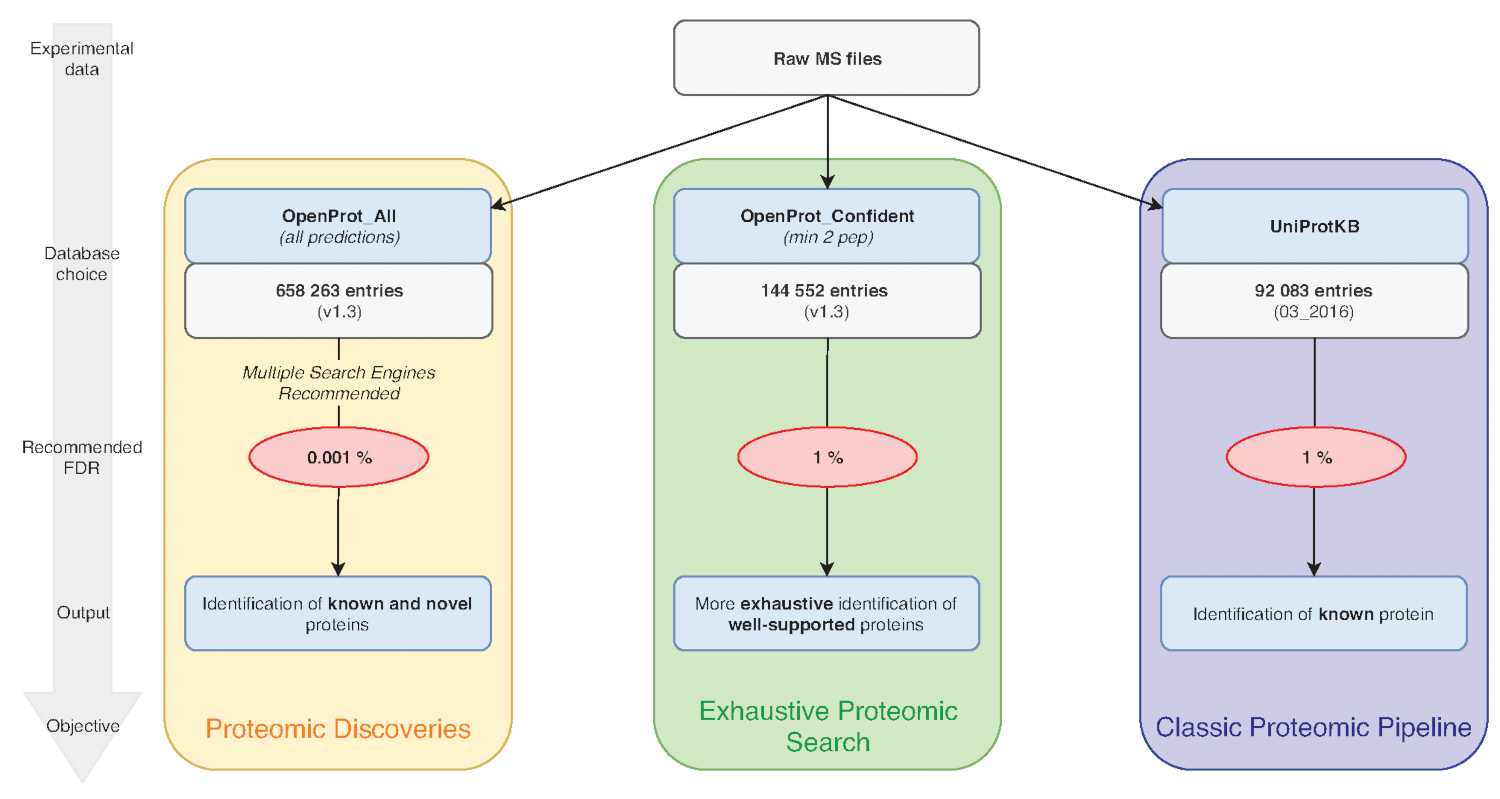
Примечание: OpenProt предлагает три классификации: RefProt, изоформ и AltProt. Как показано на рисунке 1, этот параметр будет меняться в зависимости от цели исследования.- Нажмите на RefProt один для создания файлов, содержащих только известных белков.
- Нажмите на AltProt и изоформ для создания файлов, содержащих только Роман белки - либо Роман изоформ известных белков (изоформ) или закодированных альтернативу ORF (AltProts). Пожалуйста, обратите внимание, что OpenProt обеспечивает минимальную длину ORF 30 кодонов15.
- Нажмите на AltProts, изоформ и RefProts для создания файлов, содержащих все типы белков, присутствующих в базе OpenProt - известные и новые белки.
- Если доступен, нажмите на аннотации, от которого белка рисуются последовательности.
Примечание: OpenProt предлагает более исчерпывающий ландшафт proteomic путем объединения нескольких аннотации. Транскриптом аннотации имеют минимальное дублирование; Таким образом выбранные заметки может существенно повлиять на визуализируемых proteomic профиль15,23. - Нажмите кнопку на уровень подтверждающих доказательств, необходимых для рассмотрения белка. Как показано на рисунке 1, этот параметр будет меняться в зависимости от цели исследования.
- Нажмите на минимум два уникальных пептидов обнаружено для создания файлов, содержащих только наиболее уверенно белков.
Примечание: В настоящее время критерий два уникальных пептиды считается золотым стандартом в протеомике для выражения протеина. Если экспериментальной целью обнаружить протеины известных и хорошо поддерживается, рекомендуется использовать этот параметр. - Нажмите на минимум один уникальный пептидов обнаружено для создания файлов, содержащих белки, которые уже видели по крайней мере один раз среди масс-спектрометрии эксперименты, повторно проанализированы OpenProt.
Примечание: Это позволяет для рассмотрения короче длины AltProts и вероятность того, что некоторые из них могут содержать только один уникальный tryptic пептид8,11. - Нажмите на все предсказал для создания файлов, содержащих все предсказания OpenProt.
Примечание: Этот параметр рекомендуется только если экспериментальной цель состоит в том, чтобы обнаружить роман белки (рис. 1). Последующее существенное увеличение пространства вызовов поиска для анализа адаптированных конвейера ниже7,15.
- Нажмите на минимум два уникальных пептидов обнаружено для создания файлов, содержащих только наиболее уверенно белков.
- Нажмите на нужный формат файла для загрузки. Для протеомных анализов выберите файл Fasta (белка). Файл readme содержит всю необходимую информацию о формате файла.
2. пользовательская загрузка базы данных OpenProt
Примечание: В этом разделе подробно описано, как получить в пользовательской базе данных. Если пользовательские база данных не требуется, перейдите к следующему разделу.
- Перейдите на веб-сайт OpenProt (www.openprot.org) и откройте страницу поиска, используя ссылку в меню вверху страницы.
- Нажмите на видов интерес, на основе анализа экспериментальных данных.
- Введите список генов или стенограммы интерес.
- При использовании списка генов, введите его в поле запроса ген .
- При использовании списка стенограммы, введите его в поле запроса транскрипта .
- Отметьте поле, которое применяется к нужной базе данных.
- Не нажимайте на любое поле, чтобы получить таблицу, содержащую все виды белков, поддерживаемых OpenProt: RefProt, изоформ и AltProts.
- Нажмите на Показать только белки с экспериментальных доказательств , чтобы получить таблицу, содержащую все виды белков (RefProts, изоформ и AltProts), которые были обнаружены по крайней мере один раз MS и/или для которых перевод доказательства были собраны от рибосомы Профилирование данных.
- Аналогичным образом нажмите на Показать только белков, обнаруженных MS или Показать только белков, обнаруженных рибосома профилирования для получения таблицы, содержащие все виды белков, которые были обнаружены по крайней мере один раз MS или рибосомы, профилирование соответственно.
- Нажмите на Показать только AltProts или Показать только изоформ получить таблицу, содержащую только AltProts или только изоформ соответственно.
- Нажмите на Показать только AltProts и Показать только изоформ получить таблицу, содержащую обоих видов белков.
Примечание: Возможны все комбинации фильтров.
- После того как заданы все требуемые параметры, нажмите на поиск. Вывод таблицы появится ниже поля запроса поиска.
- Нажмите на кнопку Скачать Fasta в правом верхнем углу выходной таблицы. Это будет генерировать Fasta файл, содержащий все белки, обусловленные запрашиваемый список генов или стенограммы.
- Пожалуйста, обратите внимание, что для вычислительной причинам, OpenProt содержит более 2000 элементов, чтобы быть запрос (генов или стенограммы) одновременно. В случае списка выше этого предела несколько fasta может быть создан и затем объединяются (как описано ниже); или просто загрузить всю базу данных OpenProt и отфильтровать полученный файл как желаемого.
- Бин весь список генов или стенограммы в вложенные списки 2000 записей или меньше. Для каждого суб списка скачайте файл Fasta, как описано выше (шаг 3.3 до 3,6).
- Войдите в экземпляре Европейской Галактика (или любой другой экземпляр, где доступны инструменты протеомики), https://usegalaxy.eu/.
- Создайте новую историю и импортируйте все загруженные базы данных OpenProt (по одному на вложенный список генов или стенограммы), нажав на логотип загрузки в левой верхней части экрана.
- Используйте средство Fasta слияния файлов и фильтр уникальных последовательностей , разработанный GalaxyP разработчиков (https://github.com/galaxyproteomics/). Выберите параметр Слияние всех Fasta и ввод всех импортируемых баз данных OpenProt.
Примечание: Каждый инструмент можно выполнять поиск с помощью окна запроса на левой стороне экрана - Выберите параметр только присоединение для оценки последовательности уникальность и скопировать правило разбора идентификатора OpenProt (>(.*) \ |), затем выберите команду выполнить.
- Обратите внимание, что все файлы были объединены в уникальный файл Fasta с без избыточности, которая теперь отображается в панели «История» на правой стороне экрана. Это представляет собой рабочую базу данных.
3. база данных обработка
Примечание: Теперь Галактики платформа будет использоваться, но те же принципы могут применяться к другим proteomic программного обеспечения.
- Войдите в экземпляре Европейской Галактика (или любой другой экземпляр, где доступны инструменты протеомики), https://usegalaxy.eu/.
- Создайте новую историю и импортировать загруженные базы данных OpenProt, нажав на логотип загрузки в левой верхней части экрана.
- Перейдите на страницу рабочего процесса и импорта процесс обработки базы данных (Дополнительный материал S1), щелкнув на логотип загрузки в левой верхней части средней панели.
- Нажмите на Запуск рабочего процесса и выберите импортированной базы данных OpenProt в качестве входных данных.
Примечание: Этот рабочий процесс будет добавить репозиторий CRAPome OpenProt fasta и генерировать манок последовательности (обратной последовательности)24. Если список манок shuffle, это можно сделать, изменив этот параметр на DecoyDatabase инструменте. - Переименуйте полученный файл Fasta для что-нибудь осмысленное. База данных готова к использоваться для протеомики анализов.
4. Подготовка файла масс-спектрометрии
Примечание: Большинство инструментов протеомики доступна на галактику экземпляров использовать формат mzML, и пептида поисковых систем предпочитают данные в режиме центроид.
- Открыть средство свободно доступных MSConvert из ProteoWizard suite и загрузить файл данных быть проанализированы25.
- Выберите каталог для выходных данных и требуемый формат файла для mzML.
- Установите выбора фильтра с помощью алгоритма на основе вейвлет (CWT) на уровнях MS1 и MS2 пик и запустите преобразование26.
5. пептидов и белков идентификации/количественная оценка
Примечание: Эта часть конвейера использует средства от OpenMS люкс, универсальный и простой в использовании рамок18.
- Войдите в экземпляре Европейской Галактика (или любой другой экземпляр, где доступны инструменты протеомики), https://usegalaxy.eu/.
- Создайте новую историю и передачи ранее созданной базы данных (шаг 3.5) этой новой истории с drag-and-drop.
- Импорт файла данных превращается mzML (шаг 4.3), щелкнув загрузить логотип в левой верхней части экрана.
- Перейдите на страницу рабочего процесса и импортировать нужный рабочий процесс, нажав на логотип загрузки в левой верхней части средней панели.
Примечание: MS по-разному эксперименты основаны на желаемый конечный результат. Рабочие процессы здесь предусмотрены две частые конструкции: белка идентификации и количественного определения белка на основе стабильных изотопов, маркировки (SIL). Однако Галактика экземпляр содержит многие другие инструменты, которые будут поддерживать другие виды протеомного анализа27,28.- Для идентификации дизайна белка Импорт рабочего процесса, в Дополнительный материал S2. При использовании этого рабочего процесса, пожалуйста, не используйте zlip сжатие при преобразовании файлов (шаг 4.2)
- Для количественного определения белков, основанный на стабильных изотопов маркировки дизайн Импорт рабочего процесса, в Дополнительный материал S3.
- Выберите запустить рабочий процесс и пересмотреть различные параметры.
- Выберите файл данных импортированные mzML качестве входных данных и ранее созданной базы данных (шаг 3.5) как Fasta файла базы данных.
- Так как рабочий процесс использует X! Тандем поиск двигатель, импорт X! Тандем по умолчанию конфигурации файла (в Дополнительный материал S4)29 , нажав на логотип загрузки в левой верхней части экрана.
- Рабочий процесс использует несколько поисковых систем (MS-GF + и X! Тандем). Добавьте другие поисковые системы или выбрать один просто путем добавления или удаления инструменты из рабочего процесса30,31.
Примечание: Рекомендуется использовать несколько поисковых системах как это увеличивает чувствительность и чувствительность анализа32. - Для того, чтобы учесть значительное увеличение размера при использовании всей базы данных OpenProt, используйте строгие ФДР15. По умолчанию, предоставленный рабочий процесс имеет значение 0,001% ФДР, достаточное для использования всей базы данных OpenProt. Для других баз данных это можно изменить на любое желаемое значение.
Примечание: Не забудьте адаптировать параметры различных инструментов в зависимости от используемых масс-спектрометр и экспериментальный протокол (прекурсоров Ион и фрагмент, Исправлена ошибка и изменения переменных, используемых фермента и т.д.).
- При необходимости скачайте вывода для каждого шага рабочего процесса для хранения или анализа, контроля качества, щелкнув на выбранном шаге из панели «История», а затем щелкнув сохранить логотип, который будет отображаться под.
6. контроль качества
Примечание: Потому, что на основе MS протеомики является результатом сложного процесса, где каждый шаг должен быть оптимизированы для получения воспроизводимых результатов, контроль качества – необходимая процедура в рабочего процесса33.
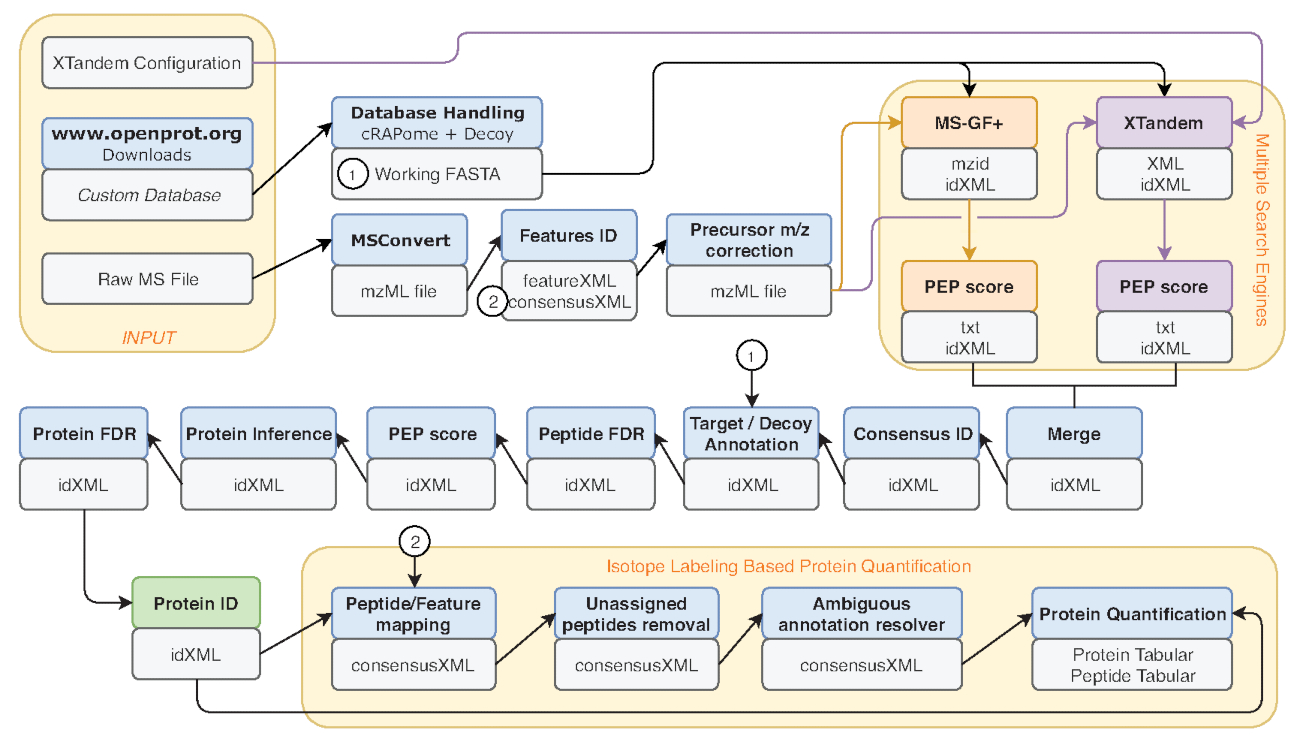
- Несколько метрик являются общий показатель производительности, такие как количество пептид спектр матчей (PSM), количество выявленных пептидов и белков. Запустите средство File Info на выходе IDFilter (показано зеленым цветом на рис. 2) для обеспечения таких показателей.
- Хотя не применяется к каждой идентификации, особенно с большими наборами данных, сообщения о новых белков следует всегда тщательно оцениваться. Осмотр Оценка белка, последовательность покрытия и спектров, поддерживая вывод имеет жизненно важное значение. Используйте средство TOPPview от OpenMS рамки для этого; Она свободно доступна и хорошо документированы18,34,35.
7. OpenProt базы данных добычи
Примечание: После того, как был достигнут уверенно идентификации романный протеин предсказано OpenProt (присоединение чисел, начиная с IP_ для AltProts и II_ для Роман изоформ), больше биологических информация может быть собрана из сайта OpenProt15.
- Перейдите на веб-сайте OpenProt: www.openprot.org и откройте страницу поиска, используя ссылку в меню вверху страницы.
- Нажмите на вид интереса (же, как тот, в котором была определена белка) и введите номер присоединения белка в поле запроса белка .
- Нажмите на поиск и появится таблица, содержащая основные сведения о запрашиваемых белка. Таблица функций: длина белка (в аминокислоты), его молекулярный вес (кДа) и Изоэлектрическая точка, поддержка экспериментальных доказательств MS или рибосома профилирования (перевод свидетельства, TE) и функциональных предсказания такие как предсказал доменов и белка Гомология (через 10 видов, поддерживаемых OpenProt, v1.3). Таблица также содержит информацию о соответствующих генов и Стенограмма и локализация белка в стенограммы.
- Нажмите на ссылку Подробности для сбора дополнительной информации. Недавно открывшийся странице содержится генома браузер, которая сосредоточена на запрашиваемые протеина и информации, например геномные и транскриптомики координаты и наличие Козак или высокой эффективности перевода начало сайта (TIS) мотив36, 37.
- Нажмите на ДНК или белка ссылки на вкладке Информация, чтобы получить белка или последовательностей ДНК, соответственно.
- Просмотр детальной информации о MS доказательства, рибосомы, профилирование выявления, сохранения и доменов определены протеина, нажав на верхней вкладки15.
Результаты
Рабочий процесс, описанный выше был применен к набору данных MS на гордость репозитория38,39. Оригинальные исследования разработан метод (iMixPro), с использованием стабильных изотопов маркировки аминокислот в культуре клеток (SILAC), чтобы исключить ложные срабатывания от очищение сродства мс (AP-МС) эксперименты38. Короче говоря эксперимент AP-MS состоит в использовании бусы прыгните антитела для извлечения протеина интереса (байт) и ее посредники (жертв). Собранные белки затем переваривается и подготовлен для MS. Метод подготовки и настройки инструмента описаны в первоначальном исследовании и на хранилище гордость (PXD004246). Вызов в таких экспериментов является обилие ложных срабатываний, особенно от белков, привязка к бисер, но не приманку. Здесь, мы использовали SILAC для создания различных изотопов соотношения между истинной preys и ложных срабатываний: 3 управления образцы (нет приманки) культивировали в легкий средний, 1 образец, выражая приманки, культивируемых в легких средних и 1 образец, выражая приманки, культивируемых в тяжелых средах обработаны с бисером и дальнейшего анализа масс-спектрометрии. С такой дизайн неспецифических белков, привязка к бисеру будет иметь тяжелые свет соотношение 1:4; Когда true preys будет иметь отношение 1:138.
Мы повторно проанализировали их данных AP-MS, используя базу данных OpenProt; приманки включены три эндогенного белков (PTPN14, JIP3 и IQGAP1), и два чрезмерно выразил белков (RAF1 и RNF41). Поскольку эксперименты используется SILAC, Галактика рабочего процесса для количественного определения белка была использована (Дополнительный материал S3, рис. 2). Рабочий процесс был запущен с использованием ограниченного базы данных OpenProt (OpenProt_2pep, включая только белки, ранее обнаруженных с минимум два уникальных пептиды) или вся база данных OpenProt (OpenProt_all).
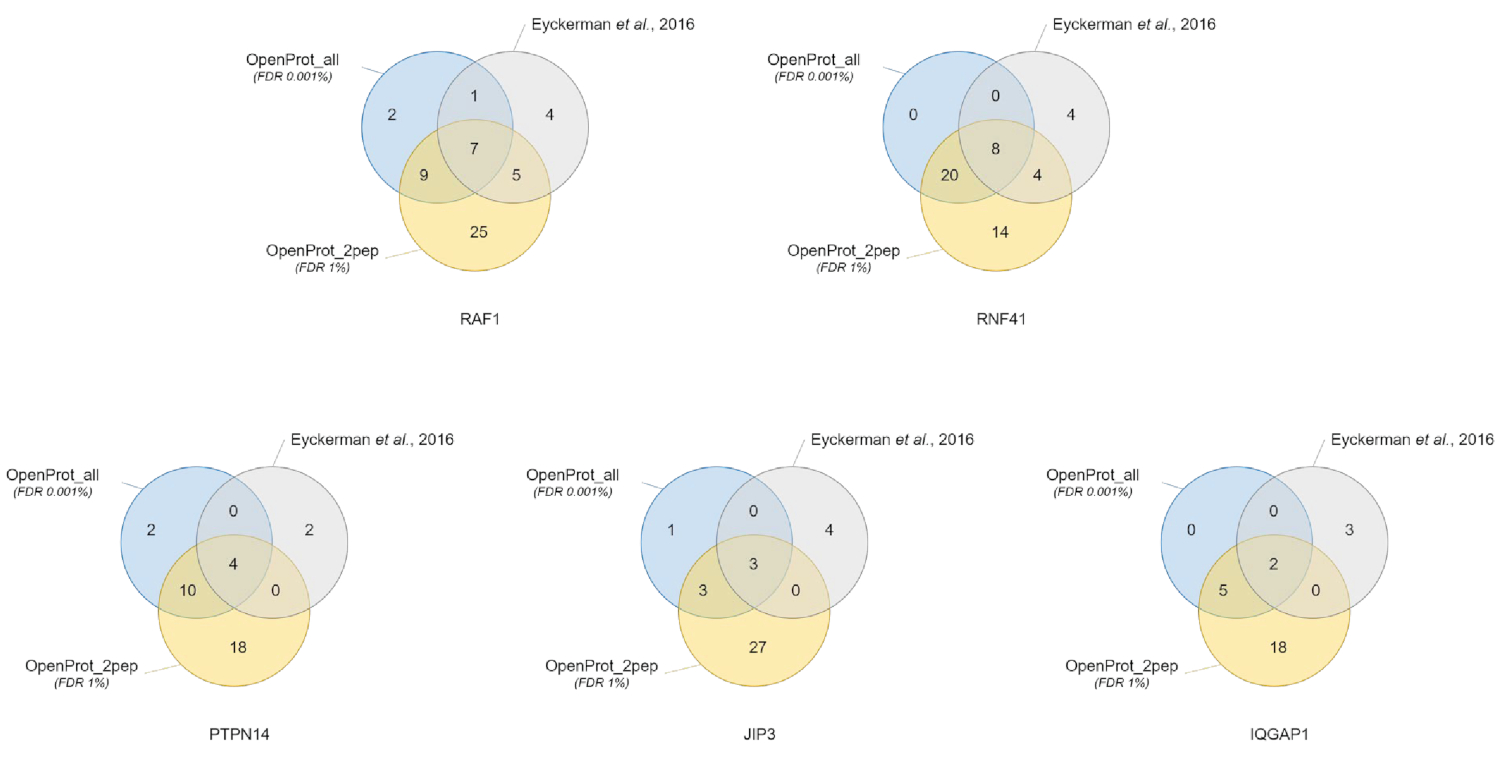
Белка идентификации и количественной оценки были хорошие и воспроизводимых через различных используемых баз данных. Как показано на рисунке 3, большинство белков, указанных в первоначальном документе были также определены с использованием OpenProt_2pep или OpenProt_all базы данных (подробный список доступен в Дополнительных материалов S5). Этот результат показывает, что трубопровод, описанные здесь и баз данных в состоянии производить белок идентификации и количественной оценки, сопоставимой с эффективностью работы нынешних процедур, основанных на базах данных UniProtKB40OpenProt. Однако использование баз данных OpenProt имеет уникальное преимущество позволяет обнаружение Роман и ранее обнаружить белков, как показано в этом случае исследование.
11 хорошо поддерживается белков (1 изоформы и 10 AltProts), но в настоящее время не аннотированных в базах данных, были выявлены во всех наборов данных, с уверенно пептиды, используя базу данных OpenProt_2pep (все белка присоединения, а также количество поддержки пептиды, доступны в Дополнительный материал S5). Эта база данных позволяет использовать традиционные 1% ФДР как увеличение пространства поиска остается умеренной. Эти 11 белки не были выявлены в ходе первоначального исследования, как они отсутствовали из базы данных.
29 новых белков (16 изоформ и 13 AltProts) были обнаружены во всех наборов данных, с уверенно пептиды, используя базу данных OpenProt_all (всех присоединений белка, наряду с числом вспомогательных пептиды, находятся в дополнительного материала S6 ). Как показано на рисунке 3, рекомендуется строгий Рузвельта не затрагивает наиболее уверенно идентификации белков, хотя он уменьшить общее количество выявленных белков. Сравнительно в базу данных OpenProt_2pep, большее количество новых белков может быть уверенно определены. Все эти новые белки отсутствуют из базы данных OpenProt_2pep. Это подчеркивает решающую роль выбранной базы данных на основе MS протеомики.
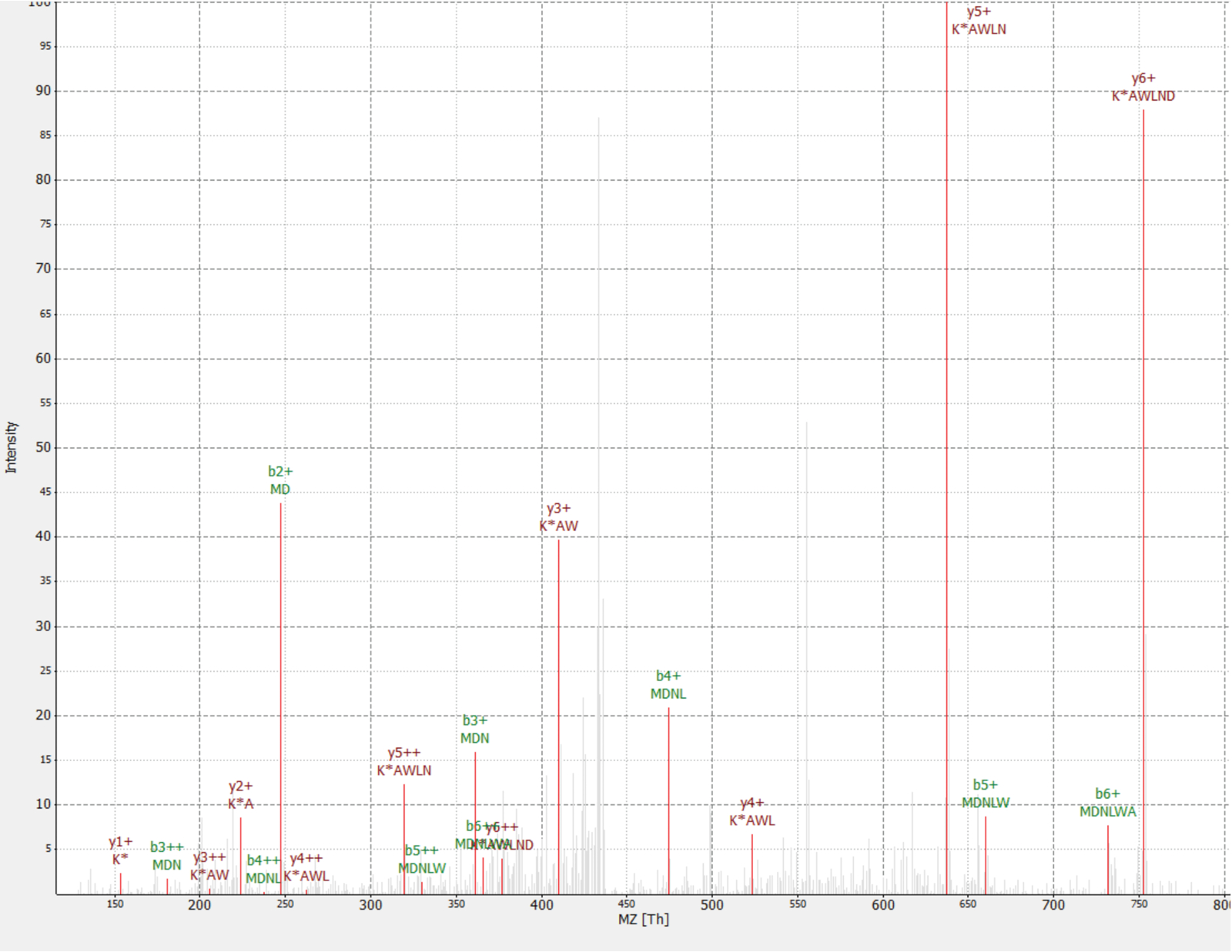
Один новый белок был обнаружен в качестве интерактивных RAF1 белка (IP_637643). Использование веб-сайта OpenProt, можно увидеть этот белок не было обнаружено ни MS, ни рибосома профилирования до сих пор (OpenProt v1.3). Белок является 46 аминокислот длиной и может дать только два уникальных пептидов при tryptic пищеварение. Пептид обнаружены в RAF1 AP-MS dataset (фракция 18) имел хорошее качество спектра, как показано на рисунке 4и отображается соотношение тяжелых свет 1,09. Белок кодируется в гене NANOGNBP1 , который является Псевдогены NANOGNB. Стенограммы (ENST00000448444), в настоящее время помечен как не кодирования, был обнаружен через несколько тканей по данным портала GTEx40. Белок содержит предсказал функционального домена, связанные с ДНК привязки (онтология гена GO: 0003677)41.

Рисунок 1 : База данных выбор для протеомики анализов диаграммы. Анализ данных MS, особенности выбора базы данных, зависит от целей исследования. Три общие цели изложены в голубой (классический proteomic трубопровода), зеленый (исчерпывающий proteomic Поиск) и оранжевый (proteomic обнаружения). Каждой цели зависит от соответствующей базы данных и трубопровода. Один идентификации инструмент может использоваться для исчерпывающего и классической протеомики трубопроводов. Для протеомных обнаружения трубопровода мы настоятельно рекомендуем использовать несколько двигателей идентификации. Рекомендуемые потребоваться указаны в красном, и белка размеры базы данных указаны в серые коробки. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 2 : Графическое представление Галактика рабочего процесса используется. Шаг за шагом представление протеомного анализа рабочего процесса, для повторного анализа данных Eyckerman et al.38. Оранжевые прямоугольники обозначаются входных файлов, Поиск пептида и белка количественной оценки. Синие ящики соответствуют инструменты, используемые, и серые участки соответствуют выходные файлы создаются. Различные поисковые системы (MS-GF + и X! Тандем) обозначаются разными цветами (соответственно, красный и фиолетовый), а также стрелки, указывающие их необходимые входы и выходы. Зеленом поле подчеркивает средство генерации списка идентификации белков. Когда создаются несколько выходов, используется для вниз по течению шагов указывается как ближайший к стрелку. Этот рабочий процесс свободно доступен в Дополнительный материал S2. X! Тандем по умолчанию параметры конфигурации файл доступен в Дополнительный материал S4. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 3 : Сравнение interactor идентификации на приманку, с использованием различных баз. Венна идентификации белков, используя наиболее уверенно OpenProt база данных (в оранжевый, подтверждающих доказательств минимум 2 уникальных пептидов, OpenProt_2pep) с 1% ФДР, или весь OpenProt база данных (в синем, OpenProt_all) с 0,001% ФДР, или как сообщалось в оригинальной бумаге (в серый)38. Каждая диаграмма соответствует выявленных посредники для упомянутых приманки: RAF1, RNF41, PTPN14, JIP3 и IQGAP1. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 4 : МС/МС спектр выявленных MDNLWAK(13C 6) пептид из романа белка IP_637643. Интенсивность относительное (0-100%). Отдельных пиков указаны в красном, y аннотации ионы находятся в темно красный и b ионов аннотации в зеленый. Извлеченные из программного обеспечения TOPPview34. Прекурсоров ошибка = 2,70 млн, PEP оценка = 0,12. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}
| Срок | Определение | Ссылка |
| Альтернативные ORF (AltORF) | нестандартные ORF в настоящее время не в геном аннотации, но в OpenProt. | 15 |
| Ссылка ORF (RefORF) | канонические ORF, аннотированных в геном аннотации и OpenProt. | 15 |
| Альтернативные белка (AltProt) | Роман белков, закодированных на AltORF, с никакого значительного сходства с RefProt. Присоединение префикс: IP_. | 15 |
| Ссылка белка (RefProt) | белка в настоящее время аннотированный в базах данных последовательности белка UniProtKB, Ensembl или NCBI RefSeq, а также в OpenProt. | 15 |
| Роман изоформы | Роман белков закодированы AltORF, с значительного сходства с RefProt. Присоединение префикс: II_. | 15 |
| OpenProt_2pep база данных | содержит последовательность всех RefProts и Роман белков, предсказано OpenProt, уже обнаружено с минимум 2 уникальных пептиды. | 15 |
| OpenProt_1pep база данных | содержит последовательность всех RefProts и Роман белков, предсказано OpenProt, уже обнаружено с минимум 1 уникальный пептид. | 15 |
| OpenProt_all база данных | содержит последовательность всех RefProts и Роман белков, предсказано OpenProt. | 15 |
Таблица 1: Определение терминов, используемых в OpenProt и протокол
Дополнительный материал S1: Галактика рабочий процесс для обработки базы данных. Это добавит (обратный) к базе данных входной последовательности CRAPome и манок. Вывод представляет собой файл Fasta. Пожалуйста, нажмите здесь, чтобы скачать.
Дополнительный материал S2: Галактика рабочий процесс для идентификации белков. Это будет идентифицировать белки из файла данных масс-спектрометрии с помощью двух поисковых систем (MS-GF + и X! Тандем). Каждый параметр может быть настроен как пожелано перед запуском рабочего процесса. Пожалуйста, нажмите здесь, чтобы скачать.
Дополнительный материал S3: Галактика рабочий процесс для количественного определения белка с помощью стабильных изотопов, маркировки (SIL). Это будет выявлять и количественно белки из файла данных масс-спектрометрии с помощью двух поисковых систем (MS-GF + и X! Тандем). Каждый параметр может быть настроен как пожелано перед запуском рабочего процесса. Пожалуйста, нажмите здесь, чтобы скачать.
Дополнительного материала S4: X! Тандем по умолчанию параметров файла конфигурации. Этот XML-файл необходим для запуска X! TandemAdapter инструмент на платформе галактики. Пожалуйста, нажмите здесь, чтобы скачать.
Дополнительный материал S5: количественно белки из наборов iMixPro. Файлы данных из Eyckerman et al. 201638 были обработаны с использованием баз данных OpenProt и количественных белки, перечислены для каждого условия. Приманки, PTPN14, JIP3, IQGAP1, RAF1 и RNF41. Джин имена, указанные в зеленый соответствуют белки, также указаны в оригинальный документ38. Джин имена, указанные в оранжевый соответствуют известным посредники согласно BioGrid, которые не были указаны в первоначальном документе. Джин имена, указанные в светло-голубой соответствуют Роман белки, определены как посредники (соответствующий белок присоединения номер указывается в скобках). Джин имена указанных в светло-серый и курсивом соответствуют вероятно загрязняющих веществ (белки кератин). Пожалуйста, нажмите здесь, чтобы скачать.
Дополнительный материал S6: определены Роман белки из наборов iMixPro. Файлы данных из Eyckerman et al. 201638 были обработаны с использованием баз данных OpenProt и Роман определенных белков, перечислены для каждого условия. Приманки, PTPN14, JIP3, IQGAP1, RAF1 и RNF41. Белка присоединения номера перечислены, начиная с II_ для Роман изоформ известный белка и с IP_ Роман белков из альтернативных ORF (AltProt). Число вспомогательных пептиды, указаны в скобках. Пожалуйста, нажмите здесь, чтобы скачать.
Обсуждение
При анализе данных от масс-спектрометры, качество белка идентификации частично зависит от точности используемых баз данных6,20. Нынешние подходы традиционно используют UniProtKB баз данных, однако эти поддерживают минимальную длину 100 кодонов (за исключением ранее продемонстрировал примеры)40и геном аннотации модель одного ORF на стенограмму. Многочисленные исследования касаются недостатков таких баз данных с открытием функциональных ORFs от якобы некодирующих регионов8,11,12,13. Теперь OpenProt позволяет для более тщательной идентификации белков как она рисует белковых последовательностей из нескольких транскриптом аннотации. OpenProt извлекает NCBI RefSeq (GRCh38.p7) и transcriptomes Ensembl (GRCh38.83) и UniProtKB аннотации (UniProtKB-SwissProt, 2017-09-27)40,42,43. Как текущей аннотации представляют мало перекрытия, OpenProt таким образом отображает представление более исчерпывающий потенциальных proteomic пейзаж чем когда ограничивается одной аннотации15.
Кроме того как OpenProt задает строгую модель полицистронная, он позволяет несколько белков аннотации на стенограмму. Для вычислительных и статистических причин OpenProt по-прежнему имеет минимальную длину порога 30 кодонов15. Тем не менее она предсказывает тысячи новых белковых последовательностей, тем самым расширение возможностей для идентификации белков. С этим подходом OpenProt поддерживает proteomic открытий на более систематической основе.
Качество белка идентификации также может зависеть от параметров, которые используются. На основе MS протеомики анализов обычно занимают 1% белка ФДР. Однако вся база данных OpenProt содержит примерно в 6 раз больше записей (рис. 1). Для учета этого существенного увеличения пространства поиска, рекомендуется использовать более строгие ФДР 0,001%. Этот параметр был оптимизирован с помощью базового исследования и ручной оценки случайно выбранных спектры15. Ложный положительный результат по-прежнему являются возможность, хотя, и мы призываем тщательный осмотр и проверка доказательств для новый белок. Рекомендуемый стандарт может быть определение белка от двух разных MS бежит, как справочные данные и ложных срабатываний различаются между15наборов данных.
Конвейера здесь и используется для представления тематических исследований может быть изменен как приятно экспериментальный дизайн и параметры. Мы рекомендуем использовать несколько поисковых систем, как он увеличивает чувствительность и чувствительность пептид идентификации32. Кроме того мы призываем, используя базу данных лучше всего соответствует в экспериментальных целях (рис. 1). Как с помощью весь OpenProt, база данных поставляется с строгий Рузвельта истинной идентификации могут быть потеряны. Таким образом вся база данных должен быть предназначен для обнаружения новых белков, в то время как классическая протеомики профилирования следует использовать меньшие OpenProt баз данных (например, OpenProt_2pep, используемых в тематическом исследовании выше).
OpenProt в настоящее время предсказывает последовательности, начиная с кодоном ГПТ, тогда как несколько исследований выделены инициации перевода на другие кодонов44,45. Когда новый белок определяется один или несколько уникальных пептиды, вполне возможно кодон истинное посвящение не предполагаемой ГПТ. Пользователи могут искать перевод свидетельства на веб-сайте OpenProt. В настоящее время OpenProt сообщает только перевод события, если они касаются всю прогнозируемым белка последовательности (100% совпадения)15. Таким образом отсутствие доказательств перевод не будет означать что белок не переведены, но что кодон начала не может быть предполагаемым ГПТ.
Несмотря на свои текущие ограничения OpenProt предлагает более исчерпывающее представление эукариотических геномах кодирования потенциал. OpenProt баз данных способствуют proteomic открытий и понимание proteomic функций и взаимодействия. Будущие события OpenProt базы данных будет включать аннотацию других видов, перевод свидетельств от не ГПТ начать кодон и развития трубопровода включить Роман белков в весь геном и exome последовательность исследования.
Раскрытие информации
Авторы заявляют никакого конфликта интересов.
Благодарности
Мы благодарим Вивиан Delcourt за его помощь, обсуждения и консультации по этой работе. X.R. является членом Fonds de Recherche дю du Québec Santé FRQS-поддерживает центр исследований больничного университетский центр де Шербрук. Это исследование было поддержано Канада исследований кафедры в функциональной протеомики и обнаружения Роман белки Грант СС-137056 X.R. и КНИИЗ. Мы благодарим команда Calcul Квебека и Канады Compute для их поддержки с использованием суперкомпьютеров mp2 из Université de Шербрук. Операция mp2 суперкомпьютер финансируется по Канаде фонд из инноваций (CFI), le ministère де л ' экономики, науки-де-ла et de l'innovation du Квебека (МЭСИ) и les Fonds de Recherche Квебека - природа et технологии (FRQ-NT). Галактика сервер, который был использован для некоторых расчетов протеомики частично финансируется за счет совместных исследований центр 992 медицинской эпигенетики (DFG Грант SFB 2012 992/1) и немецкого федерального министерства образования и научных исследований (BMBF предоставляет 031 РБК A538A/A538C, 031L0101B Де /031L0101C. NBI-epi, 031L 0106 де. ЛЕСТНИЦЫ (de. NBI)).
Материалы
| Name | Company | Catalog Number | Comments |
| OpenProt website | open source | n/a | www.openprot.org |
| Galaxy Server | open source | n/a | https://usegalaxy.eu/ |
| TOPPview software | open source | n/a | www.openms.de |
Ссылки
- Kim, M. S., et al. A draft map of the human proteome. Nature. 509 (7502), 575-581 (2014).
- Wilhelm, M., et al. Mass-spectrometry-based draft of the human proteome. Nature. 509 (7502), 582-587 (2014).
- Hein, M. Y., et al. A human interactome in three quantitative dimensions organized by stoichiometries and abundances. Cell. 163 (3), 712-723 (2015).
- Huttlin, E. L., et al. The BioPlex Network: A Systematic Exploration of the Human Interactome. Cell. 162 (2), 425-440 (2015).
- Huttlin, E. L., et al. Architecture of the human interactome defines protein communities and disease networks. Nature. 545 (7655), 505-509 (2017).
- Kumar, D., Yadav, A. K., Dash, D. Choosing an Optimal Database for Protein Identification from Tandem Mass Spectrometry Data. Proteome Bioinformatics. , 17-29 (2017).
- Jeong, K., Kim, S., Bandeira, N. False discovery rates in spectral identification. BMC Bioinformatics. 13 (Suppl 16), (2012).
- Brunet, M. A., Levesque, S. A., Hunting, D. J., Cohen, A. A., Roucou, X. Recognition of the polycistronic nature of human genes is critical to understanding the genotype-phenotype relationship. Genome Research. , (2018).
- Brent, M. R. Genome annotation past, present, and future: how to define an ORF at each locus. Genome Research. 15 (12), 1777-1786 (2005).
- Harrow, J., et al. GENCODE: The reference human genome annotation for The ENCODE Project. Genome Research. 22 (9), 1760-1774 (2012).
- Samandi, S., et al. Deep transcriptome annotation enables the discovery and functional characterization of cryptic small proteins. eLife. 6, e27860 (2017).
- Saghatelian, A., Couso, J. P. Discovery and characterization of smORF-encoded bioactive polypeptides. Nature Chemical Biology. 11 (12), 909-916 (2015).
- Delcourt, V., Staskevicius, A., Salzet, M., Fournier, I., Roucou, X. Small Proteins Encoded by Unannotated ORFs are Rising Stars of the Proteome, Confirming Shortcomings in Genome Annotations and Current Vision of an mRNA. Proteomics. , (2017).
- Plaza, S., Menschaert, G., Payre, F. In Search of Lost Small Peptides. Annual Review of Cell and Developmental Biology. 33 (1), (2017).
- Brunet, M. A., et al. OpenProt: a more comprehensive guide to explore eukaryotic coding potential and proteomes. Nucleic Acids Research. , (2018).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2016 update. Nucleic Acids Research. 44 (W1), W3-W10 (2016).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucleic Acids Research. 46, W537-W544 (2018).
- Sturm, M., et al. OpenMS – An open-source software framework for mass spectrometry. BMC Bioinformatics. 9 (1), 163 (2008).
- Carithers, L. J., et al. A Novel Approach to High-Quality Postmortem Tissue Procurement: The GTEx Project. Biopreservation and Biobanking. 13 (5), 311-319 (2015).
- Aebersold, R., Mann, M. Mass spectrometry-based proteomics. Nature. 422 (6928), 6928 (2003).
- Domon, B., Aebersold, R. Mass Spectrometry and Protein Analysis. Science. 312 (5771), 212-217 (2006).
- Hu, J., Coombes, K. R., Morris, J. S., Baggerly, K. A. The importance of experimental design in proteomic mass spectrometry experiments: Some cautionary tales. Briefings in Functional Genomics. 3 (4), 322-331 (2005).
- Wu, P. Y., Phan, J. H., Wang, M. D. Assessing the impact of human genome annotation choice on RNA-seq expression estimates. BMC Bioinformatics. 14 (11), S8 (2013).
- Mellacheruvu, D., et al. The CRAPome: a contaminant repository for affinity purification-mass spectrometry data. Nature Methods. 10 (8), 730-736 (2013).
- Adusumilli, R., Mallick, P. Data Conversion with ProteoWizard msConvert. Proteomics: Methods and Protocols. , 339-368 (2017).
- French, W. R., et al. Wavelet-Based Peak Detection and a New Charge Inference Procedure for MS/MS Implemented in ProteoWizard’s msConvert. Journal of Proteome Research. 14 (2), 1299-1307 (2015).
- Kuenzi, B. M., et al. APOSTL: An Interactive Galaxy Pipeline for Reproducible Analysis of Affinity Proteomics Data. Journal of Proteome Research. 15 (12), 4747-4754 (2016).
- Hoekman, B., Breitling, R., Suits, F., Bischoff, R., Horvatovich, P. msCompare: a framework for quantitative analysis of label-free LC-MS data for comparative candidate biomarker studies. Molecular & Cellular Proteomics: MCP. 11 (6), (2012).
- Bjornson, R. D., et al. X!!Tandem, an improved method for running X!tandem in parallel on collections of commodity computers. Journal of Proteome Research. 7 (1), 293-299 (2008).
- Kim, S., Pevzner, P. A. MS-GF+ makes progress towards a universal database search tool for proteomics. Nature Communications. 5, 5277 (2014).
- Vaudel, M., Barsnes, H., Berven, F. S., Sickmann, A., Martens, L. SearchGUI: An open-source graphical user interface for simultaneous OMSSA and X!Tandem searches. Proteomics. 11 (5), 996-999 (2011).
- Shteynberg, D., Nesvizhskii, A. I., Moritz, R. L., Deutsch, E. W. Combining results of multiple search engines in proteomics. Molecular & Cellular Proteomics: MCP. 12 (9), 2383-2393 (2013).
- Bittremieux, W., et al. Quality control in mass spectrometry-based proteomics. Mass Spectrometry Reviews. 37 (5), 697-711 (2018).
- Bertsch, A., Gröpl, C., Reinert, K., Kohlbacher, O. OpenMS and TOPP: Open Source Software for LC-MS Data Analysis. Data Mining in Proteomics: From Standards to Applications. , 353-367 (2011).
- Pfeuffer, J., et al. OpenMS – A platform for reproducible analysis of mass spectrometry data. Journal of Biotechnology. 261, 142-148 (2017).
- Kozak, M. Pushing the limits of the scanning mechanism for initiation of translation. Gene. 299 (1-2), 1-34 (2002).
- Noderer, W. L., et al. Quantitative analysis of mammalian translation initiation sites by FACS-seq. Molecular Systems Biology. 10, 748 (2014).
- Eyckerman, S., et al. Intelligent Mixing of Proteomes for Elimination of False Positives in Affinity Purification-Mass Spectrometry. Journal of Proteome Research. 15 (10), 3929-3937 (2016).
- Vizcaíno, J. A., et al. 2016 update of the PRIDE database and its related tools. Nucleic Acids Research. 44 (D1), D447-D456 (2016).
- Bateman, A., et al. UniProt: the universal protein knowledgebase. Nucleic Acids Research. 45 (D1), D158-D169 (2017).
- The Gene Ontology Consortium Expansion of the Gene Ontology knowledgebase and resources. Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Research. 45 (D1), D331-D338 (2017).
- O’Leary, N. A., et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation. Nucleic Acids Research. 44, D733-D745 (2016).
- Zerbino, D. R., et al. Ensembl 2018. Nucleic Acids Research. 46 (D1), D754-D761 (2018).
- Andreev, D. E., et al. Translation of 5’ leaders is pervasive in genes resistant to eIF2 repression. eLife. 4, e03971 (2015).
- Jackson, R., et al. The translation of non-canonical open reading frames controls mucosal immunity. Nature. 564, 434-438 (2018).
Перепечатки и разрешения
Запросить разрешение на использование текста или рисунков этого JoVE статьи
Запросить разрешениеThis article has been published
Video Coming Soon
Авторские права © 2025 MyJoVE Corporation. Все права защищены