
Method Article
질량 분석 기반 Proteomics 분석 소설 단백질을 공개할 OpenProt 데이터베이스를 사용 하 여 비 정식 열려있는 독서 프레임에서 번역
요약
OpenProt는 진 핵 게놈의 polycistronic 모델 적용 자유롭게 액세스할 수 있는 데이터베이스입니다. 질량 분석 데이터 집합을 심문 하는 때 여기, 선물이 OpenProt 데이터베이스의 사용에 대 한 프로토콜. OpenProt를 사용 하 여 proteomic 실험의 분석을 위해 데이터베이스 소설과 이전 탐지 단백질의 발견에 대 한 수 있습니다.
초록
게놈 주석 proteomic 프리의 윤곽을 그리는 대로 오늘날의 proteomic 연구 중심입니다. 오픈의 전통적인 모델 두 개의 임의의 기준 부과 프레임 (ORF) 주석 읽기: 100 codons 그리고 사본 당 단일 ORF의 최소 길이. 그러나, 연구의 증가 보고 혐의 비 코딩에서 단백질의 표현 영역, 현재 게놈 주석의 정확도 도전. 이러한 소설 단백질을 발견 했다 비 코딩 RNAs, 5' 또는 3' 내에서 mRNAs, 또는 대안 ORF에에서 알려진된 코딩 시퀀스 (CD)를 중복 되지 않은 지역 (Utr) 인코딩됩니다. OpenProt는 polycistronic 모델 진 핵 게놈을 적용 하는 첫 번째 데이터베이스 사본 당 여러 ORFs의 주석. OpenProt 자유롭게 액세스할 수 이며 10 종에서 단백질 시퀀스의 사용자 정의 다운로드를 제공 합니다. OpenProt를 사용 하 여 데이터베이스 proteomic 실험 소설 단백질 검색 및 진 핵 유전자의 polycistronic 특성을 강조 합니다. OpenProt 데이터베이스 (모든 예측 단백질)의 크기는 상당한 고 분석에 대 한 계정에 주의가 필요. 그러나, 적절 한 틀린 발견 비율 (FDR) 설정 또는 제한 된 OpenProt 데이터베이스를 사용 하 여, 사용자 proteomic 풍경의 현실적 보기를 얻을 것 이다. 전반적으로, OpenProt는 자유롭게 사용할 수 있는 도구입니다 proteomic 발견을 육성 합니다.
서문
지난 수 십년 동안 질량 분석 (MS-) 기반 단백질 해독 진 핵 세포1,2,3,,45proteomes 황금 기술 되고있다. 이 방법은 가능성6,,78의 범위를 설명 하는 참조 단백질 시퀀스 데이터베이스를 생성 하기 위해 현재 게놈 주석에 의존 합니다. 그러나, 게놈 주석 ORF 주석 100 codons와 사본9,10당 단일 ORF의 최소 길이 같은 대 한 임의의 기준을 잡으십시오. 연구의 증가 현재 주석 모델 도전 및 진 핵 게놈8,,1112,13, unannotated 기능 ORFs의 발견을 보고 14. 이 비 발한 단백질에 인코딩된 혐의로 비 코딩 RNAs 발견, 5' 또는 3' 번역 mRNAs, 또는 다른 프레임에 정식 코딩 시퀀스 (cCDS) 중복의 영역 (UTR). 대부분 이러한 발견의 serendipitous 되었습니다, 하지만 그들은 현재 게놈 주석의 주의 사항 및 진 핵 유전자8의 polycistronic 특성을 보여줍니다.
여기, 우리는 MS 기반 proteomics에 대 한 OpenProt 데이터베이스를 사용 하 여 강조 표시합니다. OpenProt 진 핵 transcriptomes 위한 polycistronic 주석 모델을 보유 하는 첫 번째 데이터베이스입니다. 그것은 www.openprot.org15에서 자유롭게 이용하실 수 있습니다. 이들의 비율 ORFs 있을 것 예상 무작위와 이외의 기능을, 그래서 OpenProt 자신감 증가를 실험 하 고 기능적인 증거를 축적. 실험적인 증거 (MS)에 의해 단백질 표정 등 번역 증거 (리보솜 프로 파일링)15. 기능 증거 (와 함께 한에-접근 같은 편집증) 단백질 orthology 및 기능 도메인 예측15포함 됩니다.
OpenProt 맞춤 데이터베이스를 잘 지원 되 단백질만을 포함 하에서 여러 데이터베이스를 다운로드 하는 가능성을 제공 합니다. 여기, 우리 OpenProt 데이터베이스의 사용에 대 한 파이프라인을 발표할 예정 이다 실험적인 목적을 고려 선택 하는 데이터베이스에 대 한 통찰력을 제공할 것입니다. 그것은 오픈-액세스 및 사용 하기 쉬운, 하지만 데이터베이스 모든 워크플로16,,1718작업할 수 있습니다 여기 proteomics 분석 파이프라인은 프레임 워크에서 지원 됩니다. 우리 또한 proteomic 프리의 더 완전 한 보기를 제공할 것입니다 소설 단백질 양 사용 OpenProt 데이터베이스에서 검색에 추가 정보를 수집 및 proteomics와 바이오 마커의 발견을 촉진을 위한 OpenProt 웹사이트를 사용 하는 방법 제시 현재 방법 보다는 좀 더 체계적인 방법.
MS 데이터 집합; 심문 때이 프로토콜 OpenProt 데이터베이스15 의 사용을 강조 그것은 디자인을 검토 하지 것 이다 실험의 자체, 철저 하 게 되었습니다 검토20,,2122다른 곳. 완전히 오픈 소스를 유지 하기 위해, 프로토콜은 자유롭게 사용할 수 있는 (보충 자료 S1-S4). 쉽게 읽기에 대 한 모든 용어 사용 OpenProt에 의하여이 프로토콜을 통해 표 1에 정의 됩니다.
프로토콜
1. OpenProt 데이터베이스 다운로드
참고: RNA-seq 데이터에 기반 하는 사용자 지정 데이터베이스 예를 또한 얻을 수 있습니다 하 고 절차는이 프로토콜의 두 번째 섹션에 자세히 설명 되어. 사용자 지정 데이터베이스는 필요한 경우, 제발 다음 섹션으로 건너뜁니다.
- OpenProt 웹사이트에가 서: www.openprot.org 및 오픈 톱 페이지 메뉴에서 링크를 사용 하 여 다운로드 페이지.
- 분석된 실험 데이터에 따라 관심의 종류를 클릭 하십시오.
- 원하는 단백질 종류를 클릭 하십시오.
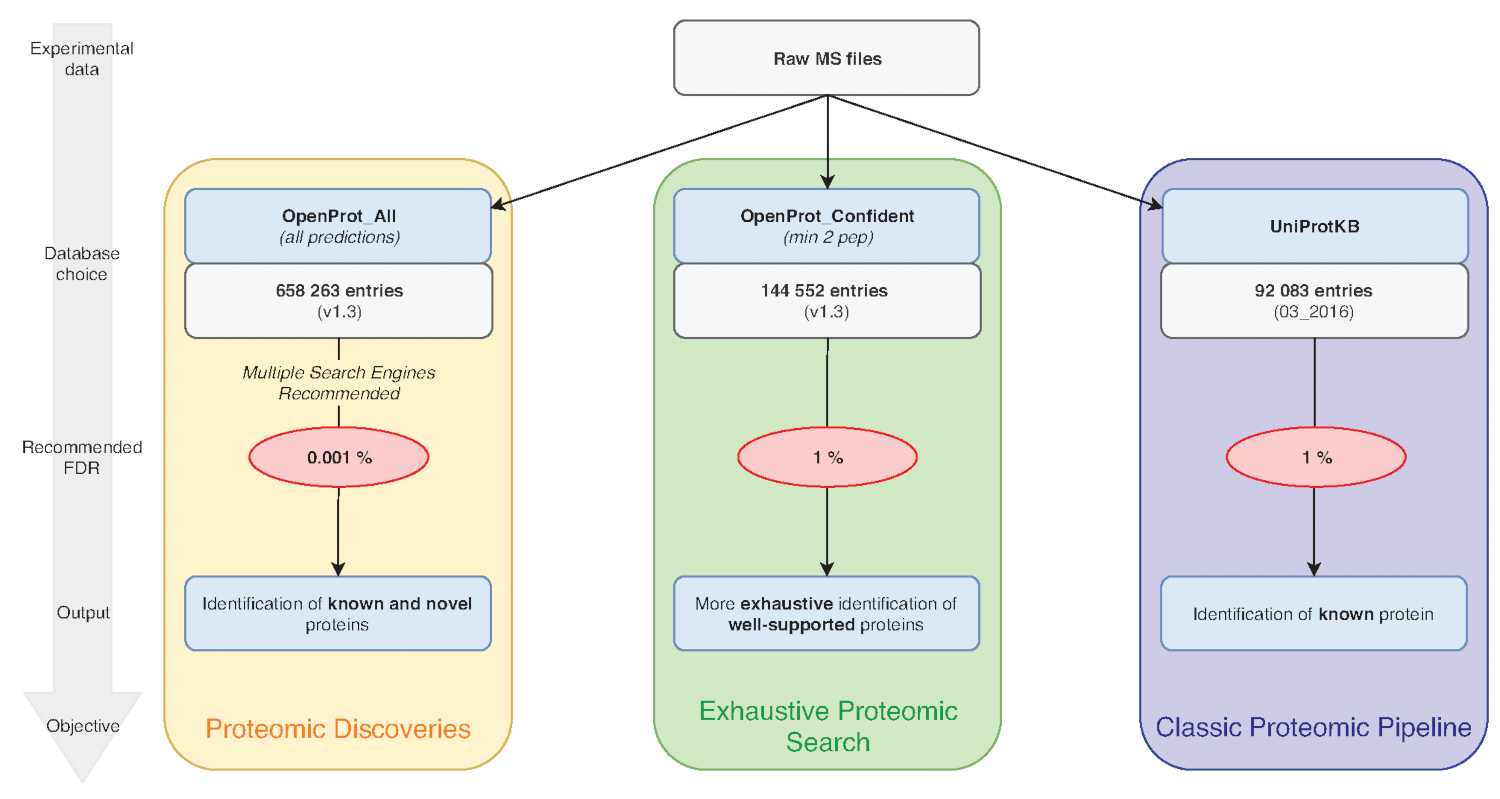
참고: OpenProt 3 개의 분류를 제공 합니다: RefProt, Isoforms 및 AltProt. 그림 1에서 보듯이이 매개 변수는 연구 목적에 따라 달라 집니다.- RefProt 혼자 만 알려진된 단백질을 포함 하는 파일을 생성 하려면 클릭 하십시오.
- 클릭 AltProt 및 Isoforms만 소설 단백질-알려진된 단백질 (Isoforms)의 어느 소설 isoforms를 포함 하거나 대안 ORF (AltProts)에 의해 파일을 생성 합니다. OpenProt 30 codons15의 최소 ORF 길이 적용 note 하시기 바랍니다.
- Isoforms, AltProts, RefProts OpenProt 데이터베이스-알려진된 소설 단백질에에서 있는 모든 단백질 종류를 포함 하는 파일 생성을 클릭 하십시오.
- 사용 가능한 경우는 단백질 시퀀스 그려집니다 주석을 클릭 합니다.
참고: OpenProt 여러 주석을 결합 하 여 더 철저 한 proteomic 풍경을 제공 합니다. Transcriptome 주석을 최소한의 오버랩; 따라서, 선택 된 주석 시각된 proteomic 프로필15,23에 영향을 크게 수 있습니다. - 단백질 고려에 필요한 증거를 지원의 수준을 클릭 하십시오. 그림 1에서 보듯이이 매개 변수는 연구 목적에 따라 달라 집니다.
- 감지 하는 두 개의 독특한 펩 티 드의 최소 가장 자신감 단백질만을 포함 하는 파일을 생성을 클릭 합니다.
참고: 두 개의 독특한 펩 티 드의 기준 현재 여겨진다 단백질 표정에 대 한 proteomics에 있는 황금 표준. 실험 목표 알려지고 잘 지원 되 단백질을 검출 하는 것입니다,이 매개 변수를 사용 하 여 것이 좋습니다. - 클릭 감지 하는 하나의 독특한 펩 티 드의 최소 OpenProt에 의해 다시 분석 하는 질량 분석 실험 사이에서 이미 한 번 이상 본 되었습니다 단백질을 포함 하는 파일을 생성 합니다.
참고: 짧은 길이 AltProts 그리고 그들 중 일부는 하나의 독특한 tryptic 펩 티 드8,11에 포함 될 수 있습니다 가능성의 고려에 대 한 수 있습니다. - 모든 예측 OpenProt 예측의 모든 포함 된 파일을 생성 클릭 하십시오.
참고:이 설정은 좋습니다만 실험 목표는 소설 단백질 (그림 1)을 발견 하는 경우. 7,15아래 설명한 대로 적응된 분석 파이프라인에 대 한 검색 공간 호출 이후 상당한 증가.
- 감지 하는 두 개의 독특한 펩 티 드의 최소 가장 자신감 단백질만을 포함 하는 파일을 생성을 클릭 합니다.
- 다운로드를 원하는 파일 형식을 클릭 합니다. Proteomic 분석, Fasta (단백질) 파일을 선택 합니다. 추가 정보 파일은 파일 형식에 대 한 모든 필요한 정보를 포함합니다.
2. 사용자 지정 OpenProt 데이터베이스 다운로드
참고:이 섹션에서는 사용자 지정 데이터베이스를 얻을 하는 방법을 자세히 설명 합니다. 사용자 지정 데이터베이스가 필요한 경우 다음 섹션으로 건너뜁니다.
- OpenProt 웹사이트 (www.openprot.org)에 고 톱 페이지 메뉴에서 링크를 사용 하 여 검색 페이지를 엽니다.
- 실험 데이터 분석에 따라 관심의 종류를 클릭 하십시오.
- 유전자 또는 성적 관심의 목록을 입력 합니다.
- 유전자의 목록을 사용 하 여, 유전자 쿼리 상자에 입력 합니다.
- 성적 증명서의 목록을 사용 하 여 때 사본 쿼리 상자에 입력 합니다.
- 원하는 데이터베이스에 적용 되는 상자 똑 딱.
- OpenProt에서 지 원하는 단백질의 모든 종류를 포함 하는 표를 어떤 상자에서 클릭 하지 마십시오: Isoforms, RefProt, AltProts.
- MS에 의해 한 번 이상 검색 된 단백질 (RefProts, Isoforms 및 AltProts)의 모든 종류를 포함 하는 테이블을 얻기 위해 실험 증거와 단백질만 표시 클릭 및 어떤 번역에 대 한 증거 수집 리보솜에서 데이터 프로 파일링.
- 마찬가지로, MS에 의해 감지 단백질만 쇼 에 또는 MS 또는 리보솜 각각 프로 파일링 하 여 한 번 이상 검색 된 단백질의 모든 종류를 포함 하는 테이블을 얻으려면 리보솜 프로 파일링에 의해 감지 단백질만 표시 를 클릭 합니다.
- 표시만 AltProts 또는 AltProts 또는 Isoforms를 각각 포함 하는 테이블을 얻으려고 만 isoforms를 표시 를 클릭 합니다.
- 모두 AltProts만을 표시 하 고 표시만 Isoforms 단백질의 두 종류를 포함 하는 테이블을 클릭 합니다.
참고: 필터의 모든 조합 수 있습니다.
- 모든 원하는 매개 변수가 설정 되 면 검색을 클릭 하십시오. 테이블 출력 검색 쿼리 필드 아래에 표시 됩니다.
- 출력 테이블의 오른쪽 상단 모서리에 있는 다운로드 Fasta 버튼 클릭 합니다. Fasta 파일 유전자 또는 성적 증명서의 쿼리 목록에서 발생 하는 모든 단백질을 포함 하는 생성 됩니다.
- 참고로 전산 이유로 OpenProt 2000 요소 최대 보유 (유전자 또는 성적 증명서)를 한 번에 쿼리. 해당 제한 위의 목록 경우 여러 fasta 수 있습니다 생성 하 고 (같이 아래) 연결; 또는 단순히 전체 OpenProt 데이터베이스를 다운로드 하 고 원하는 대로 얻은 파일을 필터링 합니다.
- 유전자 또는 성적표의 전체 목록을 2000 항목의 하위 목록에 빈. 각 하위 목록에 대 한 (단계 3.3 3.6) 위에서 설명한 대로 Fasta 파일을 다운로드 합니다.
- 로그인 유럽은 인스턴스 (또는 단백체학 도구를 사용할 수 있는 다른 모든 인스턴스), https://usegalaxy.eu/.
- 새로운 역사를 만들고 화면의 왼쪽된 상단에서 업로드 로고를 클릭 하 여 모든 다운로드 OpenProt 데이터베이스 (유전자 또는 성적 증명서의 하위 목록 당 하나)을 가져옵니다.
- GalaxyP 개발자 (https://github.com/galaxyproteomics/)에 의해 개발 된 Fasta 병합 파일 및 필터 고유한 시퀀스 도구를 사용 합니다. 모든 Fasta 병합 옵션을 선택 하 고 가져온된 OpenProt 데이터베이스의 모든 입력.
참고: 각 도구는 화면 왼쪽에 쿼리 상자를 사용 하 여 검색할 수 있습니다. - 시퀀스 unicity을 평가 하 고 OpenProt 식별자 구문 분석 규칙을 복사 하려면 만 가입 옵션을 선택 (>(.*) \ |), 다음 실행을 클릭 합니다.
- Note 아무 중복 이제 화면 오른쪽에 역사 패널에 나타나는 모든 파일 독특한 Fasta 파일에 연결 되어 있다. 이 작업 데이터베이스를 구성합니다.
3. 데이터베이스 처리
참고: 이제 갤럭시 플랫폼을 사용 하지만 다른 proteomic 소프트웨어에 동일한 원칙을 적용할 수 있습니다.
- 로그인 유럽은 인스턴스 (또는 단백체학 도구를 사용할 수 있는 다른 모든 인스턴스), https://usegalaxy.eu/.
- 새로운 역사를 만들고 화면의 왼쪽된 상단에서 업로드 로고를 클릭 하 여 다운로드 한 OpenProt 데이터베이스를 가져올 합니다.
- 워크플로 페이지에가 고 왼쪽된 상단의 중간 패널에서 업로드 로고를 클릭 하 여 데이터베이스 처리 워크플로 (보충 자료 S1)를 가져옵니다.
- 워크플로 실행 에서 클릭 하 고 입력으로 가져온된 OpenProt 데이터베이스를 선택 합니다.
참고:이 워크플로 OpenProt fasta에 CRAPome 저장소를 추가 하 고 미끼 시퀀스 (역방향 시퀀스)24를 생성할 것 이다. 셔플 미끼 목록이 필요한 경우 DecoyDatabase 도구에이 매개 변수를 변경 하 여 수행할 수 있습니다. - 뭔가 의미 있는 얻은 Fasta 파일을 이름을 바꿉니다. 데이터베이스를 proteomics 분석에 사용할 수 있습니다.
4. 질량 분석 파일 준비
참고: 대부분의 proteomics 도구 갤럭시 인스턴스에서 사용할 수 있는 mzML 형식을 사용 하 고 데이터 중심 모드에서를 선호 하는 펩 티 드 검색 엔진.
- ProteoWizard 스위트에서 자유롭게 사용할 수 있는 MSConvert 도구를 열고 데이터 파일 분석된25을 업로드.
- 출력 및 mzML 원하는 파일 형식에 대 한 디렉터리를 선택 하십시오.
- 피크 따기 MS1 MS2 수준에 (CWT) 웨이 블 릿 기반 알고리즘을 사용 하 여 필터를 설정 하 고 변환26시작.
5. 펩타이드와 단백질 식별/정량화
참고:이 부분의 파이프라인 OpenMS 스위트, 다양 하 고 사용 하기 쉬운 프레임 워크18에서 도구를 사용합니다.
- 로그인 유럽은 인스턴스 (또는 단백체학 도구를 사용할 수 있는 다른 모든 인스턴스), https://usegalaxy.eu/.
- 새로운 역사를 만들고 드래그 앤 드롭이 새로운 역사를 이전에 만든된 데이터베이스 (3.5 단계)를 전송 합니다.
- 화면 왼쪽된 상단에서 업로드 로고를 클릭 하 여 변환 된 mzML 데이터 파일을 (4.3 단계)를 가져옵니다.
- 워크플로 페이지에가 고 왼쪽된 상단의 중간 패널에서 업로드 로고를 클릭 하 여 원하는 워크플로 가져옵니다.
참고: MS 실험 다르게 설계 되었습니다 원하는 최종 출력에 따라. 여기에 제공 된 워크플로 두 자주 디자인: 안정 동위 원소 라벨 (SIL)을 기반으로 단백질 식별 및 단백질 정량화. 그러나, 갤럭시 인스턴스 proteomic 분석27,28의 다른 종류를 지 원하는 것 이다 다른 많은 도구를 포함 합니다.- 단백질 식별 디자인에 대 한 보충 자료 s 2에서 제공 하는 워크플로 가져옵니다. 이 워크플로 사용 하는 경우 사용 하지 마십시오 zlip 압축 파일 (4.2 단계)를 변환할 때
- 안정 동위 원소 라벨 디자인에 따라 단백질 정량화, 보충 자료 s 3에서 제공 하는 워크플로 가져와야 합니다.
- 워크플로 실행 을 선택 하 고 다른 매개 변수를 검토 합니다.
- 입력 및 데이터베이스 Fasta 파일로 이전에 만든된 데이터베이스 (3.5 단계)으로 가져온된 mzML 데이터 파일을 선택 합니다.
- 워크플로 사용 X! 연동 검색 엔진, X를 가져오기! 협동 기본 구성 파일 ( 보충 자료 s 4에서 제공 하는)29 화면의 왼쪽된 상단에서 업로드 로고를 클릭 하 여.
- 워크플로 사용 하 여 여러 개의 검색 엔진 (MS-GF +와 X! 탠덤)입니다. 다른 검색 엔진을 추가 하거나 추가 하거나 워크플로30,31에서 도구를 제거 하 여 간단 하 게 하나 하나를 선택 합니다.
참고: 여러 검색 엔진을 사용 하 여 것이 좋습니다 감 성과 분석32의 감도 증가. - 때 전체 OpenProt 데이터베이스를 사용 하 여 크기에 상당한 증가 대 한 계정, 엄격한 루즈벨트15사용. 기본적으로 제공 된 워크플로 0.001% 설정 되어 루즈벨트, 전체 OpenProt 데이터베이스의 사용에 대 한 적절 한. 다른 데이터베이스에 대해 원하는 값을 편집할 수 있습니다.
참고: 사용 하는 질량 분 서 계에 따라 다른 도구와 실험 프로토콜 (선구자 이온 및 조각 오류, 고정 및 변수 수정, 사용 된 효소, 등) 매개 변수를 적용 해야 합니다.
- 필요에 따라 역사 패널에서 선택한 단계에 클릭 한 다음 저장 로고 아래에 표시 됩니다를 클릭 하 여 저장 또는 품질 관리 분석에 대 한 워크플로의 각 단계에 대 한 출력을 다운로드 합니다.
6입니다. 품질 관리
참고: MS 기반 proteomics 각 단계 재현할 결과 생산 하기 위해 최적화 해야 하는 복잡 한 프로세스의 결과 이므로 품질 관리 워크플로33에 필요한 절차입니다.
- 몇몇 통계는 성능, 펩 티 드-스펙트럼 일치 (PSM), 확인 된 펩 티 드와 단백질의 수 수 등의 일반적인 벤치 마크. 이러한 통계를 제공 하는 IDFilter 출력 (그린 그림2에서에 표시 된)에 파일 정보 도구를 실행 합니다.
- 비록 모든 식별 된 특히 큰 데이터 집합에 적용 되지 않습니다 새로운 단백질의 보고 한다 항상 신중 하 게 평가. 단백질 점수, 시퀀스 범위, 및 발견을 지 원하는 스펙트럼의 검사는 중요 한 중요성의 이다. OpenMS 프레임 워크에서 TOPPview 도구를 사용 하 여 이렇게; 그것은 자유롭게 사용할 수 하 고 잘 문서화18,,3435.
7. OpenProt 데이터베이스 마이닝
참고: OpenProt (소설 Isoforms를 위한 AltProts 및 II_ IP_로 시작 하는 가입 숫자)에 의해 예측 하는 소설 단백질의 id를 확신 했다, 일단 더 많은 생물 학적 정보에서 OpenProt 웹사이트15수집 수 있다.
- OpenProt 웹사이트에가 서: www.openprot.org 및 오픈 톱 페이지 메뉴에서 링크를 사용 하 여 검색 페이지.
- (동일 하나는 단백질 확인 되었다) 관심사의 종에 클릭 하 고 쿼리 상자에 단백질 단백질 가입 번호를 입력.
- 검색을 클릭 하 고 쿼리 된 단백질에 대 한 기본 정보를 포함 하는 테이블 표시 됩니다. 테이블 기능: 도메인 및 단백질 (아미노산)에 단백질 길이, 분자량 (kDa)와 같은 MS 또는 리보솜 (번역 증거, 테), 프로 파일링 및 기능 예측 실험 증거를 지 원하는 전자 포인트 예측 orthology (OpenProt에서 지 원하는 10 종에 걸쳐 v1.3). 테이블에는 관련된 유전자와 성적 증명서 사본 내 단백질의 지역화에 대 한 정보가 포함 되어 있습니다.
- 추가 정보를 수집 하는 세부 정보 링크를 클릭 합니다. 새로 열린된 페이지 중심 쿼리 단백질과 정보는 게놈 transcriptomic 좌표와 Kozak 또는 고효율 번역 개시 사이트 (TIS) 모티브36의 존재에는 게놈 브라우저를 포함 37.
- 단백질 또는 DNA 에 단백질 또는 DNA 시퀀스를 각각 얻는 정보 탭 링크를 클릭 합니다.
- MS 증거, 리보솜 검출, 보존 및 확인 된 단백질 도메인15상단 탭 클릭 하 여 프로 파일링에 대 한 자세한 정보를 찾습니다.
결과
위에서 설명한 워크플로 자부심 저장소38,39에서 사용할 수 있는 MS 데이터 집합에 적용 했다. 원래 연구 개발 방법 (iMixPro), 세포 배양 (SILAC)에 있는 아미노산의 안정 동위 원소 라벨을 사용 하 여, 친 화력 정화 MS에서 가양성을 제거 (AP-MS)38실험. 간단히, AP-MS 실험 (미끼) 관심과 그 인터 (먹이)의 단백질을 가져올 구슬 바인딩된 항 체를 사용 하 여 구성 됩니다. 수집 된 단백질 소화 그리고 MS에 대 한 준비는. 샘플 준비 방법 및 악기 설정을 원래 연구에 자부심 저장소 (PXD004246)에 설명 되어 있습니다. 이러한 실험에 도전 구슬만 하지 미끼에 바인딩 단백질에서 특히 잘못 된 반응의 풍부 이다. 여기, 우리는 진정한 먹이 가양성 사이 서로 다른 동위 원소 비율을 생성 하 단기 사용: 3 제어 샘플 (미끼) 가벼운 매체, 빛 매체에 경작 하는 미끼를 표현 1 샘플 및 무거운 매체에 경작 하는 미끼를 표현 1 샘플 양식 구슬 및 추가 질량 분석 분석 처리. 같은 디자인으로 구슬에 바인딩 일반적인 단백질 1:4;의 무거운 빛 비율을 해야한다합니다 때 진정한 먹이 비율 1:138의 있을 것 이다.
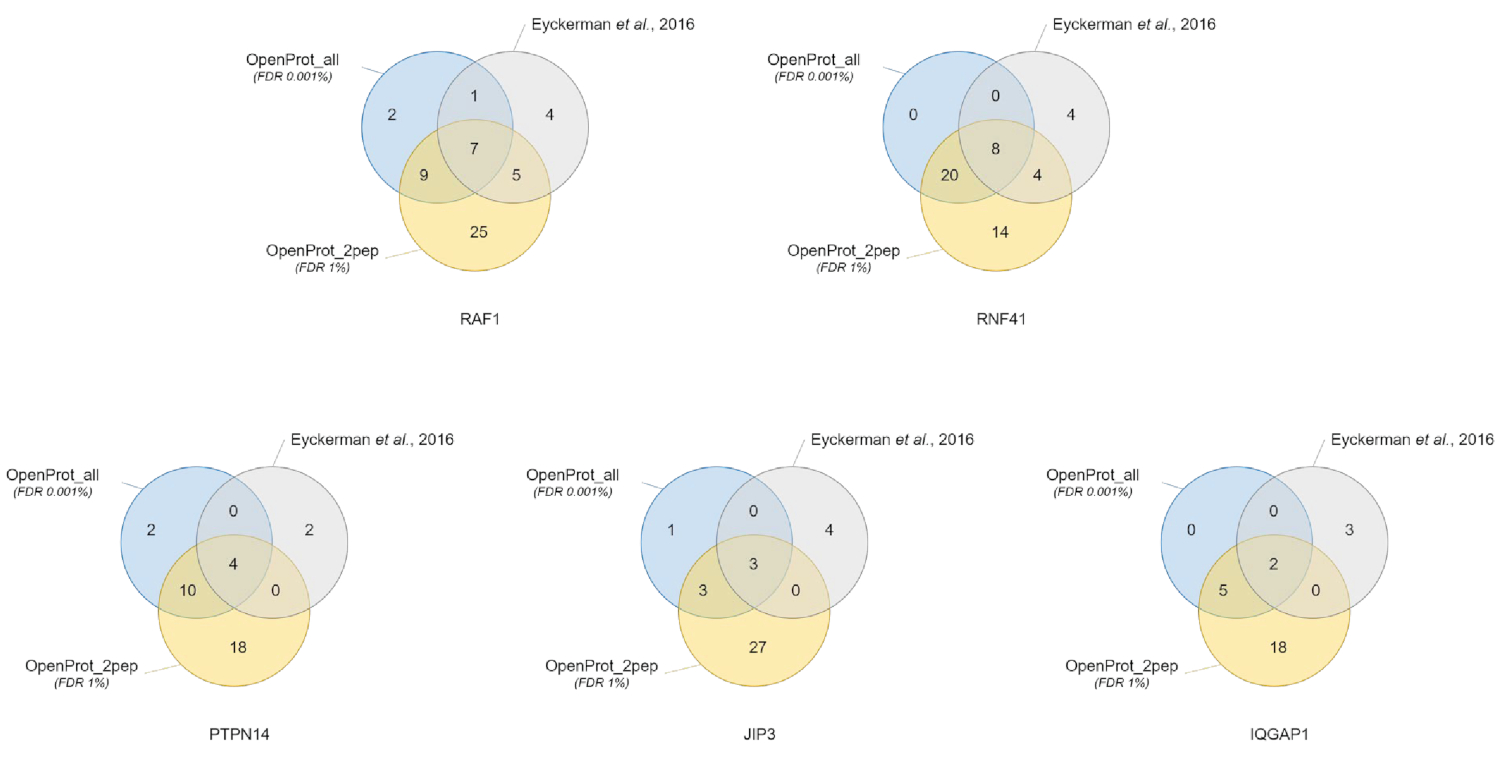
우리는 다시; OpenProt 데이터베이스를 사용 하 여 그들의 AP MS 데이터 분석 미끼 (PTPN14, JIP3 및 IQGAP1), 3 개의 내 생 단백질을 포함 하 고 2-단백질 (RAF1 및 RNF41)을 표현. 단백질 정량화에 대 한 갤럭시 워크플로 사용 되었다 실험 SILAC 사용, (보충 자료 S3, 그림 2). 워크플로 전체 OpenProt 데이터베이스 (OpenProt_all) 또는 제한 된 OpenProt 데이터베이스 (OpenProt_2pep, 이전 2 개의 독특한 펩 티 드의 최소 감지 단백질만을 포함 한)를 사용 하 여 실행 되었습니다.
단백질 식별 및 정량화 되었고 좋은 재현성 다른 사용 데이터베이스. 그림 3에서 보듯이 원래 종이에서 확인 된 대부분의 단백질 (자세한 목록이 보충 자료 S5에서 유효 하다) OpenProt_2pep 또는 OpenProt_all 데이터베이스를 사용 하 여 또한 확인 되었다. 이 결과 여기에 설명 된 파이프라인 및 OpenProt 데이터베이스는 단백질 식별 및 정량화40UniProtKB 데이터베이스 기반 하는 현재 절차의 비교 생산할 수를 보여줍니다. 그러나, OpenProt 데이터베이스를 사용 하 여 공부 같이 경우에 소설과 이전 탐지 단백질의 탐지는 허용의 독특한 장점이 있다.
11 잘 지원 되 단백질 (1 Isoform 및 10 AltProts), 아직 현재 하지에 주석이 추가 된 데이터베이스와 자신감 펩 티 드, OpenProt_2pep 데이터베이스 (모든 단백질 accessions, 지원의 번호와 함께 사용 하 여 모든 데이터 집합에 걸쳐 발견 했다 펩 티 드, 사용할 수 있습니다 보충 자료 S5). 이 데이터베이스에 사용할 수 있습니다 전통적인 1%의 검색 공간 증가 루즈벨트 온건한 유지. 그들은 결 석으로 원래 연구에서이 11 단백질 식별 되지 했다 데이터베이스에서.
29 비 발한 단백질 (16 isoforms 및 13 AltProts)와 자신감 펩 티 드, OpenProt_all 데이터베이스를 사용 하 여 모든 데이터 집합에서 발견 된 (번호와 함께 모든 단백질 accessions 펩 티 드를 지원,은 에서 사용할 수 있는 보조 자료 S6 ). 그림 3에서 보듯이 권장된 엄격한 루즈벨트 미치지 않았다 가장 자신감 단백질 id를 있지만 확인 된 단백질의 총 수를 감소 했다. 비교적 OpenProt_2pep 데이터베이스에 새로운 단백질의 높은 수 식별할 수 있습니다 자신 있게. 이 비 발한 단백질 모두 결 석 OpenProt_2pep 데이터베이스에서. 이 MS 기반 proteomics에 대 한 선택한 데이터베이스의 중요 한 역할을 강조 한다.
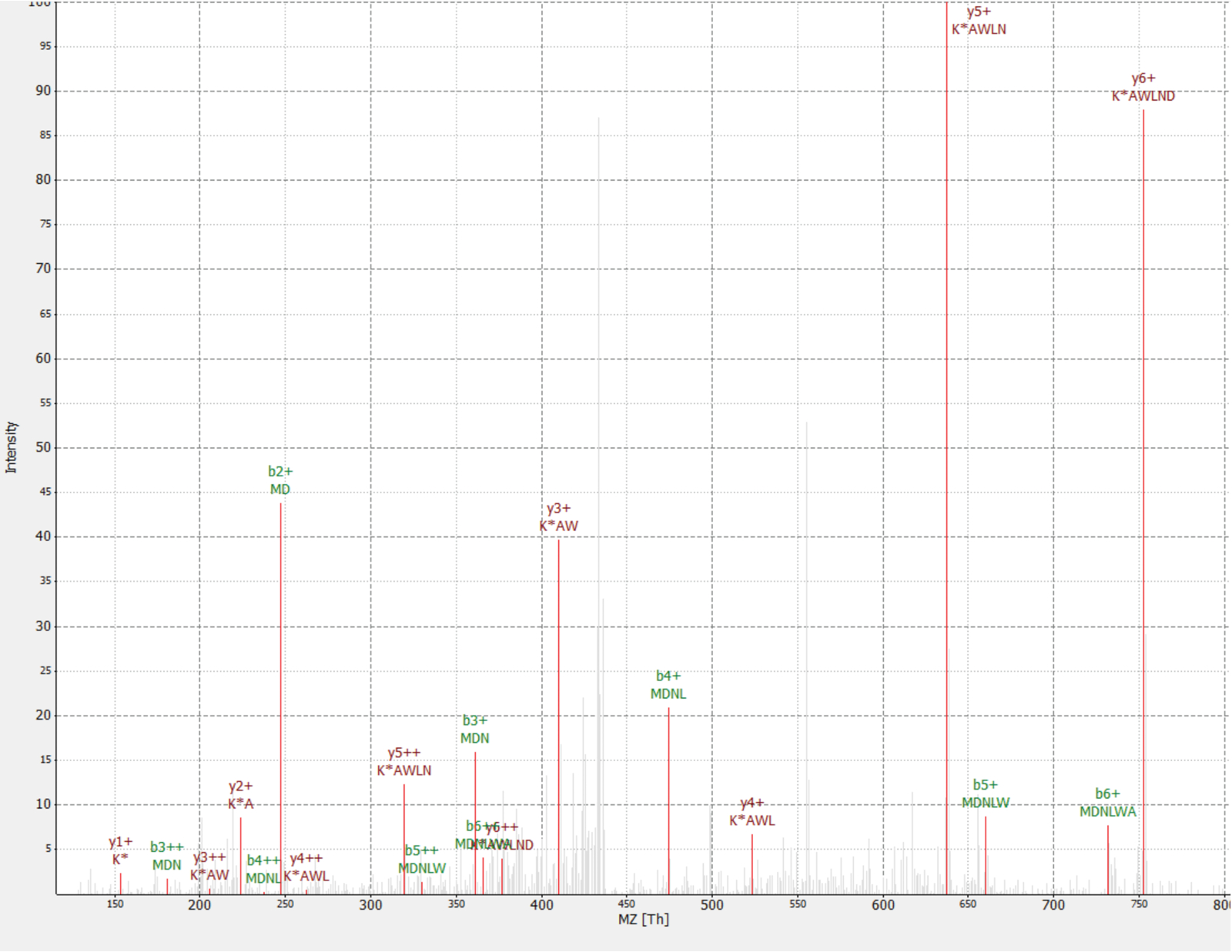
1 소설 단백질 RAF1 단백질 (IP_637643)의 interactor로 발견 되었다. OpenProt 웹사이트를 사용 하 여, 하나는 MS도 지금까지 프로 파일링 리보솜에 의해이 단백질이 발견 되지 했다 볼 수 있습니다 (OpenProt v1.3). 단백질 오랫동안 46 아미노산 이며만 tryptic 소화 시 두 개의 독특한 펩 티 드를 줄 수 있습니다. 검색 된 펩 티 드 RAF1 AP-MS에서 dataset (분수 18) 좋은 품질 스펙트럼을 그림 4와 같이 했다 고 1,09의 무거운 빛 비율 표시. 단백질은 NANOGNB의 pseudogene NANOGNBP1 유전자에 인코딩됩니다. 현재 비 코딩, 주석이 달린 사본 (ENST00000448444), GTEx 포털40에 따라 여러 조직에 걸쳐 발견 되었다. 단백질은 DNA 바인딩 (유전자 온톨로지가: 0003677)41와 관련 된 예측된 기능 도메인을 포함 되어 있습니다.

그림 1 : 데이터베이스 proteomics 분석 차트에 대 한 선택. MS 데이터, 특히 데이터베이스 선택, 분석 연구 목표에 따라 달라 집니다. 세 가지 일반적인 목표는 블루 (고전적인 proteomic 파이프라인), 녹색 (철저 한 proteomic 검색), 오렌지 (proteomic 발견)에 설명 되어 있습니다. 각 목표는 적절 한 데이터베이스 및 파이프라인에 따라 달라 집니다. 철저 한 및 클래식 proteomics에 대 한 단일 식별 도구를 사용할 수 있습니다 파이프라인. Proteomic 디스커버리 파이프라인에 대 한 여러 식별 엔진을 사용 하 여 것이 좋습니다. 권장된 FDRs, 빨간색으로 표시 됩니다 그리고 단백질 데이터베이스 크기 회색 상자에 표시 됩니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭 하십시오.
{kind=link}

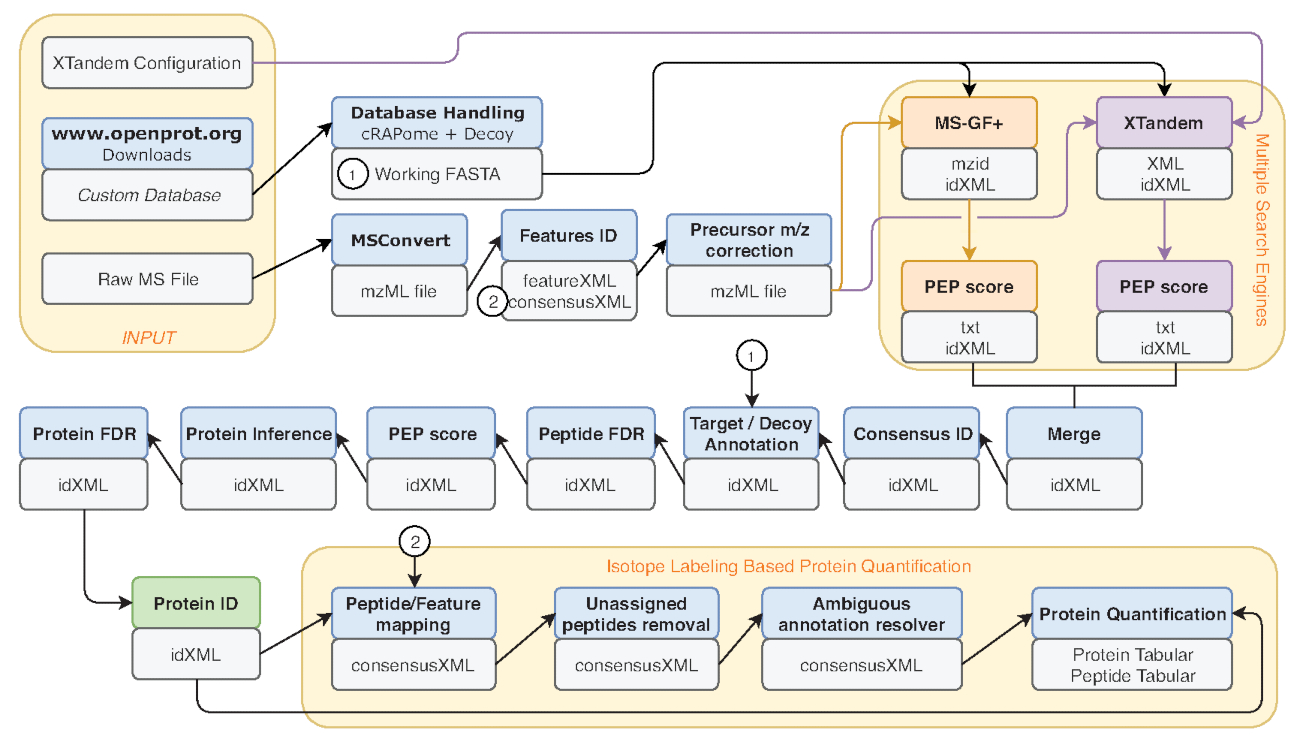
그림 2 : 갤럭시 워크플로 사용의 그래픽 표현. 다시-Eyckerman 그 외 여러분 데이터38의 분석을 위해 사용 proteomic 분석 작업의 단계별 표현입니다. 주황색 상자 입력된 파일, 펩 티 드 검색, 단백질 부 량이 표시 됩니다. 파란색 상자에 해당 도구를 사용 하 고 생성 된 출력 파일에 해당 하는 회색 상자. 다른 검색 엔진 (MS-GF +와 X! 탠덤) 다른 색상 (각각 빨간색과 보라색) 그들의 필요한 입력 및 출력을 나타내는 화살표에 의해 표시 됩니다. 녹색 상자 단백질 신원의 목록을 생성 하는 도구를 강조 표시 합니다. 여러 출력 생성 됩니다 때 다운스트림 단계에 사용 가까운으로 표시 되는 화살표를. 이 워크플로 보충 자료 S2에서 자유롭게 사용할 수 있습니다. X! 협동 기본 매개 변수 구성 파일은 보충 자료 S4가능 합니다. 이 그림의 더 큰 버전을 보려면 여기를 클릭 하십시오.
{kind=link}

그림 3 : 다른 데이터베이스를 사용 하 여 미끼 당 끌어와서 식별의 비교. 루즈벨트, 또는 전체 OpenProt 단백질 식별 가장 자신감 OpenProt을 사용 하 여 벤 다이어그램 1% (오렌지, 최소 2 독특한 펩 티 드, OpenProt_2pep의 증거를 지 원하는)에 데이터베이스 데이터베이스 (블루, OpenProt_all)는 0.001% 루즈벨트, 보고 또는 원래 종이 (회색)에서38. 언급 한 미끼에 대 한 확인 된 인터에 해당 하는 각 다이어그램: RAF1, RNF41, PTPN14, JIP3 및 IQGAP1. 이 그림의 더 큰 버전을 보려면 여기를 클릭 하십시오.
{kind=link}

그림 4 : MS/MS 스펙트럼의 발견 MDNLWAK(13C 6) 비 발한 단백질 IP_637643에서에서 펩 티 드. 상대 강도 (0 ~ 100%)입니다. 선택한 봉우리 y 이온 주석을 녹색에 진한 레드와 b 이온 주석에는 빨간색으로 표시 됩니다. TOPPview 소프트웨어34에서 추출. 선구자 오류 2.70 ppm, 응원 점수 = 0.12 =. 이 그림의 더 큰 버전을 보려면 여기를 클릭 하십시오.
{kind=link}
| 용어 | 정의 | 참조 |
| 대체 ORF (AltORF) | 비정규 ORF 현재 게놈 주석에 주석이 아니라 OpenProt에서 주석. | 15 |
| 참조 ORF (RefORF) | 정식 ORF 게놈 주석 및 OpenProt에서 주석입니다. | 15 |
| 양자 택일 단백질 (AltProt) | RefProt으로 아무 상당한 유사성으로는 AltORF에 의해 암호로 하는 소설 단백질. 가입 접두사: IP_. | 15 |
| 참조 단백질 (RefProt) | 현재 주석 UniProtKB, 합 등 NCBI RefSeq 단백질 시퀀스 데이터베이스와 OpenProt 단백질. | 15 |
| 비 발한 Isoform | RefProt와 상당한 유사성으로는 AltORF에 의해 암호로 하는 소설 단백질. 가입 접두사: II_. | 15 |
| OpenProt_2pep 데이터베이스 | 모든 RefProts 및 OpenProt, 이미 2 독특한 펩 티 드의 최소 감지에 의해 예측 하는 소설 단백질의 시퀀스를 포함 되어 있습니다. | 15 |
| OpenProt_1pep 데이터베이스 | 모든 RefProts 및 OpenProt, 이미 최소 1 고유 펩 티 드의 감지에 의해 예측 하는 소설 단백질의 시퀀스를 포함 되어 있습니다. | 15 |
| OpenProt_all 데이터베이스 | 모든 RefProts 및 OpenProt에 의해 예측 하는 소설 단백질의 시퀀스를 포함 되어 있습니다. | 15 |
표 1: OpenProt에서 사용 하는 프로토콜에 걸쳐 용어의 정의
보충 자료 S1: 데이터베이스 처리에 대 한 갤럭시 워크플로. 이 CRAPome 및 미끼 시퀀스 (역방향) 입력된 데이터베이스에 추가 됩니다. 출력은 Fasta 파일. 다운로드 하려면 여기를 클릭 하십시오.
보충 자료 S2: 단백질 식별은 워크플로. 이 두 개의 검색 엔진을 사용 하 여 질량 분석 데이터 파일에서 단백질을 식별 합니다 (MS-GF +와 X! 탠덤)입니다. 각 매개 변수를 조정 될 수 있다는 워크플로 실행 하기 전에 원하는. 다운로드 하려면 여기를 클릭 하십시오.
보충 자료 S3: 안정 동위 원소 라벨 (SIL)을 사용 하 여 단백질 정량화에 대 한 갤럭시 워크플로. 이것은 식별 되 고 두 개의 검색 엔진을 사용 하 여 질량 분석 데이터 파일에서 단백질을 계량 (MS-GF +와 X! 탠덤)입니다. 각 매개 변수를 조정 될 수 있다는 워크플로 실행 하기 전에 원하는. 다운로드 하려면 여기를 클릭 하십시오.
보조 소재 S4: X! 협동 기본 매개 변수 구성 파일입니다. 이 XML 파일은 X를 실행 하는 데 필요한! TandemAdapter은 플랫폼에 도구. 다운로드 하려면 여기를 클릭 하십시오.
보충 자료 S5: iMixPro 데이터 집합에서 단백질 정량. Eyckerman 외. 201638 에서 데이터 파일 OpenProt 데이터베이스를 사용 하 여 처리 하 고 정량된 단백질 각 조건에 대해 나열 됩니다. Baits 있습니다 PTPN14, JIP3, IQGAP1, RAF1 및 RNF41. 진 이름이 녹색으로 표시 된 단백질 또한 원래 종이38에서 확인에 해당 합니다. 오렌지에서 유전자 이름 하지 원래 종이에서 보고 된 BioGrid에 따르면 알려진된 인터에 해당 합니다. 밝은 파란색으로 표시 된 유전자 이름 인터 (해당 단백질 가입 번호는 괄호 안에 표시 됩니다)로 식별 하는 소설 단백질에 해당 합니다. 유전자 이름 옅은 회색으로 표시 하 고 가능성이 오염 물질 (케 라틴 단백질)에 해당 하는 이탤릭체로 표시. 다운로드 하려면 여기를 클릭 하십시오.
보충 자료 S6: iMixPro 데이터 집합에서 새로운 단백질 발견. Eyckerman 외. 201638 에서 데이터 파일 OpenProt 데이터베이스를 사용 하 여 처리 하 고 소설 확인 된 단백질 각 조건에 대해 나열 됩니다. Baits 있습니다 PTPN14, JIP3, IQGAP1, RAF1 및 RNF41. 단백질 가입 번호가 알려진된 단백질의 비 발한 isoforms 위한 II_와 IP_는 대체 ORF (AltProt)에서 새로운 단백질에 대 한 시작 표시 됩니다. 수 지원 펩 티 드의 괄호 안에 표시 됩니다. 다운로드 하려면 여기를 클릭 하십시오.
토론
질량 분석기에서 데이터를 분석할 때 단백질의 품질은 부분적으로 사용된 데이터베이스6,20의 정확도에 의존 합니다. 현재 접근 전통적으로 UniProtKB 데이터베이스를 사용 하 여 아직 이러한 사본 당 단일 ORF의 게놈 주석 모델 100 codons (를 제외 하 고 이전 시연된 예)40의 최소 길이 지원 합니다. 여러 연구에서 추정 되 게 비 코딩 기능 ORFs의 발견과 같은 데이터베이스의 단점 관련 지역8,11,,1213. 지금, OpenProt 더 완전 한 단백질 식별으로 여러 transcriptome 주석에서 단백질 시퀀스를 그립니다 수 있습니다. NCBI RefSeq (GRCh38.p7)와 합 (GRCh38.83) transcriptomes와 UniProtKB 주석 (UniProtKB-SwissProt, 2017 년 09 월 27 일)을 검색 하는 OpenProt40,,4243. 현재 주석 작은 중복 제시, OpenProt 이렇게 하면 하나의 주석15제한 보다 잠재적인 proteomic 프리의 더 완전 한 보기 표시 됩니다.
또한, OpenProt는 polycistronic 모델을 적용, 그것은 여러 단백질 주석 사본 당에 대 한 허용. 이유로 통계 및 전산, OpenProt는 여전히 30 codons15의 최소 길이 임계값을 보유 하고있다. 그러나, 그것은 예측 함으로써 단백질 식별에 대 한 가능성의 범위를 확대 하는 소설 단백질 시퀀스의 수천. 이 방식으로 OpenProt 더 체계적인 방식으로 proteomic 발견을 지원합니다.
단백질의 품질 또한 사용 되는 매개 변수에 따라 달라질 수 있습니다. MS 기반 proteomics 분석은 일반적으로 1% 단백질 루즈벨트를 개최. 그러나, 전체 OpenProt 데이터베이스에는 약 6 배 더 많은 항목을 (그림 1) 포함 되어 있습니다. 검색 공간에 있는이 상당한 증가 대 한 계정, 0.001%의 더 엄격한 루즈벨트를 사용 하는 것이 좋습니다. 이 매개 변수는 벤치 마크 연구 및 무작위로 선택 된 스펙트럼15의 수동 평가 사용 하 여 최적화 되었다. 가양성 여전히 가능성, 하지만, 그리고 철저 한 검사 및 비 발한 단백질에 대 한 증거를 지원의 유효성 검사를 권합니다. 권장된 표준 배경 데이터 및 가양성 데이터 집합15사이 다 두 개의 다른 MS 실행에서 단백질의 식별 될 수 있습니다.
여기에 제공 된 및 사례 연구에 사용 되는 파이프라인 매개 변수 및 실험 설계에 맞게 만족 수정할 수 있습니다. 우리 감 성과 펩 티 드 식별32의 감도 증가 여러 검색 엔진을 사용 하 여 권해 드립니다. 또한, 우리는 최고의 실험 목표 (그림 1)에 해당 하는 데이터베이스를 사용 하 여 것을 권장 합니다. 엄격한 루즈벨트와 데이터베이스를 제공 전체 OpenProt를 사용 하 여, 진정한 식별 손실 될 수 있습니다. 따라서, 전체 데이터베이스 해야 될 위한 새로운 단백질의 발견 (예: 위의 사례 연구에서 사용 되는 OpenProt_2pep) 작은 OpenProt 데이터베이스 사용 해야 고전적인 단백질 프로 파일링 하는 동안.
OpenProt는 현재 여러 연구 다른 codons44,45번역 개시를 강조 하는 반면 ATG codon로 시작 하는 시퀀스를 예측 합니다. 새로운 단백질은 하나 또는 여러 개의 독특한 펩 티 드 식별, 진실한 개시 코 돈 추정된 ATG 아니다 가능 하다. 사용자가 번역 증거 OpenProt 웹사이트에서 찾을 수 있다. 현재, OpenProt만 보고 번역 이벤트 전체 예측된 단백질 시퀀스 (100% 중복)15를 염려 하는 경우. 따라서, 번역 증거의 부재 것 아닙니다 단백질은 번역 되지 않습니다, 하지만 그 시작 codon 주장된 ATG 하지 않을 수 있습니다.
그것의 현재 한계에도 불구 하 고 OpenProt는 진 핵 게놈 코딩 잠재력의 더 완전 한 보기를 제공합니다. OpenProt 데이터베이스 proteomic 발견 및 proteomic 기능 및 상호 작용의 이해를 육성. 비 ATG에서 번역 증거 시작 codon 그리고 전체 게놈 및 exome 시퀀싱 연구에 새로운 단백질을 포함 하는 파이프라인의 개발, OpenProt 데이터베이스의 미래 발달은 다른 종족의 주석 포함 됩니다.
공개
저자는 관심의 충돌을 선언합니다.
감사의 말
우리는 그의 도움, 토론 및이 작업에 대 한 조언을 위해 비비 안 Delcourt 감사합니다. X.R. Fonds de 검색 뒤 퀘벡 건강 FRQS 지원 센터 드 검색 뒤의 멤버인 센터 Hospitalier 대학 드 셔 브 룩. 이 연구는 X.R. 및 CIHR 그랜트 걸 레-137056 캐나다 연구의 자 기능 Proteomics와 소설 단백질의 발견에 의해 지원 되었다. 우리 퀘벡 거리와 계산 캐나다 대학교 드 룩에서 슈퍼 컴퓨터 mp2의 사용과 그들의 지원에 대 한 팀을 감사합니다. Mp2 슈퍼 컴퓨터의 작동에 의해는 캐나다 재단의 혁신 (CFI), 르 ministère 투자 드 l' 경제학, 드 라 과학 외 드 l'innovation 뒤 퀘벡 (달) 및 레 Fonds de 검색 뒤 퀘벡-자연 외 기술 (FRQ-NT). 일부 proteomics 계산에 사용 된 갤럭시 서버 부분에 공동 연구 센터 992 의료 Epigenetics (DFG 부여 SFB 992/1 2012)과 독일 연방 교육부의 연구 자금 지원 (BMBF 부여 031 A538A/A538C RBC, 031L0101B /031L0101C 드입니다. NBI 피, 031 L 0106 드 계단 (드. NBI))입니다.
자료
| Name | Company | Catalog Number | Comments |
| OpenProt website | open source | n/a | www.openprot.org |
| Galaxy Server | open source | n/a | https://usegalaxy.eu/ |
| TOPPview software | open source | n/a | www.openms.de |
참고문헌
- Kim, M. S., et al. A draft map of the human proteome. Nature. 509 (7502), 575-581 (2014).
- Wilhelm, M., et al. Mass-spectrometry-based draft of the human proteome. Nature. 509 (7502), 582-587 (2014).
- Hein, M. Y., et al. A human interactome in three quantitative dimensions organized by stoichiometries and abundances. Cell. 163 (3), 712-723 (2015).
- Huttlin, E. L., et al. The BioPlex Network: A Systematic Exploration of the Human Interactome. Cell. 162 (2), 425-440 (2015).
- Huttlin, E. L., et al. Architecture of the human interactome defines protein communities and disease networks. Nature. 545 (7655), 505-509 (2017).
- Kumar, D., Yadav, A. K., Dash, D. Choosing an Optimal Database for Protein Identification from Tandem Mass Spectrometry Data. Proteome Bioinformatics. , 17-29 (2017).
- Jeong, K., Kim, S., Bandeira, N. False discovery rates in spectral identification. BMC Bioinformatics. 13 (Suppl 16), (2012).
- Brunet, M. A., Levesque, S. A., Hunting, D. J., Cohen, A. A., Roucou, X. Recognition of the polycistronic nature of human genes is critical to understanding the genotype-phenotype relationship. Genome Research. , (2018).
- Brent, M. R. Genome annotation past, present, and future: how to define an ORF at each locus. Genome Research. 15 (12), 1777-1786 (2005).
- Harrow, J., et al. GENCODE: The reference human genome annotation for The ENCODE Project. Genome Research. 22 (9), 1760-1774 (2012).
- Samandi, S., et al. Deep transcriptome annotation enables the discovery and functional characterization of cryptic small proteins. eLife. 6, e27860 (2017).
- Saghatelian, A., Couso, J. P. Discovery and characterization of smORF-encoded bioactive polypeptides. Nature Chemical Biology. 11 (12), 909-916 (2015).
- Delcourt, V., Staskevicius, A., Salzet, M., Fournier, I., Roucou, X. Small Proteins Encoded by Unannotated ORFs are Rising Stars of the Proteome, Confirming Shortcomings in Genome Annotations and Current Vision of an mRNA. Proteomics. , (2017).
- Plaza, S., Menschaert, G., Payre, F. In Search of Lost Small Peptides. Annual Review of Cell and Developmental Biology. 33 (1), (2017).
- Brunet, M. A., et al. OpenProt: a more comprehensive guide to explore eukaryotic coding potential and proteomes. Nucleic Acids Research. , (2018).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2016 update. Nucleic Acids Research. 44 (W1), W3-W10 (2016).
- Afgan, E., et al. The Galaxy platform for accessible, reproducible and collaborative biomedical analyses: 2018 update. Nucleic Acids Research. 46, W537-W544 (2018).
- Sturm, M., et al. OpenMS – An open-source software framework for mass spectrometry. BMC Bioinformatics. 9 (1), 163 (2008).
- Carithers, L. J., et al. A Novel Approach to High-Quality Postmortem Tissue Procurement: The GTEx Project. Biopreservation and Biobanking. 13 (5), 311-319 (2015).
- Aebersold, R., Mann, M. Mass spectrometry-based proteomics. Nature. 422 (6928), 6928 (2003).
- Domon, B., Aebersold, R. Mass Spectrometry and Protein Analysis. Science. 312 (5771), 212-217 (2006).
- Hu, J., Coombes, K. R., Morris, J. S., Baggerly, K. A. The importance of experimental design in proteomic mass spectrometry experiments: Some cautionary tales. Briefings in Functional Genomics. 3 (4), 322-331 (2005).
- Wu, P. Y., Phan, J. H., Wang, M. D. Assessing the impact of human genome annotation choice on RNA-seq expression estimates. BMC Bioinformatics. 14 (11), S8 (2013).
- Mellacheruvu, D., et al. The CRAPome: a contaminant repository for affinity purification-mass spectrometry data. Nature Methods. 10 (8), 730-736 (2013).
- Adusumilli, R., Mallick, P. Data Conversion with ProteoWizard msConvert. Proteomics: Methods and Protocols. , 339-368 (2017).
- French, W. R., et al. Wavelet-Based Peak Detection and a New Charge Inference Procedure for MS/MS Implemented in ProteoWizard’s msConvert. Journal of Proteome Research. 14 (2), 1299-1307 (2015).
- Kuenzi, B. M., et al. APOSTL: An Interactive Galaxy Pipeline for Reproducible Analysis of Affinity Proteomics Data. Journal of Proteome Research. 15 (12), 4747-4754 (2016).
- Hoekman, B., Breitling, R., Suits, F., Bischoff, R., Horvatovich, P. msCompare: a framework for quantitative analysis of label-free LC-MS data for comparative candidate biomarker studies. Molecular & Cellular Proteomics: MCP. 11 (6), (2012).
- Bjornson, R. D., et al. X!!Tandem, an improved method for running X!tandem in parallel on collections of commodity computers. Journal of Proteome Research. 7 (1), 293-299 (2008).
- Kim, S., Pevzner, P. A. MS-GF+ makes progress towards a universal database search tool for proteomics. Nature Communications. 5, 5277 (2014).
- Vaudel, M., Barsnes, H., Berven, F. S., Sickmann, A., Martens, L. SearchGUI: An open-source graphical user interface for simultaneous OMSSA and X!Tandem searches. Proteomics. 11 (5), 996-999 (2011).
- Shteynberg, D., Nesvizhskii, A. I., Moritz, R. L., Deutsch, E. W. Combining results of multiple search engines in proteomics. Molecular & Cellular Proteomics: MCP. 12 (9), 2383-2393 (2013).
- Bittremieux, W., et al. Quality control in mass spectrometry-based proteomics. Mass Spectrometry Reviews. 37 (5), 697-711 (2018).
- Bertsch, A., Gröpl, C., Reinert, K., Kohlbacher, O. OpenMS and TOPP: Open Source Software for LC-MS Data Analysis. Data Mining in Proteomics: From Standards to Applications. , 353-367 (2011).
- Pfeuffer, J., et al. OpenMS – A platform for reproducible analysis of mass spectrometry data. Journal of Biotechnology. 261, 142-148 (2017).
- Kozak, M. Pushing the limits of the scanning mechanism for initiation of translation. Gene. 299 (1-2), 1-34 (2002).
- Noderer, W. L., et al. Quantitative analysis of mammalian translation initiation sites by FACS-seq. Molecular Systems Biology. 10, 748 (2014).
- Eyckerman, S., et al. Intelligent Mixing of Proteomes for Elimination of False Positives in Affinity Purification-Mass Spectrometry. Journal of Proteome Research. 15 (10), 3929-3937 (2016).
- Vizcaíno, J. A., et al. 2016 update of the PRIDE database and its related tools. Nucleic Acids Research. 44 (D1), D447-D456 (2016).
- Bateman, A., et al. UniProt: the universal protein knowledgebase. Nucleic Acids Research. 45 (D1), D158-D169 (2017).
- The Gene Ontology Consortium Expansion of the Gene Ontology knowledgebase and resources. Expansion of the Gene Ontology knowledgebase and resources. Nucleic Acids Research. 45 (D1), D331-D338 (2017).
- O’Leary, N. A., et al. Reference sequence (RefSeq) database at NCBI: current status, taxonomic expansion, and functional annotation. Nucleic Acids Research. 44, D733-D745 (2016).
- Zerbino, D. R., et al. Ensembl 2018. Nucleic Acids Research. 46 (D1), D754-D761 (2018).
- Andreev, D. E., et al. Translation of 5’ leaders is pervasive in genes resistant to eIF2 repression. eLife. 4, e03971 (2015).
- Jackson, R., et al. The translation of non-canonical open reading frames controls mucosal immunity. Nature. 564, 434-438 (2018).
재인쇄 및 허가
JoVE'article의 텍스트 или 그림을 다시 사용하시려면 허가 살펴보기
허가 살펴보기This article has been published
Video Coming Soon
Copyright © 2025 MyJoVE Corporation. 판권 소유