
Se requiere una suscripción a JoVE para ver este contenido. Inicie sesión o comience su prueba gratuita.
Method Article
Procesamiento automático de imágenes para determinar la estructura del tamaño de la comunidad de macroinvertebrados ribereños
En este artículo
Resumen
El artículo se basa en la creación de un protocolo adaptado para escanear, detectar, clasificar e identificar objetos digitalizados correspondientes a macroinvertebrados bentónicos de río utilizando un procedimiento de imagen semiautomático. Este procedimiento permite la adquisición de las distribuciones de tamaño individuales y métricas de tamaño de una comunidad de macroinvertebrados en aproximadamente 1 h.
Resumen
El tamaño corporal es un rasgo funcional importante que puede utilizarse como bioindicador para evaluar los impactos de las perturbaciones en las comunidades naturales. La estructura del tamaño de la comunidad responde a gradientes bióticos y abióticos, incluidas las perturbaciones antropogénicas en taxones y ecosistemas. Sin embargo, la medición manual de organismos de cuerpo pequeño como los macroinvertebrados bentónicos (por ejemplo, >500 μm a unos pocos centímetros de largo) lleva mucho tiempo. Para acelerar la estimación de la estructura del tamaño de la comunidad, aquí, desarrollamos un protocolo para medir semiautomáticamente el tamaño corporal individual de los macroinvertebrados de río preservados, que son uno de los bioindicadores más utilizados para evaluar el estado ecológico de los ecosistemas de agua dulce. Este protocolo está adaptado de una metodología existente desarrollada para escanear mesozooplancton marino con un sistema de escaneo diseñado para muestras de agua. El protocolo consta de tres pasos principales: (1) escanear submuestras (fracciones de tamaño de muestra finas y gruesas) de macroinvertebrados de río y procesar las imágenes digitalizadas para individualizar cada objeto detectado en cada imagen; (2) crear, evaluar y validar un conjunto de aprendizaje a través de inteligencia artificial para separar semiautomáticamente las imágenes individuales de macroinvertebrados de los detritos y artefactos en las muestras escaneadas; y (3) que representa la estructura de tamaño de las comunidades de macroinvertebrados. Además del protocolo, este trabajo incluye los resultados de calibración y enumera varios desafíos y recomendaciones para adaptar el procedimiento a las muestras de macroinvertebrados y considerar mejoras adicionales. En general, los resultados apoyan el uso del sistema de escaneo presentado para la medición automática del tamaño corporal de los macroinvertebrados de río y sugieren que la representación de su espectro de tamaño es una herramienta valiosa para la bioevaluación rápida de los ecosistemas de agua dulce.
Introducción
Los macroinvertebrados bentónicos se utilizan ampliamente como bioindicadores para determinar el estado ecológico de las masas de agua1. La mayoría de los índices para describir comunidades de macroinvertebrados se centran en métricas taxonómicas. Sin embargo, se fomentan nuevas herramientas de bioevaluación que integren el tamaño corporal para proporcionar una perspectiva alternativa o complementaria a los enfoques taxonómicos 2,3.
El tamaño corporal se considera un metarasgo que está relacionado con otros rasgos vitales como el metabolismo, el crecimiento, la respiración y el movimiento4. Además, el tamaño corporal puede determinar la posición trófica y las interacciones5. La relación entre el tamaño corporal individual y la biomasa normalizada (o abundancia) por clase de tamaño en una comunidad se define como el espectro de tamaño6 y sigue el patrón general de una disminución lineal en la biomasa normalizada a medida que aumenta el tamaño individual en una escala logarítmica7. La pendiente de esta relación lineal ha sido ampliamente estudiada teóricamente, y estudios empíricos a través de ecosistemas la han utilizado como un indicador ecológico de la estructura del tamaño de la comunidad4. Otro indicador sintético de la estructura del tamaño de la comunidad que se ha utilizado con éxito en los estudios de funcionamiento de la diversidad de la diversidad del tamaño de la comunidad, que se representa como el índice de Shannon de las clases de tamaño del espectro de tamaño o su análogo, que se calcula sobre la base de las distribuciones de tamaño individuales8.
En los ecosistemas de agua dulce, la estructura de tamaño de diferentes grupos faunísticos se utiliza como indicador atáxico para evaluar la respuesta de las comunidades bióticas a gradientes ambientales 9,10,11 y a perturbaciones antropogénicas 12,13,14,15,16. Los macroinvertebrados no son una excepción, y su estructura de tamaño también responde a cambios ambientales17,18 y perturbaciones antropogénicas, como la minería 19, el uso de la tierra 20, o el enriquecimiento de nitrógeno (N) y fósforo (P) 20,21,22. Sin embargo, medir a cientos de individuos para describir la estructura del tamaño de la comunidad es una tarea tediosa y lenta que a menudo se evita como una medición de rutina en los laboratorios debido a la falta de tiempo. Así, se han desarrollado varios métodos de imagen semiautomáticos o automáticos para clasificar y medir especímenes23,24,25,26. Sin embargo, la mayoría de estos métodos se centran en la clasificación taxonómica más que en el tamaño individual de los organismos y no están listos para su uso para todo tipo de macroinvertebrados. En ecología del plancton marino, un sistema de análisis de imágenes de barrido se ha utilizado ampliamente para determinar el tamaño y la composición taxonómica de las comunidades de zooplancton 27,28,29,30,31. Este instrumento se puede encontrar en varios institutos marinos de todo el mundo, y se utiliza para escanear muestras de zooplancton preservadas para obtener imágenes digitales de alta resolución de toda la muestra. El presente protocolo adapta el uso de este instrumento para estimar el espectro del tamaño de la comunidad de macroinvertebrados en los ríos de manera rápida y automática sin invertir en la creación de un nuevo dispositivo.
El protocolo consiste en escanear una muestra y procesar toda la imagen para obtener automáticamente imágenes individuales (es decir, viñetas) de los objetos de la muestra. Varias medidas de forma, tamaño y características de nivel de gris caracterizan cada objeto y permiten la clasificación automática de los objetos en categorías, que luego son validadas por un experto. El tamaño individual de cada organismo se calcula utilizando el biovolumen elipsoidal (mm3), que se deriva del área del organismo medida en píxeles. Esto permite obtener el espectro de tamaño de la muestra de manera rápida. Hasta donde sabemos, este sistema de imágenes de escaneo solo se ha utilizado para procesar muestras de mesozooplancton, pero el dispositivo puede permitir trabajar con macroinvertebrados bentónicos de agua dulce.
El objetivo general de este estudio es, por lo tanto, introducir un método para obtener rápidamente el tamaño individual de los macroinvertebrados de río preservados mediante la adaptación de un protocolo existente previamente utilizado con mesozooplancton marino 27,32,33. El procedimiento consiste en utilizar un enfoque semiautomático que opera con un dispositivo de escaneo para escanear muestras de agua y tres software abierto para procesar las imágenes escaneadas. Aquí se presenta un protocolo adaptado para escanear, detectar e identificar macroinvertebrados de río digitalizados para adquirir automáticamente la estructura de tamaño de la comunidad y las métricas de tamaño relacionadas. La evaluación del procedimiento y las directrices para mejorar la eficiencia también se presentan a partir de 42 imágenes escaneadas de muestras de macroinvertebrados fluviales recogidas en tres cuencas del noreste (NE) de la Península Ibérica (Ter, Segre-Ebre y Besòs).
Las muestras se recogieron en tramos fluviales de 100 m siguiendo el protocolo de muestreo de campo y análisis de laboratorio de macroinvertebrados bentónicos de río en ríos vadeables del Gobierno español34. Las muestras se recolectaron con un muestreador surber (marco: 0,3 m x 0,3 m, malla: 250 μm) después de un estudio de múltiples hábitats. En el laboratorio, las muestras se limpiaron y tamizaron a través de una malla de 5 mm y una malla de 500 μm para obtener dos submuestras: una submuestra gruesa (malla de 5 mm) y una submuestra fina (malla de 500 μm), que se almacenaron en viales separados y se conservaron en etanol al 70%. Separar la muestra en dos fracciones de tamaño permite una mejor estimación de la estructura del tamaño de la comunidad, ya que los organismos grandes son más raros y menos que los organismos pequeños. De lo contrario, la muestra escaneada tiene una representación sesgada de la fracción de gran tamaño.
Protocolo
NOTA: El protocolo descrito aquí se basa en el sistema desarrollado por Gorsky et al.27 para el mesozooplancton marino. Una descripción específica de los pasos del escáner (ZooSCAN), el software de escaneo (VueScan 9x64 [9.5.09]), el software de procesamiento de imágenes (Zooprocess, ImageJ) y el software de identificación automática (Plankton Identifier) se puede encontrar en referencias anteriores32,33. Para ajustar mejor los tamaños de los macroinvertebrados bentónicos con respecto al mesozooplancton, una vez creado el proyecto siguiendo el protocolo original32,33, cambie el parámetro de tamaño mínimo (minsizeesd_mm) a 0,3 mm y el parámetro de tamaño máximo (maxsizeesd_mm) a 100 mm en el archivo de configuración. Para ayudar a seguir el protocolo, esto se resume en una tabla de trabajo (Figura 1). El proyecto creado se almacena en la carpeta C del equipo y se organiza en las siguientes carpetas: PID_process, Zooscan_back, Zooscan_check, Zooscan_config, Zooscan_meta, Zooscan_results y Zooscan_scan. Cada carpeta se compone de varias subcarpetas que las diferentes aplicaciones de software utilizan en los siguientes pasos del protocolo.
1. Adquisición de imágenes digitales para muestras de macroinvertebrados
- Escaneo y procesamiento del espacio en blanco
NOTA: Cree dos imágenes en blanco diariamente antes de escanear para extraer los escaneos de fondo mientras procesa las imágenes escaneadas el mismo día.- Encienda el escáner y encienda la luz en la posición dual para proyectar luz blanca desde la parte superior e inferior.
NOTA: Al escanear muestras de mesozooplancton, se utiliza la dirección ascendente de la luz, pero debido a que los macroinvertebrados son más opacos, se recomienda cambiar la luz a una posición dual. - Limpie y enjuague la bandeja de escaneo con agua del grifo.
- Vierta 110 ml de agua del grifo almacenada a temperatura ambiente (RT) en la bandeja de escaneo hasta que el vaso esté cubierto. Coloque el marco grande (24,5 cm x 15,8 cm) en la bandeja de escaneo en la posición correcta (con la esquina en la parte superior izquierda de la bandeja de escaneo) y llénelo con agua del grifo hasta que el escalón del marco esté cubierto para evitar un efecto de menisco, que alteraría la imagen escaneada. Cierre la tapa del escáner.
NOTA: Use agua en RT para evitar la condensación y la formación de burbujas. Limpie el marco sin marcas ni gotas para evitar el reflejo de la luz. - Vaya al software de procesamiento de imágenes, seleccione el proyecto de trabajo y haga clic en Escanear (Convertir) imagen de fondo.
- Vaya al software de escaneo y haga clic en Vista previa. Asegúrese de obtener una vista previa de la imagen escaneada, verifique que no haya líneas ni manchas y espere al menos 30 s antes de comenzar otro escaneo. Haga clic en Escanear y presione OK en la ventana de instrucciones antes del segundo escaneo para enviar los datos del software de escaneo al software de procesamiento de imágenes.
NOTA: Escanee dos veces para obtener los dos escaneos de fondo que comprenderán el espacio en blanco. Este paso se realiza una vez al día antes de iniciar el procesamiento de muestras, y las imágenes se almacenan en la carpeta Zooscan_back. - Cierre el software de escaneo después de finalizar el escaneo.
- Encienda el escáner y encienda la luz en la posición dual para proyectar luz blanca desde la parte superior e inferior.
- Preparación y escaneo de muestras
PRECAUCIÓN: El etanol es un líquido inflamable y podría causar daño / irritación ocular grave.- Rellene los metadatos de ejemplo. Vaya al software de procesamiento de imágenes y seleccione Rellenar metadatos de muestra. Introduzca la identidad de la muestra, haga clic en Aceptar y rellene los metadatos.
NOTA: El metarchivo se crea específicamente para muestras de mesozooplancton, por lo que no se ajusta a la metodología de muestreo de macroinvertebrados bentónicos, sin embargo, todos los campos del archivo deben completarse antes del escaneo, o aparecerá una bandera de error. - Vierta 110 ml de etanol al 70% en la bandeja de escaneo hasta que el vidrio esté cubierto y coloque el marco grande (24.5 cm x 15.8 cm) con la esquina en la parte superior izquierda de la bandeja de escaneo.
NOTA: Trabaje con etanol en lugar de agua, ya que los macroinvertebrados se conservan en etanol. En el agua, flotan y se desplazan en la bandeja de escaneo, evitando una imagen nítida y, por lo tanto, mediciones de tamaño confiables. El etanol debe conservarse en RT para evitar la condensación y la formación de burbujas. - Vierta la muestra de macroinvertebrados en la bandeja de escaneo bordeada por el marco y cubra el paso del marco con más etanol si es necesario.
NOTA: Absténgase de agregar demasiado etanol para evitar que los organismos floten y se desplacen. - Homogeneice la muestra en toda el área del marco, colocando los individuos más grandes en el centro de la bandeja para un procesamiento adecuado de la imagen, y hunda los organismos flotantes con una aguja de madera.
NOTA: Si una submuestra contiene numéricamente más de 1,000 individuos, divida la submuestra en dos o más fracciones para minimizar el contacto con organismos en la imagen escaneada y escanee las fracciones por separado. - Separe los organismos que tocan y los organismos que tocan los bordes del marco con la aguja de madera.
NOTA: Este paso requiere 5-20 min. Los organismos que tocan son considerados un solo objeto por el software; Por lo tanto, en esos casos, los tamaños individuales calculados no corresponden a organismos individuales reales y pueden sesgar la estimación de la estructura del tamaño de la comunidad. Existe la posibilidad de editar la imagen con el software de procesamiento de imágenes para separarlas, pero este paso adicional implica al menos 1,5 h de reprocesamiento; Por lo tanto, la separación manual es muy recomendable. - Para escanear la muestra, cierre la tapa del escáner, vaya al software de procesamiento de imágenes, seleccione el proyecto de trabajo y haga clic en SCAN Sample with Zooscan (For Archive, No Process).
- Seleccione la muestra y siga las instrucciones.
- Vaya al software de escaneo y haga clic en Vista previa. Asegúrese de obtener una vista previa de la imagen escaneada, verifique que no haya líneas ni puntos y espere al menos 30 s antes de comenzar otro escaneo.
- Después de al menos 30 s, haga clic en el botón Escanear en el software de escaneo.
NOTA: Pulse OK en el software de procesamiento de imágenes después de pulsar Scan en el software de escaneo. No presione ninguna tecla en el teclado de la computadora y evite las vibraciones del escaneo durante el escaneo. Se generan tres archivos en la carpeta Zooscan_scan > _raw : (i) un formato de archivo de imagen etiquetado (.tif) (16 bits); ii) un documento de texto estándar denominado LOG (.txt) que registra información sobre los parámetros de escaneo; y iii) un documento de texto normalizado denominado META (.txt) con información sobre los métodos de muestreo. - Verifique que el escaneo sin procesar sea correcto.
NOTA: Si el escaneo tiene rayas claras u otros problemas visibles, considere repetir el escaneo para evitar problemas en los siguientes pasos.
- Rellene los metadatos de ejemplo. Vaya al software de procesamiento de imágenes y seleccione Rellenar metadatos de muestra. Introduzca la identidad de la muestra, haga clic en Aceptar y rellene los metadatos.
- Recuperación de muestras
- Retire el marco y enjuáguelo por encima de la bandeja de escaneo con una botella de compresión llena de etanol al 70% para recuperar cualquier macroinvertebrado adherido.
- Levante la parte superior del escáner para recuperar todos los organismos y el etanol de la bandeja a través del embudo de recuperación de escaneo en un vaso de precipitados. Con la parte superior del escáner aún levantada, enjuague la bandeja con la botella de compresión para barrer cualquier organismo restante.
- Pase las muestras y el etanol del vaso de precipitados a través de una malla de 500 μm para retener los invertebrados en la malla y guárdelos nuevamente en un vial con etanol al 70%.
- Una vez que todas las muestras se hayan recuperado en el vial, limpie la bandeja con agua del grifo.
NOTA: Lave la bandeja con agua del grifo entre muestras para minimizar la precipitación de etanol, que altera el procesamiento de imágenes. Enjuague el marco con agua del grifo para evitar posibles daños relacionados con el uso de etanol. Al final del día, limpie la bandeja con agua del grifo y séquela suavemente con papel para evitar arañazos.
- Tratamiento de imágenes
- Vaya al software de procesamiento de imágenes y seleccione CONVERTIR y PROCESAR imágenes y organismos en modo por lotes y luego Convertir y procesar imagen Y partículas (imagen en carpeta RAW). Mantenga la configuración predeterminada y haga clic en Aceptar. NORMAL END aparecerá al final del proceso.
NOTA: Un archivo PID y las viñetas correspondientes a todos los objetos detectados en la imagen escaneada (en un archivo Joint Photographic Group [.jpg]) se crearán en la carpeta Zooscan_scan > _work. Un archivo PID es un único archivo que almacena todos los metadatos (metarchivo), los datos técnicos asociados con el archivo de registro y una tabla con 36 variables medidas de todos los objetos detectados en la imagen. Las variables medidas corresponden a diferentes estimaciones de nivel de gris, dimensión fractal, forma y tamaño. Las variables que se pueden utilizar para la estimación del tamaño son el área y los ejes mayor y menor de una elipse con un área igual al objeto (consulte la sección 3 del protocolo). El tiempo de procesamiento depende de la densidad de la imagen y las características de la computadora, y se puede iniciar entre muestras mientras se recupera y prepara la siguiente muestra. De lo contrario, se recomienda iniciar el procesamiento de las muestras escaneadas cada día en modo por lotes durante la noche y verificar el procesamiento adecuado de la imagen a la mañana siguiente. - Compruebe si el fondo de la imagen procesada se resta adecuadamente de la imagen de muestra utilizando el software de procesamiento de imágenes o comprobando las imágenes de máscara (terminadas en msk1.gif) ubicadas en Zooscan_scan > _work. Si el fondo contiene áreas saturadas o muchos puntos, considere repetir el escaneo para garantizar imágenes de alta calidad.
NOTA: Para evitar áreas saturadas en el fondo, la bandeja de escaneo debe enjuagarse con agua del grifo después de cada escaneo con etanol. También es importante (1) reducir el número de individuos escaneados (fraccionando la muestra y escaneando en diferentes pliegues); (2) asegúrese de que los organismos grandes se coloquen en el centro de la bandeja de escaneo; (3) usar etanol limpio y filtrado; (4) reducir la suciedad en las muestras; (5) asegurar que el volumen de etanol para el escaneo sea adecuado; y (6) asegúrese de que el retraso entre la vista previa de la muestra y el escaneo sea de al menos 30 s.
- Vaya al software de procesamiento de imágenes y seleccione CONVERTIR y PROCESAR imágenes y organismos en modo por lotes y luego Convertir y procesar imagen Y partículas (imagen en carpeta RAW). Mantenga la configuración predeterminada y haga clic en Aceptar. NORMAL END aparecerá al final del proceso.
- Separación de organismos que tocan
NOTA: Cuando hay varias viñetas con organismos que tocan, es necesario separar las imágenes de los organismos que tocan de otros organismos y / o de fibras / desechos para garantizar una estimación adecuada de la estructura del tamaño de la comunidad.- Vaya al software de procesamiento de imágenes para detectar las viñetas con múltiples objetos. Seleccione SEPARACIÓN usando viñetas y presione OK. En la ventana de selección de configuración, mantenga la configuración predeterminada y haga clic en Aceptar.
- En la ventana SEPARACIÓN de viñetas , mantenga la configuración predeterminada, seleccione adicionalmente AGREGAR contornos en viñetas y, a continuación, seleccione la muestra que desea editar.
- Separe los organismos que tocan en cada viñeta que aparece dibujando una línea con el mouse (presione el botón de rodar para dibujar). Una vez completada la separación en una viñeta, haga clic en el botón X en la esquina superior derecha de la ventana y presione SÍ para procesar la siguiente. Presione NO para finalizar y guardar los cambios. Al final del proceso, aparecerá NORMAL END si todo es correcto.
- Después de la separación, vuelva a procesar la imagen para obtener los datos de objeto actualizados. Vaya al software de procesamiento de imágenes, haga clic en PROCESAR (Convertido) Imagen (Proceso Uno) y seleccione Procesar de nuevo partículas de imágenes procesadas en subcarpetas WORK. Seleccione la muestra y, en la ventana Proceso de imagen única , mantenga la configuración predeterminada, marque Trabajar con máscara de separación (CREATE-MODIFY-INCLUDE) y, a continuación, haga clic en Aceptar. Al final del proceso, aparecerá NORMAL END si todo es correcto.
- En la ventana Control de separación , pulse OK para guardar la imagen con los contornos antes del procesamiento; Si existe una imagen anterior, se reemplazará.
- En la ventana Máscara de control de separación , si es necesario, seleccione EDITAR para agregar líneas de separación a la máscara usando el mouse para separar los organismos que tocan los que no han aparecido antes en el paso de separación usando viñetas. Cuando haya terminado, finalice el proceso y, en la ventana Control de máscara de separación , seleccione SÍ para aceptar la máscara. Al final del proceso, aparecerá NORMAL END si todo es correcto.
NOTA: El reprocesamiento de una muestra con una máscara de separación lleva mucho tiempo (esto podría tomar más de 1,5 h por muestra). Es preferible dedicar el tiempo requerido en el paso 1.2.5 para evitar este paso adicional.
2. Reconocimiento automático de los objetos
NOTA: Cree un conjunto de aprendizaje para predecir automáticamente la identidad de los objetos detectados, separando así los organismos de los desechos en la muestra.
- Creación de conjuntos de aprendizaje
- Copie las imágenes y los archivos .pid asociados con las imágenes que se utilizarán para crear las categorías del conjunto de aprendizaje de Zooscan_scan > _work a PID_process > Unsorted_vignettes_pid.
NOTA: Seleccione un subconjunto de muestras con alta diversidad de taxones y diferentes sitios de muestreo y/o temporadas de muestreo para garantizar la máxima representatividad de los organismos en las muestras. - En la carpeta PID_process > conjunto de aprendizaje, cree una subcarpeta con el nombre del nuevo conjunto de aprendizaje (es decir, yyyymmdd_raw_LS) y, dentro de ella, cree las subcarpetas que corresponderán a cada categoría del conjunto de aprendizaje (es decir, macroinvertebrados, escombros, otros invertebrados).
NOTA: Para obtener eficientemente la estructura del tamaño de la comunidad de las muestras de macroinvertebrados de río, se recomienda utilizar un conjunto de aprendizaje basado en solo tres categorías: macroinvertebrados, otros invertebrados y desechos. Este conjunto de aprendizaje básicamente separa las viñetas de los objetos correspondientes a los organismos de los correspondientes a los desechos (por ejemplo, fibras, partículas o algas filamentosas). - Vaya al software de procesamiento de imágenes (solo modo avanzado) y elija EXTRAER viñetas para IDENTIFICADOR DE PLANCTON (viñetas sin clasificar para entrenamiento). Mantenga las opciones predeterminadas y marque la casilla Agregar contornos .
- Vaya al software de identificación automática, haga clic en Aprendizaje, seleccione de PID_process > Learning_set la subcarpeta creada para el nuevo conjunto de aprendizaje (paso 2.1.2) y presione OK.
- En la sección izquierda (Pulgares sin ordenar) de la ventana abierta, seleccione la carpeta Sin ordenar vignettes_pid. Seleccione las viñetas y arrástrelas con el ratón desde los pulgares sin clasificar a la carpeta de su categoría correspondiente en la sección derecha, Pulgares ordenados, para clasificar cada objeto en las categorías definidas. Las viñetas movidas se marcarán con una X roja.
NOTA: Defina las categorías manualmente creando subcarpetas en la carpeta de pulgares ordenados o créelas haciendo clic en el icono de carpetas en el software. No mueva más de 50 viñetas al mismo tiempo. - Una vez completadas todas las categorías con los objetos seleccionados (unos 300 objetos por categoría), haga clic en Crear archivo de aprendizaje y guárdelo con el nombre deseado.
NOTA: El conjunto de aprendizaje se guardará como un archivo .pid en la carpeta PID_process > conjunto de aprendizaje del proyecto. Se recomienda crear y probar varios conjuntos de aprendizaje con diferentes niveles de categorías (desde formas gruesas hasta finas) y con un equilibrio diferente del número de objetos dentro de cada categoría. Comience con un conjunto de aprendizaje grueso con un número bajo de categorías y al menos 50 objetos por categoría, y luego aumente el número de objetos en cada categoría y / o cree conjuntos de aprendizaje más finos. Una categoría debe ser representativa de su variabilidad en el conjunto de muestras.
- Copie las imágenes y los archivos .pid asociados con las imágenes que se utilizarán para crear las categorías del conjunto de aprendizaje de Zooscan_scan > _work a PID_process > Unsorted_vignettes_pid.
- Evaluación del conjunto de aprendizaje
NOTA: Realice la validación cruzada con dos pliegues y cinco ensayos utilizando el método Random Forest con el software de identificación automática para obtener una matriz de confusión de la clasificación resultante de los objetos.- Vaya al software de clasificación automática y haga clic en Análisis de datos.
- En Seleccionar archivo de aprendizaje, seleccione el archivo de conjunto de aprendizaje creado en PID_process > conjunto de aprendizaje.
- En Seleccionar un método, elija el método de bosque aleatorio de validación cruzada . En Variables originales, desmarque las variables de posición (X, Y, XM, YM, BX, BY y Altura). En Variables personalizadas, marque solo ESD.
NOTA: Este método utiliza una parte aleatoria del conjunto de aprendizaje para reconocer la otra parte (dos pliegues), y esto se repite cinco veces para garantizar que sea estadísticamente robusto. - Haga clic en Iniciar análisis y guarde los resultados como Analysis_name.txt en la carpeta PID_process > Predicción. Cuando el análisis se haya completado correctamente, salga del análisis de datos.
- Vaya a la carpeta PID_process > Prediction y haga clic en el archivo de validación cruzada. Aparecerá una ventana con la matriz de confusión de la clasificación verdadera (filas) frente a la clasificación automática (columnas).
NOTA: El recuerdo es el porcentaje de organismos pertenecientes a un grupo que fue automáticamente bien reconocido, mientras que la precisión 1 es el porcentaje de organismos clasificados por el algoritmo como un grupo que no se reconoce (contaminación en un grupo). La retirada debe ser superior al 70%, y la contaminación (precisión 1) debe ser inferior al 20%. - Repita los pasos 2.1-2.5 si se crearon varios conjuntos de aprendizaje y se debe obtener la recuperación y la precisión 1 de cada uno.
NOTA: Si se han creado varios conjuntos de aprendizaje, elija el que tenga el mayor recuerdo (buen reconocimiento) y precisión (baja contaminación) del grupo de interés (es decir, macroinvertebrados) para probar la predicción automática de un conjunto de muestras en el siguiente paso.
- Predicción de la identificación de macroinvertebrados
NOTA: Utilice el conjunto de aprendizaje seleccionado para predecir la identidad de todos los objetos de un subconjunto de muestras utilizando el software de identificación automática con un algoritmo de bosque aleatorio.- Vaya al software de identificación automática y haga clic en Análisis de datos.
- En Seleccionar archivo de aprendizaje, seleccione el archivo de conjunto de aprendizaje de PID_process > conjunto de aprendizaje que se debe usar para la predicción.
- En Seleccionar archivo(s) de muestra, seleccione en la carpeta PID_results las muestras (archivos PID) que se van a predecir.
Nota: Procese un máximo de 20 archivos .pid al mismo tiempo para evitar errores relacionados con problemas de memoria. Si se procesan demasiados archivos .pid al mismo tiempo, el proceso mostrará un final correcto, pero es posible que no se procese bien, y puede producirse un error en los siguientes pasos al procesar con el software de procesamiento de imágenes. - En Seleccionar un método, elija el método Bosque aleatorio . Marque Guardar resultados detallados para cada muestra. En Variables originales, desmarque las variables de posición (X, Y, XM, YM, BX, BY y Height). En Variables personalizadas, marque solo ESD.
- Haga clic en Iniciar análisis y guarde los resultados como Analysis_name.txt en la carpeta PID_process > Predicción.
- Validación manual
NOTA: Un experto valida manualmente la predicción del paso anterior para reclasificar los objetos clasificados erróneamente en la categoría correcta.- Copie los archivos Analysis_sample_dat1.txt que se van a validar de la carpeta PID_process > Predicción a la carpeta PID_process > Pid_results.
- Vaya al software de procesamiento de imágenes y seleccione EXTRAER viñetas en carpetas según PREDICCIÓN o VALIDACIÓN. Luego, seleccione Usar archivos PREDICTADOS de la carpeta "pid_results". Mantenga la configuración predeterminada y pulse OK.
- El software crea una carpeta llamada sample_yyyymmdd_hhmm_to_validate con los objetos previstos en la carpeta PID_process > viñetas ordenadas.
- Vaya a la carpeta PID_process > Viñetas ordenadas y copie la carpeta sample_yyyymmdd_ hhmm_to_validate. Reemplace el nombre de la carpeta _to validar con _validated.
- Para validar manualmente la clasificación automática, abra la sample_yyyymmdd_ hhmm_validated de carpeta y revise todas las viñetas de cada subcarpeta (categoría) para identificar si hay objetos clasificados erróneamente. Cuando un objeto está mal clasificado, arrastre la viñeta con el ratón a la carpeta (categoría) correcta.
- Vaya al software de procesamiento de imágenes y seleccione CARGAR identificaciones de viñetas ordenadas. Mantenga la configuración predeterminada y seleccione yyyymmdd_hhmm_name_validated que desea procesar.
- Vaya a PID_process > Pid_results > Dat1_validated, donde se han creado un archivo denominado Id_from_sorted_vignettes_yyyymmdd_hhmm.txt y un archivo .txt para cada una de las muestras validadas (sample_tot_1_dat1.txt).
Nota: Estos archivos .txt contienen una nueva columna que presenta la predicción, denominada pred_valid_Id_yyyymmdd_hhmm, que especifica la clasificación experta de cada objeto (es decir, la clasificación validada). Se podrían crear nuevas categorías (por ejemplo, categorías taxonómicas más finas) en este punto, durante la validación. Sin embargo, mantenga el nombre de la categoría original en el nuevo nombre (por ejemplo, macroinvertebrate_chironomidae). Esto permite volver sobre la categoría original al calcular el recuerdo y la precisión y agrupar fácilmente todos los macroinvertebrados para calcular los parámetros de la estructura del tamaño de la comunidad (es decir, el espectro de tamaño y la diversidad de tamaños). El archivo de texto proporciona los datos asociados con cada objeto, incluidos los ejes menor y mayor que se utilizan para obtener el volumen elipsoidal de cada organismo como medida del tamaño corporal individual. Además, las dos últimas columnas de la tabla contienen las categorías predichas y validadas de cada objeto (fila), que permiten calcular, por categoría, el recuerdo y la precisión del conjunto de aprendizaje en el subconjunto de muestras.
Figura 1: Diagrama de trabajo que representa la sección 1 y la sección 2 del protocolo. Los tiempos son ilustrativos y pueden cambiar dependiendo de la computadora, la abundancia de viñetas para procesar y el número de categorías del conjunto de aprendizaje. Este caso corresponde a la validación de un conjunto de aprendizaje de tres categorías en un conjunto de 42 submuestras (en total, 47.473 viñetas). Haga clic aquí para ver una versión más grande de esta figura.
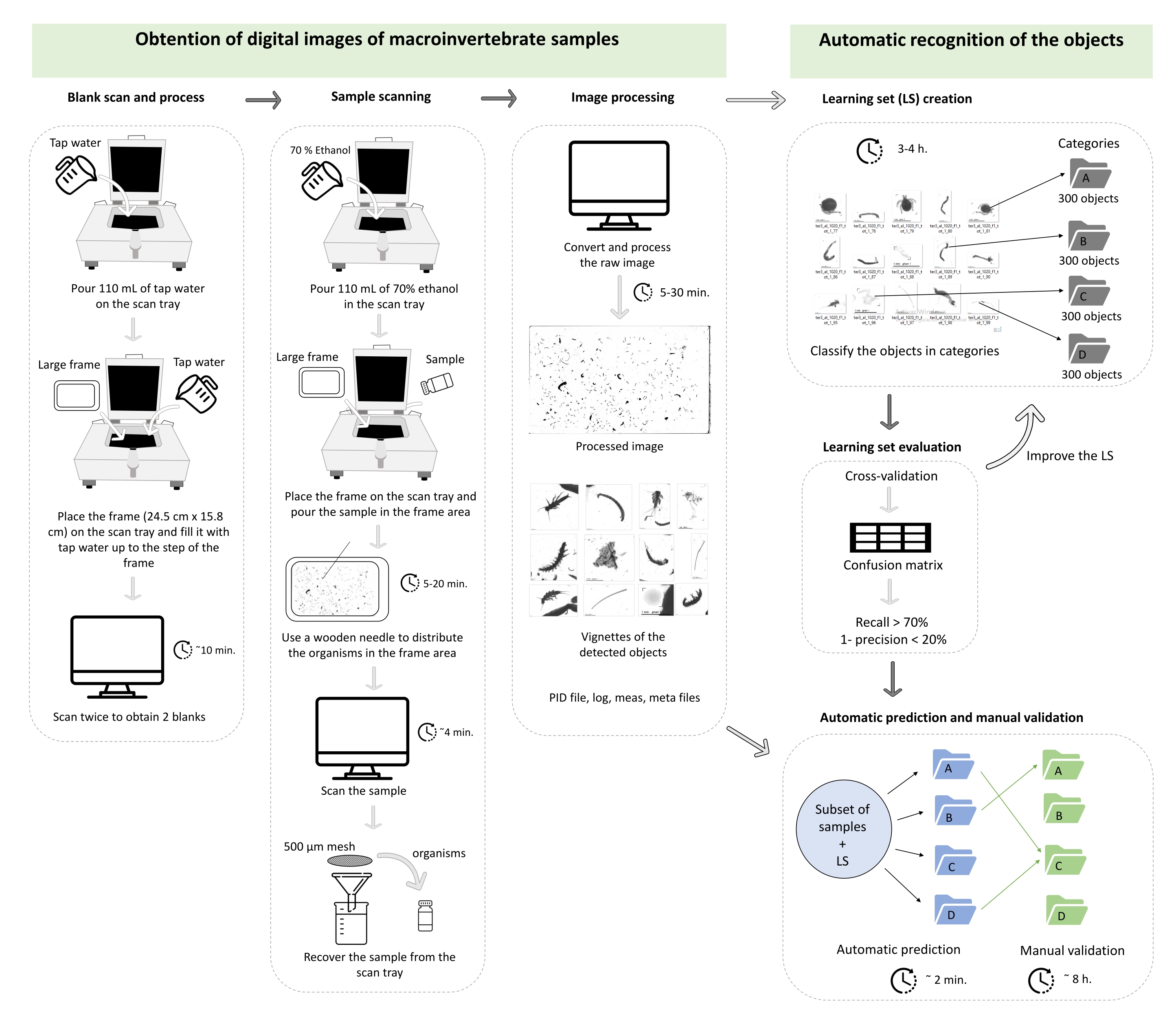{kind=link}
3. Calcular la distribución de tamaño individual, los espectros de tamaño y las métricas de tamaño
NOTA: Los cálculos mencionados en esta sección se realizaron utilizando Matlab (consulte el script como archivo complementario 1).
- Distribución individual del tamaño
- La última columna del archivo de Id_from_sorted_vignettes_YYYYMMDD_HHHH.txt contiene la clasificación validada de los objetos. Seleccione solo los objetos clasificados como macroinvertebrados para representar su distribución de tamaño individual en la muestra.
NOTA: El tamaño corporal individual corresponde al volumen elipsoidal de los organismos macroinvertebrados. El sistema proporciona mediciones en píxeles. - Concatena los vectores con las medidas de tamaño de ambos escaneos, porque cada fracción tiene un exponente de submuestreo diferente. Antes de la concatenación, corrija el fraccionamiento replicando los vectores de tamaño tantas veces como se haya fraccionado la submuestra correspondiente.
NOTA: Este paso es necesario si una exploración corresponde a una fracción de una muestra (es decir, gruesa o fina). - Calcula el volumen elipsoidal a partir de los ejes mayor (M) y menor (m) de los elipsoides prolatos con las mismas áreas de píxeles que los organismos. Antes de calcular el volumen elipsoidal, convierta los ejes mayor (M) y menor (m) de píxeles a milímetros (mm) con el siguiente factor de conversión (cf):
1 píxel = 2.400 ppp
1 pulgada = 25,4 mm
cf = 25,4/2400
El volumen elipsoidal (elipVol con unidades en mm3) corresponde a:
- Representar la función de densidad de probabilidad de la distribución de tamaño individual en la escala logarítmica2 .
- La última columna del archivo de Id_from_sorted_vignettes_YYYYMMDD_HHHH.txt contiene la clasificación validada de los objetos. Seleccione solo los objetos clasificados como macroinvertebrados para representar su distribución de tamaño individual en la muestra.
- Diversidad de tamaños
- Calcule la diversidad de tallas (Sd) siguiendo a Quintana et al. (2008)8, como en García-Comas et al. (2016)35:

donde p x(x) es la función de densidad de probabilidad de tamaño x, y x representa log2 (elipVol). Esta medida es, por lo tanto, el índice de diversidad de Shannon adaptado a una medida continua, como la distribución del tamaño individual en una comunidad.
- Calcule la diversidad de tallas (Sd) siguiendo a Quintana et al. (2008)8, como en García-Comas et al. (2016)35:
- Espectro normalizado de tamaño de biovolumen (NBSS)
- Definir las clases de tamaño de la NBSS, estableciendo el límite inferior del espectro como el cuantil 0.01 de la distribución de tamaño de macroinvertebrados en las muestras y creando clases de tamaño por una escala geométrica de base 2 hasta que se abarque el organismo más grande en las muestras.
NOTA: El ancho de clase de tamaño aumenta con el tamaño para tener en cuenta la mayor variabilidad asociada con tamaños mayores. Las NBSS de las comunidades de macroinvertebrados analizadas aquí tuvieron 14 clases de tamaño (Tabla 1). - Obtenga el biovolumen normalizado dividiendo el biovolumen total en cada clase de tamaño por el ancho de la clase de tamaño.
- Definir las clases de tamaño de la NBSS, estableciendo el límite inferior del espectro como el cuantil 0.01 de la distribución de tamaño de macroinvertebrados en las muestras y creando clases de tamaño por una escala geométrica de base 2 hasta que se abarque el organismo más grande en las muestras.
- Pendiente del espectro de tamaño
- Calcular la pendiente lineal del NBSS.
NOTA: La pendiente (μ) se calcula en función de la relación entre el log 2 (punto medio de la clase de tamaño) y el log2 (biomasa normalizada) en las clases de tamaño mayores que el modo, ignorando las vacías (en este estudio, las clases de tamaño de 3 a 14).
- Calcular la pendiente lineal del NBSS.
| Límites de clase de tamaño (mm3) | Clase de tamaño punto medio (mm3) |
| 0,1236 | 0,1855 |
| 0,2473 | 0,3709 |
| 0,4946 | 0,7418 |
| 0,9891 | 1,4837 |
| 1,9783 | 1,4837 |
| 3,9560 | 5,9348 |
| 7,9131 | 11,8696 |
| 15,8261 | 23,7392 |
| 31,6522 | 47,4783 |
| 63,3044 | 94,9567 |
| 126,6089 | 189,9133 |
| 253,2178 | 379,8267 |
| 506,4300 | 7597,7000 |
| 1012,9000 | 15193,0000 |
| 2025,7000 |
Tabla 1: Clases de tamaño del espectro normalizado de tamaño de biomasa (NBSS). La tabla también muestra los límites de clase de tamaño 15 y los puntos medios de clase de tamaño de los organismos.
Resultados
Adquisición de imágenes digitales de muestras de macroinvertebrados
Matices de escaneo: Deposición de etanol en la bandeja de escaneo
Mientras probaban el sistema para macroinvertebrados, varios escaneos fueron de mala calidad. Un área oscura saturada en el fondo impidió el procesamiento normal de la imagen y la medición de los tamaños individuales de los macroinvertebrados (Figura 2). Se han dado varias razones para la aparición de áreas satu...
Discusión
La adaptación de la metodología descrita por Gorsky et al. 2010 para macroinvertebrados ribereños permite una alta precisión de clasificación en la estimación de la estructura del tamaño de la comunidad en macroinvertebrados de agua dulce. Los resultados sugieren que el protocolo puede reducir el tiempo para estimar la estructura de tamaño individual en una muestra a aproximadamente 1 hora. Por lo tanto, el protocolo propuesto está destinado a promover el uso rutinario de espectros de tamaño de macroinvertebrad...
Divulgaciones
Los autores declaran que no hay intereses potenciales en conflicto.
Agradecimientos
Este trabajo ha contado con el apoyo del Ministerio de Ciencia, Innovación y Universidades (número de subvención RTI2018-095363-B-I00). Agradecemos a los miembros del CERM-UVic-UCC Èlia Bretxa, Anna Costarrosa, Laia Jiménez, María Isabel González, Marta Jutglar, Francesc Llach y Núria Sellarès su trabajo en muestreo de campo de macroinvertebrados y clasificación de laboratorio y a David Albesa por colaborar en el escaneo de muestras. Por último, agradecemos a Josep Maria Gili y al Institut de Ciències del Mar (ICM-CSIC) el uso de las instalaciones del laboratorio y del dispositivo escáner.
Materiales
| Name | Company | Catalog Number | Comments |
| Beaker | Labbox | Other containers could be used | |
| Dionized water | Icopresa | 8420239600123 | To dilute the ethanol |
| Funnel | Vitlab | 41094 | |
| Glass vials 8 ml | Labbox | SVSN-C10-195 | 1 vial/subsample |
| ImageJ Software | Free access | Version 4.41o/ Image processing software | |
| Large frame | Hydroptic | Provided by ZooScan | 24.5 cm x 15.8 cm |
| Monalcol 96 (Ethanol 96) | Montplet | 1050JE001 | |
| Plankton Identifier Software | Free access | Version 1.2.6/ Automatic identification software | |
| Sieve | Cisa | 26852.2 | Nominal aperture 500µ and nominal aperture 0,5 cm |
| Tweezers | Bondline | B5SA | Stainless, anti-magnetic, anti-acid |
| VueScan 9 x 64 (9.5.09) Software | Hydroptic | Version 9.0.51/ Sacn software | |
| Wooden needle | Any plastic or wood needle can be used | ||
| Zooprocess Software | Free access | Version 7.14/Image processing software | |
| ZooScan | Hydroptic | 54 | Version III/ Scanner |
Referencias
- Birk, S., et al. Three hundred ways to assess Europe's surface waters: An almost complete overview of biological methods to implement the Water Framework Directive. Ecological Indicators. 18, 31-41 (2012).
- Basset, A., Sangiorgio, F., Pinna, M. Monitoring with benthic macroinvertebrates: advantages and disadvantages of body size descriptors. Aquatic Conservation: Marine and Freshwater Ecosystems. 14, S43-S58 (2004).
- Reyjol, Y., et al. Assessing the ecological status in the context of the European Water Framework Directive: Where do we go now. Science of the Total Environment. 497-498, 332-344 (2014).
- Brown, J. H., Gillooly, J. F., Allen, A. P., Savage, V. M., West, G. B. Toward a metabolic theory of ecology. Ecology. 85 (7), 1771-1789 (2004).
- Woodward, G., et al. Body size in ecological networks. Trends in Ecology & Evolution. 20 (7), 402-409 (2005).
- Sprules, W. G., Barth, L. E. Surfing the biomass size spectrum: Some remarks on history, theory, and application. Canadian Journal of Fisheries and Aquatic Sciences. 73 (4), 477-495 (2016).
- White, E. P., Ernest, S. K. M., Kerkhoff, A. J., Enquist, B. J. Relationships between body size and abundance in ecology. Trends in Ecology & Evolution. 22 (6), 323-330 (2007).
- Quintana, X. D., et al. A nonparametric method for the measurement of size diversity with emphasis on data standardization. Limnology and Oceanography - Methods. 6 (1), 75-86 (2008).
- Blanchard, J. L., Heneghan, R. F., Everett, J. D., Trebilco, R., Richardson, A. J. From bacteria to whales: Using functional size spectra to model marine ecosystems. Trends in Ecology & Evolution. 32 (3), 174-186 (2017).
- Petchey, O. L., Belgrano, A. Body-size distributions and size-spectra: Universal indicators of ecological status. Biology Letters. 6 (4), 434-437 (2010).
- Emmrich, M., et al. Geographical patterns in the body-size structure of European lake fish assemblages along abiotic and biotic gradients. Journal of Biogeography. 41 (12), 2221-2233 (2014).
- Arranz, I., Brucet, S., Bartrons, M., García-Comas, C., Benejam, L. Fish size spectra are affected by nutrient concentration and relative abundance of non-native species across streams on the NE Iberian Peninsula. Science of the Total Environment. 795, 148792 (2021).
- Vila-Martínez, N., Caiola, N., Ibáñez, C., Benejam, L. l., Brucet, S. Normalized abundance spectra of the fish community reflect hydropeaking on a Mediterranean large river. Ecological Indicators. 97, 280-289 (2019).
- Benejam, L. l., Tobes, I., Brucet, S., Miranda, R. Size spectra and other size-related variables of river fish communities: systematic changes along the altitudinal gradient on pristine Andean streams. Ecological Indicators. 90, 366-378 (2018).
- Sutton, I. A., Jones, N. E. Measures of fish community size structure as indicators for stream monitoring programs. Canadian Journal of Fisheries and Aquatic Sciences. 77 (5), 824-835 (2019).
- Murry, B. A., Farrell, J. M. Resistance of the size structure of the fish community to ecological perturbations in a large river ecosystem. Freshwater Biology. 59, 155-167 (2014).
- Townsend, C. R., Thompson, R. M., Hildrew, A. G., Raffaelli, D. G., Edmonds-Brown, R. Body size in streams: Macroinvertebrate community size composition along natural and human-induced environmental gradients. In Body Size: The Structure and Function of Aquatic Ecosystems. , (2007).
- Gjoni, V., et al. Patterns of functional diversity of macroinvertebrates across three aquatic ecosystem types, NE Mediterranean. Mediterranean Marine Science. 20 (4), 703-717 (2019).
- Pomeranz, J. P. F., Warburton, H. J., Harding, J. S. Anthropogenic mining alters macroinvertebrate size spectra in streams. Freshwater Biology. 64 (1), 81-92 (2019).
- García-Girón, J., et al. Anthropogenic land-use impacts on the size structure of macroinvertebrate assemblages are jointly modulated by local conditions and spatial processes. Environmental Research. 204, 112055 (2022).
- Demi, L. M., Benstead, J. P., Rosemond, A. D., Maerz, J. C. Experimental N and P additions alter stream macroinvertebrate community composition via taxon-level responses to shifts in detrital resource stoichiometry. Functional Ecology. 33 (5), 855-867 (2019).
- Basset, A., et al. A benthic macroinvertebrate size spectra index for implementing the Water Framework Directive in coastal lagoons in Mediterranean and Black Sea ecoregions. Ecological Indicators. 12 (1), 72-83 (2012).
- Ärje, J., et al. Automatic image-based identification and biomass estimation of invertebrates. Methods in Ecology and Evolution. 11 (8), 922-931 (2020).
- Raitoharju, J., et al. Benchmark database for fine-grained image classification of benthic macroinvertebrates. Image and Vision Computing. 78, 73-83 (2018).
- Lytle, D. A., et al. Automated processing and identification of benthic invertebrate samples. Journal of the North American Benthological Society. 29 (3), 867-874 (2010).
- Serna, J. P., Fernández, D. S., Vélez, F. J., Aguirre, N. J. An image processing method for recognition of four aquatic macroinvertebrates genera in freshwater environments in the Andean region of Colombia. Environmental Monitoring and Assessment. 192, 617 (2020).
- Gorsky, G., et al. Digital zooplankton image analysis using the ZooScan integrated system. Journal of Plankton Research. 32 (3), 285-303 (2010).
- Marcolin, C. R., Schultes, S., Jackson, G. A., Lopes, R. M. Plankton and seston size spectra estimated by the LOPC and ZooScan in the Abrolhos Bank ecosystem (SE Atlantic). Continental Shelf Research. 70, 74-87 (2013).
- Silva, N., Marcolin, C. R., Schwamborn, R. Using image analysis to assess the contributions of plankton and particles to tropical coastal ecosystems. Estuarine, Coast and Shelf Science. 219, 252-261 (2019).
- Vandromme, P., et al. Assessing biases in computing size spectra of automatically classified zooplankton from imaging systems: A case study with the ZooScan integrated system. Methods in Oceanography. 1-2, 3-21 (2012).
- Naito, A., et al. Surface zooplankton size and taxonomic composition in Bowdoin Fjord, north-western Greenland: A comparison of ZooScan, OPC and microscopic analyses. Polar Science. 19, 120-129 (2019).
- . Zooprocess/Plankton Identifier protocol for computer assisted zooplankton sorting Available from: https://manualzz.com/doc/43116355/zooprocess—plankton-identifier-protocol-for (2013)
- Protocolo de muestreo y laboratorio de fauna bentónica de invertebrados en ríos vadeables. CÓDIGO: ML-Rv-I-2013. Ministerio de Agricultura, Alimentación y Medio Ambiente Available from: https://www.miteco.gob.es/es/agua/temas/estado-y-calidad-de-las-aguas/ML-Rv-I-2013_Muestreo%20y%20laboratorio_Fauna%20bent%C3%B3nica%20de%20de%20invertebrado_%20R%C3%Ados%20vadeables_24_05_2013_tcm30-175284.pdf (2013)
- García-Comas, C., et al. Prey size diversity hinders biomass trophic transfer and predator size diversity promotes it in planktonic communities. Proceedings of the Royal Society Biological Sciences. 283 (1824), 20152129 (2016).
- García-Comas, C., et al. Mesozooplankton size structure in response to environmental conditions in the East China Sea: How much does size spectra theory fit empirical data of a dynamic coastal area. Progress in Oceanography. 121, 141-157 (2014).
- Marquina, D., Buczek, M., Ronquist, F., Lukasik, P. The effect of ethanol concentration on the morphological and molecular preservation of insects for biodiversity studies. PeerJ. 9, 10799 (2021).
- Bell, J. L., Hopcroft, R. R. Assessment of ZooImage as a tool for the classification of zooplankton. Journal of Plankton Research. 30 (12), 1351-1367 (2008).
- Colas, F., et al. The ZooCAM, a new in-flow imaging system for fast onboard counting, sizing and classification of fish eggs and metazooplankton. Progress in Oceanography. 166, 54-65 (2018).
- Bachiller, E., Fernandes, J. A., Irigoien, X. Improving semiautomated zooplankton classification using an internal control and different imaging devices. Limnology and Oceanography Methods. 10 (1), 1-9 (2012).
Reimpresiones y Permisos
Solicitar permiso para reutilizar el texto o las figuras de este JoVE artículos
Solicitar permisoExplorar más artículos
This article has been published
Video Coming Soon
ACERCA DE JoVE
Copyright © 2025 MyJoVE Corporation. Todos los derechos reservados