
Method Article
纳米测序全血 mRNA 测序
摘要
纳米点测序是一种新技术, 可在远程位置和资源贫乏的环境中实现经济高效的测序。在这里, 我们提出了一个从全血 Mrna 测序的协议, 与这些条件兼容。
摘要
在远程位置和资源贫乏的环境中排序带来了独特的挑战。纳米孔测序可以在这种条件下成功使用, 并在最近的埃博拉病毒疫情期间部署到西非, 突出了这种可能性。除了其实际优势 (低成本、易于设备运输和使用) 外, 与第二代测序方法相比, 该技术还提供了根本优势, 特别是读取长度很长、直接排序能力强RNA 和数据的实时可用性。原始读取精度低于其他测序平台, 这是该技术的主要局限性;但是, 生成的高读取深度可以部分缓解这种情况。在这里, 我们提出了一个领域兼容的协议, 用于对 Nemann-pchnc1 的 Mrna 编码进行测序, 这是 ebolavia 病毒的细胞受体。该协议包括从动物血液样本中提取 RNA, 然后 RT-PCR 用于目标浓缩、条形码、库准备和测序运行本身, 并且可以很容易地与其他 DNA 或 RNA 目标一起使用。
引言
测序是生物和生物医学研究中一个强大而重要的工具。它允许分析基因组、基因变异和 rna 表达谱, 从而在人类和动物疾病的调查中发挥重要作用, 同样是1,2。桑格测序是最古老的 DNA 测序方法之一, 至今仍经常使用, 一直是分子生物学的基石。在过去的50年里, 这项技术得到了改进, 读取长度超过 1000, 000, 精度高达 99.99%1。但是, Sanger 测序也有局限性。用这种方法对更大的样本进行测序或对整个基因组进行分析是耗时和昂贵的1,3。第二代 (下一代) DNA 测序方法, 如454焦磷酸测序和 Illumina 技术, 使我们能够在过去十年中大幅降低测序所需的成本和工作量, 并导致可利用的生物序列信息的数量 4。然而, 使用这些第二代技术进行的单独测序运行成本很高, 而且在现场条件下进行测序具有挑战性, 因为必要的设备体积庞大且脆弱 (类似于 Sanger 测序设备), 而且通常必须由受过专门训练的人员进行校准和服务。另外, 对于许多第二代技术来说, 阅读长度相当有限, 这往往使下游对这些数据的生物信息学分析具有挑战性。
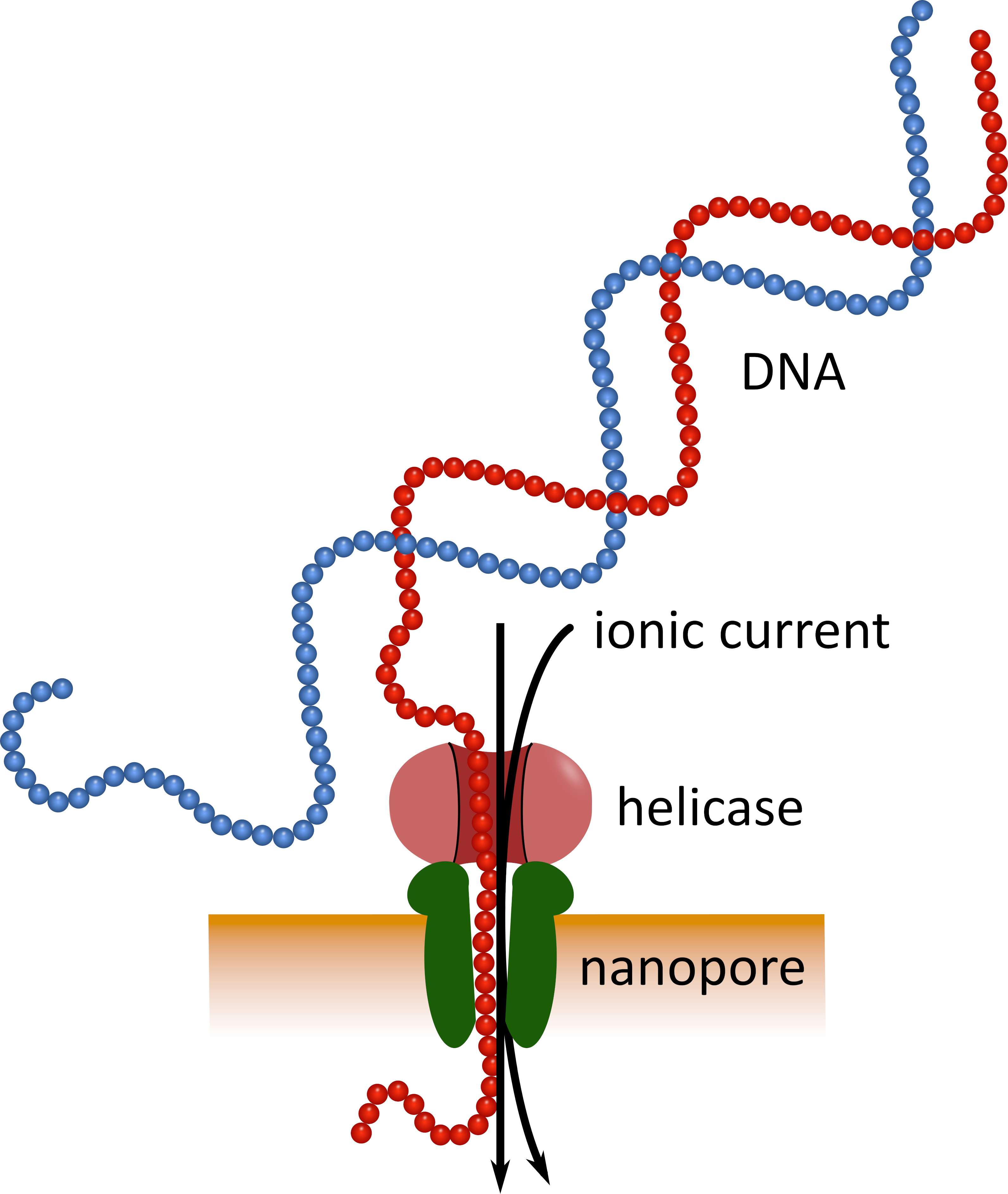
使用口袋大小的纳米粒子测序装置 (见材料表) 的第三代测序可作为这些既定测序平台的替代方案。在这些器件中, 单链 DNA 或 RNA 分子与离子电流同时通过纳米孔, 然后由传感器测量 (图 1)。当链穿过纳米孔时, 可以检测到在任何给定时间存在于孔隙中的核苷酸对电流的调制, 并将计算反转化为核苷酸序列5。由于这一工作原理, 纳米粒子测序既允许产生非常长的读取 (接近 1 x 106核苷酸6), 又允许实时分析测序数据。通过将定义的核苷酸序列附加到样品中的核酸, 可以进行条形码编码, 从而可以在一次测序运行中分析多个样品, 从而提高样品吞吐量并降低每个样品的成本。由于纳米粒子测序装置具有较高的可移植性和易用性, 在西非最近的埃博拉病毒病疫情期间, 纳米粒子测序装置已在实地成功使用, 这突出表明它们适合快速部署到偏远地区7,8。
在这里, 我们描述了一个详细的领域兼容协议的 mRNA 编码测序的尼曼-皮克 c1 (NPC1) 蛋白, 这是强制性进入受体的丝状病毒, 如 ebolaviruses 病毒, 并已被证明限制物种易感性这些病毒9,10。该协议包括从血液样本中提取整个 RNA、通过 RT-PCR 对 NPC1 mRNA 进行特异性扩增、对样本进行条形码、库制备和纳米粒子测序装置测序。由于空间有限, 无法讨论数据分析, 尽管具有代表性的结果提供了一些基本方向;但是, 有关读者请参阅以前的出版物11 , 以更详细地描述我们使用的工作流程, 并参考其他人的出版物12、13、14 以获取详细信息有关此工作流中使用的分析工具。
研究方案
样本是根据 Njala 大学机构审查委员会 (NUIRB) 第1号议定书收集的。IRB0000886半 FWA00018924。
1. 从血液样本中提取 RNA
- 从该物种中收集3毫升全血, 并通过倒置5次进行混合, 该机构的血液收集管中含有6毫升的 Dnaa/rna 稳定剂 (见材料表)。将血液样本存放在4°C 下, 最长1个月。
- 将采血管的内容物转移到一个50毫升的收集管中, 加入120Μl 的蛋白酶 k, 并通过涡流混合 5 s. 在室温下将样品培养30分钟。
- 在混合物和涡旋中加入9毫升异丙醇, 时间为5秒。
- 将储液罐放置在 RNA 纯化自旋柱上 (见材料表), 并将组件放置在真空歧管上 (参见材料表)。将样品混合物加入到储罐中。应用真空, 直到所有液体都通过柱。
- 或者, 如果没有真空歧管, 血液可以通过700μl 部分的血液通过700μl 部分的重复离心, 以 12, 000 x 克的速度通过 30秒, 并在离心步骤之间丢弃流动。然而, 这将需要大约26个离心步骤。
- 将 RNA 纯化自旋柱放入收集管中, 加入 400Μl DNAC/RNA 制备缓冲液 (见材料表)。以 12, 000 x克的速度离心 30秒, 并丢弃流经。
- 在色谱柱中加入400μl 的 DNA\ rna 洗涤缓冲液 (见材料表), 以 12, 000 x克的离心机 30 x x。
- 将5Μl 的 DNase i (1 U/μL) (见材料表) 与75ΜL 的 dna 消化缓冲液 (见材料表) 混合, 然后将混合物添加到色谱柱上。在室温下孵化15分钟。
- 在色谱柱上加入400μl 的 DNA\ rna 准备缓冲液, 离心机在 12, 000 x克处添加30秒。
- 用700μl 的 dna 清洗缓冲液和离心机将色谱柱洗至 12, 000 x克, 30s. 丢弃流动。
- 重复步骤1.9 与400μl 的 dna rna 洗涤缓冲液和离心机在 12, 000 x g为 2分钟, 以删除所有残留的洗涤缓冲液, 并干燥列。从收集管中取出柱时, 请确保不要用收集管中的缓冲器弄湿柱的底面。
-
将色谱柱放入新的 1.5 mL 微离心管中, 加入70Μl 的无核酸酶水。在室温下孵化 1分钟, 离心机在 12, 000 x克处为30秒。将 RNA 存放在-80°c, 直到进一步使用 (或立即使用)。
- 可选:要量化 RNA, 取一个, 并使用紫外分光光度计 (见材料表) 确定浓度。
2. 将 NPC1 mRNA 反向转录到 cDNA 中
- 在 0.2 mL 反应管中, 加入8μl 模板 RNA (1 pg 至2.5 微克 RNA), 每次添加1微克 DNase 缓冲液和 DNase 酶 (见材料表)。在37°c 下孵化2分钟。随后, 离心反应简要地并且安置它在冰。
- 加入4Μl 的逆转录酶主混合物 (见材料表) 和6μl 的无核酸酶水的反应管, 然后轻轻混合。在25°c 时将反应在热环器中培养 10分钟 (用于底漆退火), 然后在50°c 时 (用于 RNA 逆转录酶), 然后为10分钟。要使酶失活, 在85°c 孵育5分钟。
- 将 cDNA 转移到新的 1.5 mL 微离心管, 并在-80°c 下储存, 直到进一步使用 (或立即使用)。
3. 放大 NPC1 开放阅读框架
-
初始放大步骤
- 设置一个触控 pcr15,16, 用底漆集 1 (见表 1) 放大 npc1 cdna, 使用热启动高保真度 dna 聚合酶 (见材料表) 在50μl 反应中使用适当的反应缓冲液具有1Μl 模板的体积。如果可能, 请在冰上或4°C 的冷却块中设置反应。
- 在98°c 时, 用30分钟的初始变性步骤将反应提前 10次, 在98°c 时变性10个周期为 10秒, 在65°c 时底漆退火为 20秒, 在72°c 下将温度降低 0.5°c, 在72°c 下延伸1分钟。随后, 在98°c 下运行额外的20个周期, 在98°c 下运行 10秒, 在60°c 下运行 20秒, 在72°c 下运行 1分钟, 然后在72°c 下进行5分钟的最后伸长步长。
-
磁珠 PCR 纯化
- 将 50μl PCR 产物转移到 1.5 mL dna 低结合反应管中 (见材料表)。通过涡流彻底重新扫描磁珠 (见材料表), 并在 PCR 反应中添加50Μl 磁珠。混合好。在旋转搅拌机上对样品进行15分钟的间隔 (见材料表), 在室温下 (15 转/分)。
- 简要旋转样品, 并将 1.5 mL 微型离心管放置在磁性机架上 (见材料表), 以对磁珠进行球团。等待, 直到上清剂已完全澄清, 然后再继续下一步。
- 在不干扰珠子颗粒的情况下吸收上清液并丢弃。
- 将70% 乙醇的液滴200Μl 注入反应管并孵育 30秒. 在不干扰颗粒和丢弃的情况下吸入乙醇。对总共两次清洗重复此操作。确保没有留下乙醇。可能需要先用较大的移液器 (例如, 1000μl) 吸气, 然后用较小的移液器 (例如 10μl) 取出任何剩余的乙醇液滴。
- 在室温下将颗粒风干1分钟。
- 从磁性架上取出反应管, 将颗粒重新悬浮在30μl 的无核酸酶水中, 并在室温下孵育2分钟。
- 将反应管放回磁性机架上, 等待珠子完全被颗粒状。
- 在不干扰颗粒的情况下取出上清液, 并将其转移到新的 1.5 mL 反应管中。
-
嵌套 PCR 添加条码适配器
- 设置一个50Μl 触控 PCR 与热启动高保真 DNA 聚合酶与5倍反应缓冲液和底漆集 2 (见表 1)。此集合中的引物包括一个目标序列特定区域, 以允许绑定步骤3.2 中生成的 PCR 产品 (引物集1序列内部), 以及在随后的条形码 PCR 反应中用作目标的适配器序列 (参见第4节)。如果可能, 请在冰上或4°C 的冷却块中设置反应。使用第3.2 节中制备的纯化 PCR 产品的1Μl 作为模板。
- 在98°c 下使用30秒的初始变性步骤将反应混合物用于热环器中的反应混合物, 然后在98°c 下进行10次变性循环 10秒, 在65°c 下底漆退火 20秒, 将每个循环的温度降低0.5°C, 在72°c 下伸长1分钟。随后, 在98°c 下再孵育30个周期, 在71°c 下孵育 20秒, 在72°c 下孵育 1分钟, 然后在72°c 下最后一次伸长5分钟。
- 如第3.2 节所述, 使用磁珠清洁 PCR 产品。
4. NPC1 的条形码
- 对于第3节中生成的每个 PCR 产品, 使用50μl 的 Taq dna 聚合酶2x 主混合物 (见材料表), PCR 条形码试剂盒中的一种条形码引物 (见材料表 和表 2), 以及从步骤3.3.2 作为模板的纯化 PCR 产物的1μl。加入47Μl 的无核酸酶水, 以获得100Μl 的最终体积。
- 在95°c 时将反应在热环素中培养3分钟作为初始变性。随后, 在95°c 下运行15个周期, 在62°c 下运行 15秒, 在65°c 下运行15分钟。作为最后的伸长率, 在65°c 下孵育反应5分钟。
- 如3.2 中所述, 纯化 PCR 产品, 但在30μl 无核酸酶水中使用100μl 的磁珠和磁珠。
- 如有可能, 使用紫外分光光度计对样品进行量化。
5. 图书馆准备
- 将每个样品中的相同数量的条形码 DNA 结合在一起, 在0.2ml 反应管中总共增加1微克的 DNA (如有必要, 添加无核酸酶水)。如果没有可用的紫外分光光度计, 请使用每个样品的等量。对于 Da-ting, 添加7Μl 的端前准备反应缓冲液 (见材料表)、3μl 的端前制备酶混合物 (见材料表) 和5μl 的无核酸酶水。轻轻混合, 轻弹管。
- 在20°c 下将反应加氢 5分钟, 在65°c 时将反应提前5分钟在热环器中。
- 如第3.2 节所述, 净化反应产物, 但在25μl 无核酸酶水中使用60μl 的磁珠和磁铁。
- 可选: 使用紫外分光光度计以1μl 为例, 量化样品的浓度。总额应超过700纳克。
- 将步骤5.3 中的22.5μl 纯化 Dna 与2.5μl 的1D2 适配器 (见材料表) 和25μl 的钝 t→连接酶母组合 (见材料表) 混合在一个新的 1.5 ml dna-低结合反应管中, 通过闪烁轻轻混合, 并短暂旋转下来。在室温下孵化10分钟。
- 按照第3.2 节的描述对反应产物进行纯化, 但使用20Μl 磁珠, 将 DNA 结合的孵化时间增加到 10分钟, 用每个1毫升乙醇进行两个洗涤步骤, 并在46μl 无核酸酶水中洗净。
- 将步骤5.6 中的反应产物45μl 与5μl 的条形码适配器混合 (见材料表) 和50μl 的钝 ta/ta 连接母材混合在 dna 低结合反应管中。在室温下轻轻搅拌10分钟。
- 如第3.2 节所述, 净化反应产物, 但使用40μl 磁珠, 用 140μl Abb 缓冲液 (见材料表) 代替乙醇进行两个清洗步骤, 通过闪烁和在磁性机架上加入颗粒重新悬浮微珠。在15Μl 洗脱缓冲液中的洗脱 (见材料表)。将 DNA 与珠子的初始结合以及洗脱步骤的孵育时间增加到 10分钟, 将产生的产品存放在冰上或 4°c, 直到使用。
6. 流动单元的质量检查
- 使用前对流动单元进行质量检查。为此, 将测序设备连接到主机并打开软件。
- 将流单元 (请参阅物料表) 插入测序设备, 然后从选择器框中选择流单元类型, 然后通过单击 "可用"进行确认。
- 单击屏幕底部的"检查流单元" , 然后选择正确的流单元格类型。
- 单击"开始测试"开始质量检查。流动单元要可用, 总共至少需要800个活性纳米孔。
7. 加载流单元并开始排序运行
- 按顺时针方向滑动, 打开启动端口盖。将 P1000 移液器设置为 200μl, 并将尖端插入启动口。将移液器调整到 230μl, 同时将尖端保持在启动端口, 以绘制20-30Μl 缓冲液并去除任何气泡。
- 在新的 1.5 mL dna 低结合反应管中, 将576μl 的 RBF 缓冲液 (见材料表) 与624μl 的无核酸酶水结合在一起, 制备启动混合物。
- 小心将准备好的启动口混合物的800μl 移液器放入启动口, 等待 5分钟. 提起样品端口盖, 并将准备好的启动器混合物的200Μl 额外移液器插入启动口。
- 移液器35μl 的 RBF 缓冲液进入一个新的, 干净的 1.5 mL DNA 低结合反应管。通过移液将 LLB 珠子 (见材料表) 彻底混合, 并将25.5μl 的珠子添加到 RBF 缓冲液中。从步骤5.8 起加入2.5Μl 无核水和 12μl Dna 文库, 然后通过移液混合。
- 通过样品端口以缓慢的方式将样品混合物的75Μl 加入流动单元。
- 更换样品端口盖, 关闭启动端口, 并关闭测序装置的盖。
- 在软件中, 确认流单元仍然可用, 打开一个新实验, 并通过选择所使用的工具包来设置运行参数。选择实时基调用。通过单击 "开始实验"开始排序运行。继续排序, 直到收集到足够的实验数据。
结果
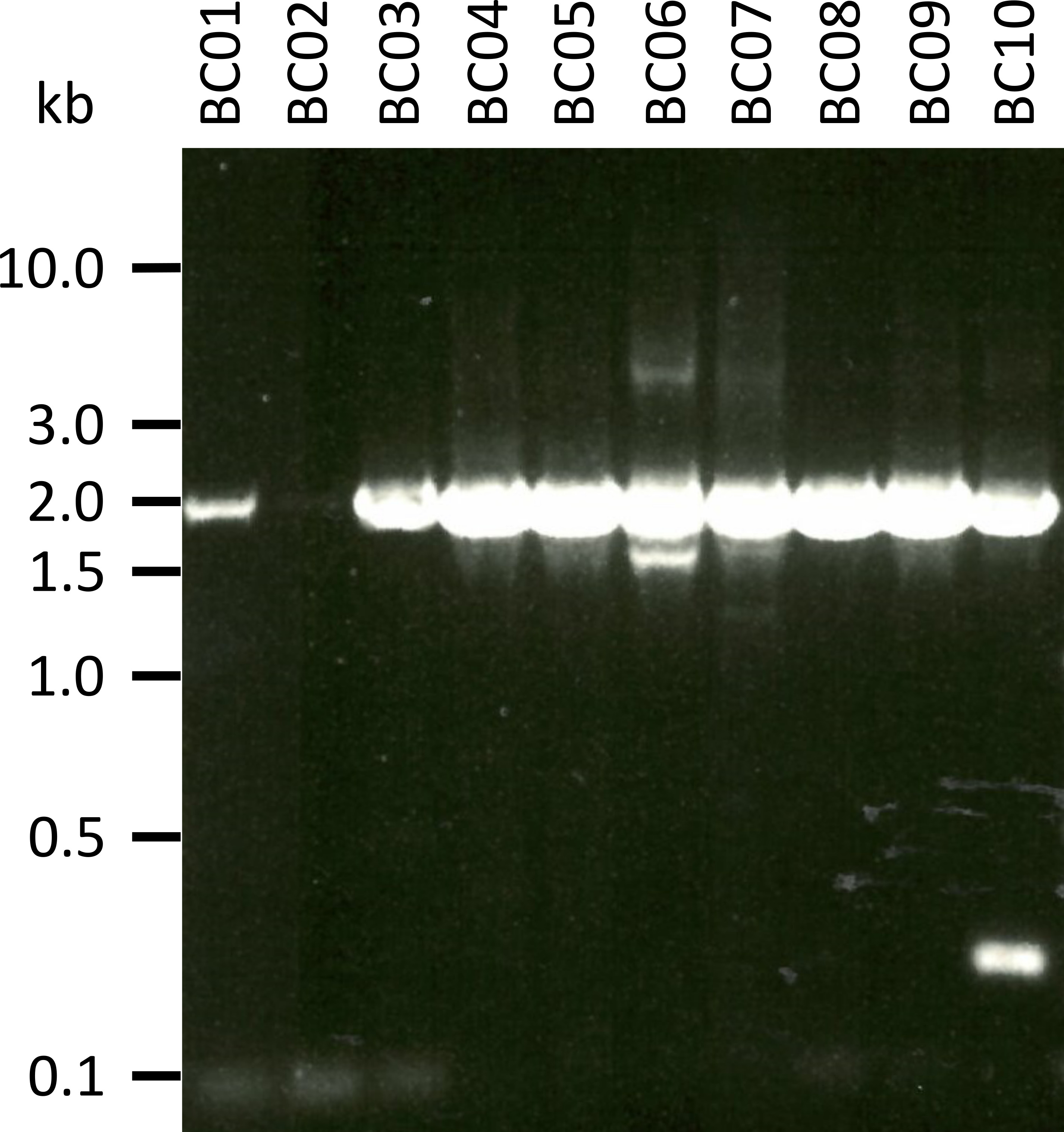
在一项测试所提出的协议的代表性实验中, 我们从5个动物物种的10个不同血液样本中提取了 RNA 样本 (即每个物种2个个体 (山羊、绵羊、猪、狗、牛)) (表 3)。RNA 产量和提取后的质量可能差别很大, 特别是由于样品处理和储存方面的差异。在我们的代表性实验中, 我们观察到每微米43纳克至543纳克的 RNA 浓度 (表 3)。此外, 在 RT-PCR 扩增后, 对 NPC-1 PCR-products 的凝胶分析显示了各种结果 (图 2), bc01 和 BC02 样品 (均为山羊) 的带明显较弱。这些差异很可能是由于样品质量的差异造成的, 但由于与不同物种的 NPC1 基因结合的引物结合的差异, PCR 疗效的差异是不能排除的。然而, 产量和扩增效率的这些差异并没有显著影响总体测序结果。此外, 在 BC10 (牛) 样品中又出现了一个非特异性 PCR 产物。与 Sanger 测序不同的是, 此类非特定产品不会对纳米粒子测序结果产生负面影响, 因为这些读数在将所获得的读取映射到参考序列时作为数据分析的一部分而被丢弃。
在每次测序运行之前, 强烈建议对要使用的流动单元进行质量检查, 最低要求为800个总毛孔。在我们的代表性实验中, 这种质量检查返回了 1, 102个可用于测序的毛孔。由于数据是实时提供的, 可以立即进行分析, 因此可以针对各个应用程序调整排序运行的长度 (即, 直到为所需的分析生成足够的测序数据)。在我们的实验中, 测序运行通常是在一夜之间进行的, 在我们具有代表性的实验中, 我们在这样的14小时运行中获得了大约140万次读数。
根据要执行的数据分析类型, 最好只处理所获得的读取的子集。在我们的代表性实验中, 选择了 10, 000次读取的子集进行进一步分析。为此, 在测序运行过程中生成的 fastq 文件在 Ubuntu 18.04 LTS 环境中进一步处理, 并使用柔性棒 v3.0.3 进行解模, 并为纳米粒子测序数据 (条形码尾长 300) 的去多路化参数进行优化, 条码误差 0.2, 条码-交换点球-1)12。在多路复用、阅读映射和共识生成之后, 可以使用许多不同的工具进行绘制, 但对纳米粒子测序的生物信息学方面的详细讨论超出了本手稿的范围。但是, 就我们的代表性结果而言, 读取映射到参考序列是使用 Geneious 10.2.3 执行的。在分析的 10, 000次读数中, 5, 457次显示长度在 1, 750 到 2, 000个核苷酸之间, 这与作为我们工作流程的一部分而扩增的 PCR 片段的预期大小相匹配 (1769,图 3)。在读取长度分布中观察到250至500个核苷酸的另一个峰值, 这可归因于不特异性 PCR 产物。读取的多路复用允许将88% 的读取分配给分析的10个辅酶样本中的一个 (图 4)。每个条形码的去多路读数比例从条形码1的3.4% 到条形码10来到16.9% 不等;然而, 由于总体上有大量的读取, 即使对于这些较低的丰富条形码数据集, 这仍然允许有意义的共识调用具有较高的读取深度。实际上, 将排序读取映射到 NPC1 的参考序列会导致将读取映射到参考的读取值在 31.7% (条形码 2) 和 100% (条形码7和 8点) 之间, 每个样本的读取深度在每个位置都有超过90个。这样就足以让自信的共识基础调用具有可忽略不计的错误率。

图 1: 使用纳米粒子技术进行 DNA 测序的示意图.单链 DNA 分子通过嵌入在电阻膜中的纳米孔, 其螺旋酶调节过渡速度。离子电流同时穿过孔隙并连续测量。检测到由孔隙中存在的核苷酸引起的电流调制, 并将计算反转化为 DNA 链的核苷酸序列。请点击这里查看此图的较大版本.
{kind=link}

图 2: 从 mRNA 中提取尼曼-皮克 c1 的 PCR 产物的扩增。从山羊 (BC01 和 02)、绵羊 (BC03 和 04)、猪 (BC05 和 06)、狗 (BC07 和 08) 和牛 (BC09 和 10) 中分离出 mRNA。嵌套 PCR 产物在 1x TAE 缓冲液中的0.8% 琼脂糖凝胶中分离 (由 50x TAE 缓冲液制备: 242.28 g 的 tris 基, 57.1 mL 的冰醋酸, 100 毫升 0.5 m EDTA, dH2o 至 1 l, ph 值调整到 8.0) 45分钟, 在 100 v 和染色赛伯安全。请点击这里查看此图的较大版本.
{kind=link}

图 3: 从代表性实验中读取 10, 000次读数的读取长度分布.指示具有给定读取长度间隔的读取次数。请点击这里查看此图的较大版本.
{kind=link}

图 4: 去复用后读取的分布.显示每个条形码的去多路复用 (灰色) 和映射读取 (黑色) 的数量和百分比。请点击这里查看此图的较大版本.
{kind=link}
表 1: 使用的引物集概述.使用引物集1对目标序列进行初始放大。入门集 2, 然后用于嵌套放大和适配器添加。适配器用红色表示。请点击此处下载此文件.
表 2: 条形码序列概述.使用单独的条形码来识别每个测序样本。请点击此处下载此文件.
表 3: 在具有代表性的实验中测序的血液样本中提取后获得的 RNA 浓度.显示了五个物种中每个个体的 RNA 浓度, 并显示了26/280 纳米和260/280 纳米的光学密度之比。请点击此处下载此文件.
讨论
在过去二十年里, 生物样本的测序已成为广泛学科领域研究的一个日益重要的方面。基于密集 dna 特征测序的第二代测序系统的开发, 使用酶操作和基于图像的数据采集1的迭代周期, 大大提高了吞吐量。传统的 Sanger 测序技术, 并允许分析多个样本以及不同的核酸物种在给定的样本平行 4。然而, 对于大多数常用的第二代系统, 只产生短读取, 所有平台都依赖于敏感、笨重和昂贵的设备3,4。
与第二代测序平台不同的是, 该协议中使用的测序装置基于纳米粒子技术。在这里, 单链核酸分子通过纳米孔, 导致调节离子电流, 该电流也流经相同的纳米孔, 并且可以测量和反转化, 以推断核酸分子的序列。与其他方法相比, 这种第三代排序方法具有许多优势。与这项技术独特的工作原理直接相关的主要优点是产生了极长的读取长度 (读取长度高达 8.8 x10 5 核苷酸已被报告6), 不仅能够对 dna 进行排序, 而且能够对 dna 进行排序。RNA 也直接被证明, 最近被证明是一个完整的流感病毒基因组17, 并能够实时分析数据, 因为他们正在生成, 这使得快速 metagenomics 学检测病原体在分钟18。其他实际优势是纳米粒子测序装置的尺寸极小, 允许在任何实验室或对偏远地点进行实地访问时使用19、20, 与其他测序相比价格低廉平台。在运行成本方面, 目前每次测序运行都需要一个新的流动单元, 这导致流动单元和库准备试剂每次运行的费用约为 1 100 美元。在某些情况下, 可以通过清洗和重用流单元, 或通过一次运行对多个样本进行条形码和排序来降低这些成本。另外, 目前少数实验室正在对一种新型流动单元进行贝尔测试, 这将需要使用流动单元适配器 (称为 "flongle"), 并应大幅降低流动单元的价格, 从而降低运行成本。
纳米粒子测序的主要缺点仍然是它的准确性, 单读精度在 83% 至86% 之间, 报告的范围为6,21,22, 大多数不准确是由插入/删除 (indels)5,21。然而, 高读取深度可以弥补这些不准确之处, 最近的一项研究基于理论考虑表明, gt;10 的阅读深度可能会将总体精度提高到 & gt;99.8 21。然而, 需要进一步提高准确性, 特别是如果要在单一分子水平上进行分析, 而不是在协商一致的序列水平上进行分析的话。使用1D2 技术 , 如本协议所述, 这是基于增加1d2 和条形码适配器 (参见第5.5 节), 导致单链 dna 分子被同一纳米孔测序, 增加了准确性, 因为来自两个 DNA 链的信息可用于序列确定。此外, 为了将纳米粒子测序 (特别是长读取长度) 的优势与其他测序技术的更高精度结合起来, 可以采取的解决方法策略是使用纳米粒子测序信息作为支架, 这是然后使用来自其他平台的测序数据进行抛光 6。
此处介绍的协议成功的最关键因素是样品质量, 特别是提取的 RNA 的数量和质量。适当储存和迅速提取 RNA 有助于实现足够的 RNA 产量。使用适当的采血管可以将血液样本储存长达一个月, 但血液凝集可能是一个问题, 特别是在高温下储存样本的情况下, 在野外条件下可能会出现这种情况。第二个关键步骤是目标序列的扩增, 特别是在现场条件下, PCR 反应的性能往往低于标准实验室条件下的7。为此, 仔细的底漆设计和优化对于实现鲁棒放大至关重要。此外, 嵌套 pcr 方法和触控 pcr, 在该方案中使用, 可以提高特异性基因扩增 4,7的特异性和敏感性。事实上, 根据我们在利比里亚和几内亚使用这一技术的经验, 在实地条件下需要嵌套规程, 即使是初级样品也需要, 即使是初级材料, 也可以放大实验室样品中的目标, 并在实验室条件下使用单轮 PCR (7和未公布的结果)。
与这些更关键的步骤不同, 库准备和排序运行本身是相当可靠的过程。然而, 在实地条件下, 某些设备的供应等实际问题可能会有问题。例如, 在图书馆准备条形码样本之前, 需要使用紫外分光光度计来确定 DNA 浓度。但是, 如果在现场条件下无法提供这种设备, 则只需将每个样品的等量组合在一起, 即可构成库准备所需的 45μl, 然后通常会通过大读取次数。同样, 对排序运行的互联网连接的需求也可能是一个问题, 尽管基调用不再需要在网上执行, 而是可以在本地执行;但是, 在某些情况下, 制造商可以在必要时消除此必要性。
总之, 所提出的协议允许在无法使用传统测序设备的地点, 包括在偏远地点, 进行相对低成本的测序。它可以很容易地适应任何目标 RNA 或 DNA, 从而使研究人员能够回答许多生物问题。
披露声明
TH 从2014年至2015年参加了牛津纳米粒子技术 (ONT) MinION 早期访问计划, 并获得了美国国立卫生研究院免费或以更低的成本进行的先前研究7的 minion 设备和流动单元.他应 ont 邀请, 在英国伦敦举行的伦敦呼吁2015会议上介绍了这项工作的一部分, ont 支付了交通和住宿费用。对于本手稿中介绍的作品, 没有从 ONT 获得任何好处 (例如硬件或试剂以更低的成本, 旅行报销等)。AM、KF 和 RS 没有什么可透露的。
致谢
作者感谢艾里森·格罗斯对手稿的批判性解读。这项工作得到了德国联邦粮食和农业部的财政支持, 该部是根据德意志联邦共和国议会通过联邦农业和粮食办公室作出的决定进行的。
材料
| Name | Company | Catalog Number | Comments |
| 1D2 adapter, barcode adapter mix, ABB buffer, elution buffer, RBF buffer, LBB beads | Oxford Nanopore Technologies | SQK-LSK308 | 1D² Sequencing Kit |
| Blood collection tube with DNA/RNA stabilizing reagent | Zymo Research | R1150 | DNA/RNA Shield - Blood Collection Tube |
| Blunt/TA ligase master mix | New England Biolabs | M0367S | Blunt/TA Ligase Master Mix |
| DNA-low binding reaction tube | Eppendorf | 30108051 | DNA LoBind Tube |
| DNase buffer and DNase | ThermoFisher Scientific | 11766050 | SuperScript™ IV VILO™ Master Mix with ezDNase™ Enzyme |
| Flow cell | Oxford Nanopore Technologies | FLO-MIN105.24 | flow cell R9.4 |
| Hot start high fidelity DNA polymerase | New England Biolabs | M0493L | Q5 Hot Start High-Fidelity DNA Polymerase (500 U) |
| Magnetic beads | Beckman Coulter | A63881 | Agencourt AMPure XP beads |
| Magnetic rack | ThermoFisher Scientific | 12321D | DynaMag-2 Magnet |
| Nanopore sequencing device | Oxford Nanopore Technologies | - | MinION Mk 1B |
| PCR barcoding kit | Oxford Nanopore Technologies | EXP-PBC001 | PCR Barcoding Kit I (R9) |
| Reverse transcriptase master mix | ThermoFisher Scientific | 11766050 | SuperScript™ IV VILO™ Master Mix with ezDNase™ Enzyme |
| RNA purification spin column, DNA/RNA prep buffer, DNA/RNA wash buffer, DNase I, DNA digestion buffer | Zymo Research | R1151 | Quick-DNA/RNA Blood Tube Kit |
| Rotating mixer | ThermoFisher Scientific | 15920D | HulaMixer Sample Mixer |
| Taq DNA polymerase | New England Biolabs | M0287S | LongAmp Taq 2x Master Mix |
| Ultra II End-prep kit | New England Biolabs | E7546S | NEBNext Ultra II End-Repair/dA-tailing Modul |
| UV spectrophotometer | Implen | - | NanoPhotometer |
| Vacuum manifold | Zymo Research | S7000 | EZ-Vac Vacuum Manifold |
参考文献
- Shendure, J., Ji, H. Next-generation DNA sequencing. Nature Biotechnology. 26 (10), 1135-1145 (2008).
- Shendure, J., Lieberman Aiden, E. The expanding scope of DNA sequencing. Nature Biotechnology. 30 (11), 1084-1094 (2012).
- Liu, L., et al. Comparison of next-generation sequencing systems. Journal of Biomedicine and Biotechnology. 2012, 251364 (2012).
- Levy, S. E., Myers, R. M. Advancements in Next-Generation Sequencing. Annual Review of Genomics and Human Genetics. 17, 95-115 (2016).
- Lu, H., Giordano, F., Ning, Z. Oxford Nanopore MinION Sequencing and Genome Assembly. Genomics, Proteomics & Bioinformatics. 14 (5), 265-279 (2016).
- Jain, M., et al. Nanopore sequencing and assembly of a human genome with ultra-long reads. Nature Biotechnology. 36 (4), 338-345 (2018).
- Hoenen, T., et al. Nanopore Sequencing as a Rapidly Deployable Ebola Outbreak Tool. Emerging Infectious Diseases. 22 (2), 331-334 (2016).
- Quick, J., et al. Real-time, portable genome sequencing for Ebola surveillance. Nature. 530 (7589), 228-232 (2016).
- Carette, J. E., et al. Ebola virus entry requires the cholesterol transporter Niemann-Pick C1. Nature. 477 (7364), 340-343 (2011).
- Ndungo, E., et al. A Single Residue in Ebola Virus Receptor NPC1 Influences Cellular Host Range in Reptiles. mSphere. 1 (2), (2016).
- Martin, S., et al. A genome-wide siRNA screen identifies a druggable host pathway essential for the Ebola virus life cycle. Genome Medicine. 10 (1), 58 (2018).
- Roehr, J. T., Dieterich, C., Reinert, K. Flexbar 3.0 - SIMD and multicore parallelization. Bioinformatics. 33 (18), 2941-2942 (2017).
- Li, H., et al. The Sequence Alignment/Map format and SAMtools. Bioinformatics. 25 (16), 2078-2079 (2009).
- Kielbasa, S. M., Wan, R., Sato, K., Horton, P., Frith, M. C. Adaptive seeds tame genomic sequence comparison. Genome Research. 21 (3), 487-493 (2011).
- Don, R. H., Cox, P. T., Wainwright, B. J., Baker, K., Mattick, J. S. Touchdown' PCR to circumvent spurious priming during gene amplification. Nucleic Acids Research. 19 (14), 4008 (1991).
- Korbie, D. J., Mattick, J. S. Touchdown PCR for increased specificity and sensitivity in PCR amplification. Nature Protocols. 3 (9), 1452-1456 (2008).
- Keller, M. W., et al. Direct RNA Sequencing of the Coding Complete Influenza A Virus Genome. Scientific Reports. 8 (1), 14408 (2018).
- Greninger, A. L., et al. Rapid metagenomic identification of viral pathogens in clinical samples by real-time nanopore sequencing analysis. Genome Medicine. 7, 99 (2015).
- Castro-Wallace, S. L., et al. Nanopore DNA Sequencing and Genome Assembly on the International Space Station. Scientific Reports. 7 (1), 18022 (2017).
- Goordial, J., et al. In Situ Field Sequencing and Life Detection in Remote (79 degrees 26'N) Canadian High Arctic Permafrost Ice Wedge Microbial Communities. Frontiers in Microbiology. 8, 2594 (2017).
- Runtuwene, L. R., et al. Nanopore sequencing of drug-resistance-associated genes in malaria parasites, Plasmodium falciparum. Scientific Reports. 8 (1), 8286 (2018).
- Rang, F. J., Kloosterman, W. P., de Ridder, J. From squiggle to basepair: computational approaches for improving nanopore sequencing read accuracy. Genome Biology. 19 (1), 90 (2018).
转载和许可
请求许可使用此 JoVE 文章的文本或图形
请求许可探索更多文章
This article has been published
Video Coming Soon
版权所属 © 2025 MyJoVE 公司版权所有,本公司不涉及任何医疗业务和医疗服务。