
Method Article
Долговечный чтения последовательности для анализа всей геномной ДНК
В этой статье
Резюме
Лонг чтения последовательности значительно облегчить Ассамблее сложные геномы и характеристика структурных изменения. Мы описываем метод для создания ультра-длинные последовательности на основе Нанопор виртуализации платформ. Этот подход принимает оптимизированный экстракции ДНК, а затем изменение библиотеки препаратов для создания сотен kilobase читает с умеренной покрытие из клеток человека.
Аннотация
Третьего поколения, что сингл молекула ДНК последовательности технологии предлагают значительно больше читать длина, которая может содействовать Ассамблея сложных геномов и анализ сложных структурных вариантов. Нанопор платформах выполняют одной молекулы последовательности непосредственно измеряя текущие изменения, при посредничестве ДНК проход через поры и может генерировать сотни читает kilobase (КБ) с минимальными затратами капитала. Эта платформа была принята многими исследователями для различных приложений. Достижения длины последовательности чтения является наиболее важным фактором использовать значение Нанопор виртуализации платформ. Для создания ультра-длинный читает, особое внимание требуется избежать поломки ДНК и повышение эффективности для создания производственной последовательности шаблоны. Здесь мы предоставляем подробный протокол долговечный секвенирования ДНК, включая экстракции ДНК высокой молекулярной массой (HMW) из свежих или замороженных клеток, Библиотека строительство механической резки или Транспозаза фрагментации и виртуализации на устройстве Нанопор. От 20-25 мкг HMW ДНК метод можно добиться N50, читать длиной 50-70 КБ с механической резки и N50 90-100 КБ читать длина с Транспозаза при посредничестве фрагментации. Протокол может применяться к ДНК, извлеченные из клеток млекопитающих для выполнения всего генома для выявления структурных вариантов и геном Ассамблеи. Дополнительные усовершенствования на экстракции ДНК и ферментативных реакций будет далее увеличить длину чтения и расширять его полезности.
Введение
За последнее десятилетие массивно параллельной и высокоточные второго поколения высокопроизводительного секвенирования технологии заставили взрыв биомедицинских открытий и технологических инноваций в1,2,3. Несмотря на технический прогресс короткие чтение данных, генерируемых второго поколения платформы являются неэффективными в урегулировании сложных регионах геномной и ограничены в обнаружении геномной структурных вариантов (СВС), которые играют важную роль в человека Эволюция и болезней4,5. Кроме того короткий чтение данных не удается разрешить повторные изменения и непригодны для взыскательных гаплотип поэтапного генетических вариантов6.
Недавний прогресс в одной молекулы последовательности предлагает значительно больше читать длина, которая может облегчить обнаружение полный спектр СВС7,8,9, и предлагает точные и полные собрания комплекса микробов и млекопитающих геномов6,10. Нанопор платформа выполняет секвенирование одной молекулы, непосредственно измерения текущих изменений при посредничестве ДНК прохода через поры11,12,13. В отличие от любых существующих химия секвенирования ДНК, Нанопор последовательности может генерировать Лонг (десятки тысяч kilobases) читает в режиме реального времени, не полагаясь на кинетику полимеразы или искусственные амплификации ДНК образца. Таким образом Нанопор Лонг чтения последовательности (РНБ seq) имеет большие перспективы для создания ультра-чтения длинных далеко за 100 КБ, что значительно ускорит геномных и биомедицинских анализов14, особенно в низкой сложности или повторить богатые регионы в геномах15.
Уникальная особенность Нанопор последовательности является его способность генерировать длинный читает без ограничения теоретическая длина. Таким образом чтение длина зависит от физической длина ДНК, которая напрямую зависит от качества шаблон целостности и последовательности ДНК. Кроме того в зависимости от степени манипуляции и количество шагов, например дозирования сил и условий извлечения, качество ДНК является крайне непостоянны. Таким образом это является сложной задачей для одного, чтобы принести долго читает, просто применив стандартные протоколы извлечения дна и производителя предоставленного библиотеки строительных методов. С этой целью мы разработали надежный метод для создания ультра-долгий читать (сотни kilobases) последовательности данных, начиная от заготовленных клеток окатышей. Мы приняли несколько улучшений в процедуре подготовки ДНК добычи и библиотека. Мы рационализированы протокол для исключения ненужных процедур, которые вызывают деградации ДНК и убытки. Этот протокол состоит из высокой молекулярной массой (HMW) экстракции ДНК, ультра-длинный строительство библиотеки ДНК и последовательности на платформе Нанопор. Для хорошо подготовленных молекулярный биолог обычно занимает 6 h от заготовки до завершения извлечения HMW ДНК, 90 мин или 8 h для строительства библиотеки в зависимости от метода сдвига и еще 48 h для секвенирования ДНК клетки. Использование протокола позволит геномики сообщество для улучшения нашего понимания сложности генома и получить новое понимание изменения генома в заболеваниях человека.
протокол
Примечание: РНБ seq протокол состоит из трех последовательных этапов: 1) добыча высокомолекулярный вес геномной ДНК (HMW); 2) ультра-долгий строительство библиотеки ДНК, которая включает в себя фрагментация ДНК HMW в желаемых размеров и перевязка адаптеров секвенирования ДНК заканчивается; и 3) Загрузка лигируют адаптер ДНК на массивы Нанопоры (рис. 1).
1. HMW ДНК добыча
- Реагент установки. Сделать 1 x фосфатного буфера буферизации физраствора (PBS) (1000 мл), добавив 100 мл PBS (10 x) до 900 мл воды и хорошо перемешать. Сделайте буфера lysis (50 мл), добавив 43,5 мл воды 50 мл трубки. Добавьте 500 мкл трис (1 М, рН 8,0), 1 мл раствора хлорида натрия (NaCl) (5 М), 2,5 мл Этилендиаминтетрауксусная кислота (ЭДТА) (0,5 М, pH 8.0) и 2,5 мл натрия Додециловый сульфат (SDS) (10%, wt/vol) на трубу и хорошо перемешайте.
Примечание: Этот буфер PBS может храниться при температуре 4 ° C на срок до 6 месяцев. Готовые литического буфера может храниться в РТ на срок до 2 месяцев. - Проверьте ячейки смертности и подсчитать количество ячеек. Убедитесь, что живой соотношение > 85% и общей ячейки номер 30 x 10-6.
Примечание: Клетки, используемые в настоящем Протоколе, от линии клеток HG00733, человека лимфобластоидных клеток линии Пуэрто-риканского происхождения, широко используется в 1000 геноме консорциум для анализа структурные изменения (см. таблицу материалов для заказа информация), которая принадлежит Международные генома образца ресурс. - Собирать клетки центрифугированием на 200 x g 5 мин на RT. Discard среднего и Ресуспензируйте ячейки Пелле (30 х 106 клеток) с 5 мл 1 x PBS буфера. Центрифуга снова на 200 x g 5 мин в RT и удалить супернатант.
Примечание: 25-35 x 106 клеток являются приемлемыми для этого подхода. Дальнейшие изменения в размере ячеек, которые используются потребуют дальнейшего оптимизации. Пелле клетки могут храниться в −80 ° C на срок до 6 месяцев. - Ресуспензируйте Пелле клеток в 200 мкл 1 x PBS буфера. Если использование замороженных клеток Пелле, мыть с 5 мл 1 x PBS буфера. Центрифуга решение на 200 x g 5 мин на RT, удалить супернатант и Ресуспензируйте клетки в 200 мкл 1 x PBS буфера.
- Подготовка 10 мл буфера lysis в 50 мл трубки. Добавьте 200 мкл суспензии клеток литического буфера и вихрь на максимальной скорости для 3 s. инкубировать решение при 37 ° C в течение 1 ч.
- Добавьте 2 мкл РНКазы A (100 мг/мл) в lysate. Осторожно поверните Тюбик 50 мл смеси образца. Инкубируйте решение при 37 ° C в течение 1 ч.
- Добавьте 50 мкл протеиназы K (20 мг/мл) в lysate. Осторожно поверните Тюбик 50 мл смеси образца. Инкубируйте решение при 50 ° C за 2 ч. Во время инкубации Аккуратно перемешайте образец каждые 30 мин.
- Удаление 50 мл трубки из 50 ° C и дать постоять 5 мин в рт.
- Добавить 10 мл фенола слой фенола: хлороформ: изоамилового спирта (25:24:1, vol/vol/vol) в lysate и поверните трубку на смесителе ротатор (см. Таблицу материалы) на RT в Зонта на 20 об/мин за 10 мин заверните крышку трубки с парафина для предотвращения утечки во время вращения.
- Подготовить два 50 мл гель трубы (см. Таблицу материалы) центрифугированием на 1500 x g на 2 мин на RT.
Примечание: Гель образует стабильные барьер между нуклеиновой кислоты, содержащий водной фазе и органических растворителях. - Залейте раствор образца/фенола в одной из подготовленных 50 мл гель трубы с шагом 1,10. Центрифуга решение на 3000 x g 10 мин на RT.
- Залейте супернатант в новый Тюбик 50 мл. Добавить 10 мл фенола слой фенола: хлороформ: изоамилового спирта (25:24:1, vol/vol/vol) и поверните трубку на ротатор смеситель на RT в вытяжной шкаф при 20 об/мин за 10 мин.
- Повторите шаг 1.11 раз со вторым подготовлен гель трубки.
- Залейте супернатант в новый Тюбик 50 мл. Добавить 25 мл ледяной 100% этанола и аккуратно поверните трубку вручную ДНК осаждает (рис. 2).
Примечание: Осадков подход помогает стабилизировать HMW ДНК. - Согните кончик 20 мкл сделать крюк. Тщательно взять HMW ДНК с крюком и отпускать жидкие капли.
- Поместите HMW ДНК в Тюбик 50 мл, содержащие 40 мл 70% этанола. Вымойте ДНК, нежно инвертирование трубку 3 раза.
- Повторите шаг 1,15 раз для сбора ДНК из трубки, этанол 70%.
- Поместите HMW ДНК в 2-мл пробирку, содержащие 1.8 мл 70% этанола.
- Центрифуга промывают HMW ДНК на 10000 x g для 3 s на RT. удалить столько остаточного этанола как можно скорее, закупорить.
Примечание: Не беспокоить Пелле ДНК при закупорить остаточных этанола. - Проинкубируйте 2 мл при 37 ° C 10 мин с открытой для просушки образца крышкой.
- Если продолжить с шаг 2.1 (с механической резки и 1 D лигирование последовательности Kit), добавьте 1 mL TE (10 мм 1 мм и трис ЭДТА, рН 8.0) в 2-мл пробирку.
- Если продолжить с шагом 2.2 (на основе Транспозаза фрагментации и быстрой последовательности Kit), добавить 200 мкл 10 мм трис (рН 8,0) с 0,02% Тритон X-100.
Примечание: Не беспокоить Пелле ДНК. Позволяя трубки стоять на 4 ° C в темном 48 h поможет полностью Ресуспензируйте образца. HMW ДНК может храниться при температуре 4 ° C на срок до 2 недель. Длиннее время хранения или других условий хранения могут вводить более короткие фрагменты.
2. долговечный строительство библиотеки ДНК
Примечание: Существует два способа для создания ультра-долгий библиотеки ДНК, на основе двух различных методов режа, в сочетании с Нанопор последовательности комплекты. Механический стрижки на основе библиотеки производит данные с N50 50-70 КБ, принимая около 8 ч на строительство библиотеки. Транспозаза библиотека на основе фрагментации производит N50 90-100 КБ данных, принимая только 90 мин на строительство библиотеки. Механических ножниц протокол дает высокую доходность от же ДНК, вход с использованием одинаковых версий адаптер последовательности и качества Нанопор потока клеток.
- Конструкция механической стрижки на основе библиотеки
- Оттепель и смеси реагентов от перевязки комплекта (см. Таблицу материалы). Оттепели FFPE ДНК ремонт буфера и конец буфера ремонт/dA хвостохранилища на льду, затем вихря и спина до микс. Оттепель адаптер микс (AMX) и адаптер шарик привязки буфера (АББ) на льду, а затем пипеткой и спин вниз смешивать. Оттепель работает буфер с топливной смеси (РБФ) и Элюирующий буфер (СОБ) на RT, а затем вихря и спин вниз смешивать. Оттепель загрузкой бусины (LLB) библиотек в RT и пипетки перемешать перед использованием.
- После размораживания, держите все компоненты комплекта на льду. Вывезти ферменты только при необходимости. Магнитные бусы привлечь RT для использования.
Примечание: Рекомендации по магнитные шарики использовать таблица материалов.
- После размораживания, держите все компоненты комплекта на льду. Вывезти ферменты только при необходимости. Магнитные бусы привлечь RT для использования.
- Проверьте качество и количество HMW ДНК из шага 1.21.1. Пипетки, 20 мкл ДНК в новые 1.5 мл пробирок из трех различных мест в трубке HMW ДНК с помощью Р200 широкий несут советы. Возьмите 1 мкл от три аликвоты для определения концентрации с использованием флуориметр и качество, с использованием УФ чтения. Проверить несколько раз для подтверждения результатов.
Примечание: Ожидаемые результаты показаны на рисунке 3A. OD260/280 значение приблизительно 1.9 и значение260/230 ОД приблизительно 2.3. - Передачи оставшихся 940 мкл HMW ДНК в 50 мл трубки шапочка с P1000 широкий родила подсказка.
- Аспирационная все ДНК в 1 мл шприц без иглы.
- Положите 27 G иглу на шприц и извлечь все ДНК в колпачок, осторожно и медленно (~ 10 s). Взлет 27 G иглу от шприца.
- Повторите шаги 2.1.4 и 2.1.5 для 29 раз в общей сложности 30 проходит через иглу.
Примечание: Стриженый HMW ДНК может храниться при температуре 4 ° C в темноте, вплоть до 24 ч. контроля качества (КК) настоятельно рекомендуется электрофорезом геля импульсного поля, но он является дорогостоящим и трудоемким. Если выполнение КК на машине электрофореза геля автоматизированной импульса поля используют протокол 5-150 КБ для 20 h работать. Ожидаемые результаты показаны на рисунке 4. - Подготовить ремонт реакции ДНК в 0,2 мл трубки, добавив 100 мкл стриженый HMW ДНК (20 мкг), 15 мкл буфера ремонт FFPE ДНК, 12 мкл FFPE ДНК ремонт смеси и 16 мкл нуклеиназы свободной воды. Смешать реакции, стряхивая нежно 6 раз и спина до удалить пузыри.
- Инкубируйте реакции при 20 ° C для 60 мин передачи образца в новой 1,5 мл трубку с наконечником широкий диаметр Р200.
- Магнитные бусы Ресуспензируйте закупорить или vortexing. Аккуратно добавьте 143 мкл бусины (1 x) реакции восстановления ДНК и смеси, стряхивая трубка 6 раз. Поворачивайте трубку на ротатор смеситель на RT на 20 об/мин за 30 мин.
- Спин вниз выборки в 1000 x g 2 s на RT. месте трубку на магнитные стойки для 10 min. держать трубку на магнитные стойки и удалить супернатант.
- Держать трубку на магнитные стойки, добавьте 400 мкл свежеприготовленные 70% этанола не нарушая гранулы. Удаление этанол 70% после 30 s.
- Повторите шаг 2.1.11 один раз.
- Спин вниз выборки в 1000 x g 2 s на RT. месте трубку обратно на магнитные стойки. Удалите любые остаточные этанола и воздух сухой для 30 s. Не более сухие гранулы.
- Снять трубку из магнитные стойки и добавьте 103 мкл TE (10 мм 1 мм и трис ЭДТА, рН 8,0). Аккуратно Флик трубки для обеспечения что бусины покрыты в буфере и инкубировать на мешалке ротатор на RT на 30 мин осторожно Флик трубку каждые 5 мин для помощи ресуспендирования гранул.
- Пелле бусы на магнитные стойки для по крайней мере 10 минут передачи 100 мкл элюата с Р200 широкий родила подсказка в 0,2 мл трубку.
- Подготовьте конце ремонта и реакцию dA хвостохранилища в 0,2 мл, добавляя 100 мкл отремонтированы HMW ДНК, 14 мкл буфера ремонт/dA хвостохранилища целью и 7 мкл конце ремонта/dA хвостохранилища смеси. Смешать реакции, стряхивая нежно 6 раз и спина до удалить пузыри.
- Инкубировать реакции при 20 ° C 60 мин, следуют 65 ° C для 20 минут, а затем, удерживая в 22° C. Передачи, которые несут образца в новой 1,5 мл трубку с помощью Р200 широкий наконечник.
- Магнитные бусы Ресуспензируйте закупорить или vortexing. Добавить 48 мкл бисера (0,4 x) в конце ремонта/dA хвостохранилища реакции и смешайте нежно, стряхивая трубка 6 раз. Поворачивайте трубку на ротатор смеситель на RT на 20 об/мин за 30 мин.
- Повторите шаги 2.1.10-2.1.13 раз.
- Снять трубку из магнитные стойки и добавьте 33 мкл TE (10 мм 1 мм и трис ЭДТА, рН 8,0). Аккуратно Флик трубки для обеспечения что бусины покрыты в буфере и инкубировать на мешалке ротатор на RT на 30 мин осторожно Флик трубку каждые 5 мин для помощи ресуспендирования гранул.
- Пелле бусы на магнитные стойки для по крайней мере 10 минут передачи 30 мкл элюата с Р200 широкий родила подсказка в новой 1,5 мл трубку. Занять дополнительно 1-2 мкл для определения концентрации с использованием флуориметр.
Примечание: Ожидается восстановление 5-6 мкг на этот шаг. - Подготовьте реакции перешнуровки в 1,5 мл образца путем добавления 30 мкл отремонтированы конец HMW ДНК, 20 мкл, комплекса (AMX 1D) адаптер и 50 мкл Блант/TA лигирование мастер смеси. Смешайте реакции, стряхивая нежно 6 раз между каждым последовательного сложения и спин вниз удалить пузыри.
- Инкубируйте реакции на RT 60 мин.
- Магнитные бусы Ресуспензируйте закупорить или vortexing. Добавить бусины 40 мкл (0,4 x) в реакции перешнуровки и смешайте нежно, стряхивая трубка 6 раз. Поворачивайте трубку на ротатор смеситель на RT на 20 об/мин за 30 мин.
- Повторите шаг 2.1.10 один раз.
- Добавьте 400 мкл адаптер шарик привязки (АББ) буфера в трубу. Жестом пролистывания трубка мягко 6 раз Ресуспензируйте бисер. Установите трубку обратно на магнитные стойки для разделения бусы из буфера и удалить супернатант.
- Повторите шаг 2.1.26 один раз.
- Спин вниз выборки в 1000 x g 2 s на RT. месте трубку обратно на магнитные стойки. Удалите любые остаточные буфера и воздух сухой для 30 s. Не более сухие гранулы.
- Снять трубку из магнитные стойки и Ресуспензируйте гранулы в 43 мкл буфера. Аккуратно Флик трубки для обеспечения бусины покрыты в буфере и инкубировать на мешалке ротатор на RT на 30 мин осторожно Флик трубку каждые 5 мин для помощи ресуспендирования гранул.
- Пелле бусы на магнитные стойки для по крайней мере 10 минут передачи 40 мкл элюата с Р200 широкий родила подсказка в новой 1,5 мл трубку. Занять дополнительно 1-2 мкл для определения концентрации с использованием флуориметр.
Примечание: Ожидается восстановление 1-2 мкг на этот шаг. Механический стрижка основанные Библиотека готова для загрузки. Библиотека может храниться на льду до 2 ч до загрузки для виртуализации при необходимости.
- Оттепель и смеси реагентов от перевязки комплекта (см. Таблицу материалы). Оттепели FFPE ДНК ремонт буфера и конец буфера ремонт/dA хвостохранилища на льду, затем вихря и спина до микс. Оттепель адаптер микс (AMX) и адаптер шарик привязки буфера (АББ) на льду, а затем пипеткой и спин вниз смешивать. Оттепель работает буфер с топливной смеси (РБФ) и Элюирующий буфер (СОБ) на RT, а затем вихря и спин вниз смешивать. Оттепель загрузкой бусины (LLB) библиотек в RT и пипетки перемешать перед использованием.
- Строительство на основе фрагментации библиотека Транспозаза
- Оттепель реагенты от Транспозаза комплекта (см. Таблицу материалы). Оттепель фрагментации микс (FRA) и быстрый адаптер (РЭП) на льду и пипетки смешивать. Оттепель последовательности буфера (ГКК), Загрузка бусины (LB), очистка буфера (FLB) и флеш троса (FLT) на RT и Пипетка смешивать. Оттепель бусины (LB) загрузки на RT и пипетки перемешать перед использованием. После размораживания, держите все компоненты комплекта на льду. Вывезти ферменты только при необходимости.
- Проверьте качество и количество HMW ДНК из шага 1.21.2. Пипетки, 20 мкл ДНК в новые 1.5 мл пробирок из трех различных мест в трубке HMW ДНК с помощью Р200 широкий несут советы. Возьмите 1 мкл от три аликвоты для определения концентрации с использованием флуориметр и качество, с использованием УФ чтения. Проверить несколько раз для подтверждения результатов.
Примечание: Ожидаемые результаты показаны на рисунке 3B. OD260/280 значение приблизительно 1.9 и значение260/230 ОД приблизительно 2.3. - Подготовьте реакции tagmentation ДНК в 0,2 мл трубку, добавив 22 мкл HMW ДНК, 1 мкл 10 мм, трис (рН 8,0) с 0,02% Тритон X-100 и 1 мкл фрагментации смесь (FRA). Микс, дозирование с Р200 широкий родила подсказка как можно медленнее 6 раз, стараясь не ввести пузыри.
- Инкубировать реакции на 30 ° C в течение 1 мин, следуют 80 ° C в течение 1 мин, а затем, удерживая при 4 ° C. Передача смеси в новой 1,5 мл трубку с Р200 широкий родила подсказка и перейти на следующий шаг сразу.
- Добавьте 1 мкл быстрого адаптера (РЭП) в 1,5 мл образца. Микс, дозирование с Р200 широкий родила подсказка как можно медленнее 6 раз, стараясь не ввести пузыри.
- Инкубируйте реакции на RT 60 мин.
Примечание: На основе фрагментации библиотека Транспозаза готова для загрузки. Библиотека может храниться на льду до 2 ч до загрузки для виртуализации при необходимости.
3. последовательность на устройстве Нанопор
- Проверьте устройство последовательности Нанопор (см. Таблицу материалы). Убедитесь в том, как работают программного и аппаратного обеспечения, так и достаточно места для хранения.
- Проверка потока клеток. Открыть новую ячейку потока и вставить в ячейку потока в Нанопор устройство. Убедитесь, что поле расположение ячейки поток был вставлен в (X1-X5). Выберите тип ячейки правильного потока. Нажмите на Клетки проверить поток рабочего процесса. Нажмите на кнопку Начать тест для запуска потока клеток КК анализ.
Примечание: Если номер сообщалось всего активных поры менее 800, используйте другую ячейку нового потока для виртуализации. - Подготовьте грунтовки буфера. Для механического стрижки на основе библиотеки, добавить 576 мкл буфера с топливной смеси (РБФ) и 624 мкл в 1,5 мл воды, свободной от нуклеиназы. Вортекс и спин вниз микс грунтование буфера. Для библиотеки на основе фрагментации Транспозаза добавьте 30 мкл скрытой троса (FLT) трубки буфера очистки (FLB). Вортекс и спин вниз микс грунтование буфера.
- На ячейку потока переместите крышку порта грунтовки по часовой стрелке выставить порт грунтовки.
- Установите P1000 пипетки 100 мкл и вставьте наконечник в порт грунтовки. Привлечь обратно небольшой объем буфера (менее 30 мкл), чтобы удалить любые пузыри из потока клетки. Остановите, закупорить после того, как небольшое количество желтой жидкости входит наконечник.
- Для загрузки 800 мкл Грунтующие смеси в ячейку потока через порт грунтовки используйте P1000 пипетки. Чтобы избежать пузырей, добавьте 30 мкл Грунтующие смеси для покрытия верхней части порта грунтование сначала, затем вставьте наконечник в порт грунтовки и медленно добавить остальные Грунтующие смеси. Вывезти кончик, когда есть около 50 мкл слева. Добавьте остальные Грунтующие смеси на вершине порт грунтовки. Жидкости будет идти внутри сам по себе.
- Оставьте установки для инкубации за 5 мин. В то же время готовить смесь библиотеки в 1,5 мл, содержащий библиотеку.
Примечание: Для механических стрижки на основе библиотеки мкл 35 работает буфер с топливной смеси (РБФ) 40 мкл библиотеки ДНК. Для библиотеки на основе фрагментации Транспозаза добавить 34 мкл буфера последовательности (ГКК) и 16 мкл нуклеиназы свободной воды 25 мкл библиотеки ДНК. - Открывайте крышку порт образец клеток потока аккуратно выставить порт образца. Использование пипетки P1000 добавить 200 мкл Грунтующие смеси через порт грунтовки в ячейку потока, как описано в шаге 3.5. Убедитесь, что смесь грунтовки не загружается в ячейку потока через порт образца.
- Установите Р200 пипетки 80 мкл. Осторожно перемешать библиотека с широким отверстием кончиком, закупорить вверх и вниз 6 раз просто до погрузки.
- Загрузите библиотеку микс каплям через порт образца в ячейку потока. Добавьте каждую каплю только после того, как предыдущий капля полностью загружается в порт.
- Осторожно установите крышку порта образца и убедитесь, что порт образца полностью покрыта. Переместите крышку порта грунтование против часовой стрелки для покрытия порт грунтовки. Закройте крышку устройства.
- Нажмите на Новый эксперимент рабочего процесса. Введите имя библиотеки, выберите правильный набор согласно используемые процедуры и проверьте, что параметры указаны правильно (запуска, реальном времени базы вызов на 48 ч).
- Нажмите кнопку Пуск, выполнить. После 10 минут записи потока cell ID и активных Нанопор чисел (общее количество и номера каждого четыре группы) от выполнения информации.
- Анализ данных. Скопируйте данные с локального компьютера или кластера в любое время из последовательности или при завершении выполнения. Используйте Minimap216 (https://github.com/lh3/minimap2) для выравнивания данных последовательности генома ссылку. Суммируйте производительности виртуализации от необработанные данные о последовательности и ряды NanoPlot17 (https://github.com/wdecoster/NanoPlot).
Результаты
Ультра-длинный протокол секвенирования ДНК применяется HMW ДНК на строительство библиотеки. Таким образом, важно выбрать хорошо культивируемых клеток с живой соотношение > 85% в ячейку шаг для сбора урожая. Количество ячеек, которые используются для извлечения ДНК будет влиять на качество и количество HMW ДНК. Лизис клеток не хорошо работать, если начиная с слишком много клеток. Использование слишком мало клеток не создает достаточно ДНК на строительство библиотеки потому что осадков HMW ДНК выполняется с использованием мягкое вращение вручную вместо высокоскоростной центрифуги. Пример HMW ДНК после добавления ледяной 100% этанола и вращения отображается как Белый преципитат хлопок как на рисунке 2.
Важно проверить качество ввода ДНК до начала строительства библиотеки. Деградации, неправильный количественной оценки, загрязнения (например, белки, РНК, моющие средства, ПАВ и остаточные фенол или этанола) и низкомолекулярных ДНК может иметь значительное влияние на последующих процедур и на финале читать длины. Рекомендуется выполнять с помощью ДНК из трех различных мест в пробирку, содержащую HMW ДНК анализ КК. От УФ чтение результатов для HMW ДНК ОД260/OD280 значение приблизительно 1.9 и ОД260/OD230 значение приблизительно 2.3 (Рисунок 3АB). Эти значения коэффициента согласуются среди трех тестов для хорошей HMW ДНК образца. Различные методы стрижка требует различных объемов ввода ДНК. Концентрация ДНК HMW должна быть > 200 нг/мкл для механической резки в то время как она должна быть > 1 мкг/мкл Транспозаза фрагментации. Концентрация определяется флуориметр немного ниже, чем УФ чтения. Однако коэффициент вариации концентрации же HMW ДНК образца должен быть менее 15% с флуориметр и УФ, чтение анализов. Механической резки применяется шприц с иглой сломать HMW ДНК, так что количество проходов через иглу будет влиять размер стриженый ДНК и финал читать длины. Рекомендуется выполнять размер КК, после того, как иглы, Ножницы механические для обеспечения большинства HMW ДНК больше чем 50 КБ, как показано на рисунке 4. В методе механических ножниц 30 проходит созданы наилучшие результаты секвенирования, учитывая длину и вывода.
N50 механических стрижки на основе библиотеки составляет 50-70 КБ Транспозаза библиотека на основе фрагментации при 90-100 КБ. Результаты четырех трасс с использованием линии клетки HG00733 приведены в таблице 1. Все четыре трассы имеют более 2300 читает с длиной более 100 КБ. Максимальная длина больше в Транспозаза на основе фрагментации библиотек (455 kb и 489 kb) по сравнению с механическим библиотеки на основе сдвига (348 КБ и 387 kb) хотя последний больше всего читает, указав более высокую доходность. Строительство на основе фрагментации библиотека Транспозаза имеет меньше шагов и короче время приготовления так, что он представит меньше короткие фрагменты. Две трассы, с помощью Транспозаза имеют больше средней длины (> 30 КБ) и средней длины (> 10 КБ). Кроме того данные показывает высокого качества в всех прогонов (показатель среднего качества является приблизительно 10.0, ~ 90% базовая точность). Более 97% всего баз были выровняны к геном человека ссылки (hg19), с помощью Minimap216 с параметрами по умолчанию. Ожидаемый размер распределения сырья гласит показаны на рисунке 5. Все запуски имеют значительную долю данных выше 50 КБ, а Транспозаза на основе фрагментации библиотеки имеют более высокий коэффициент, ультра-длинный гласит (например > 100 kb). Этот протокол был успешно применяется в нескольких линий клеток человека (Дополнительная таблица 1).

Рисунок 1: схема обзор процесса Нанопор Лонг чтения последовательности (РНБ seq). Оранжевый, Транспозаза комплекс. Желто зеленый, Нанопор адаптер. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
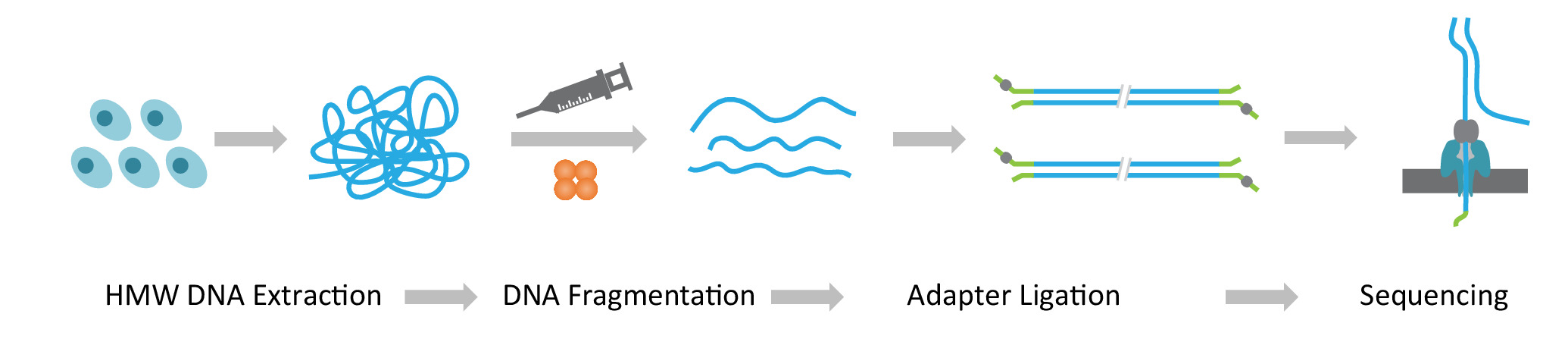{kind=link}

Рисунок 2: представитель ДНК осадков от метода извлечения фенол хлороформ. Белая стрелка указывает HMW ДНК. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 3: пример QC результаты HMW ДНК от УФ чтения. (A) HMW ДНК из шага 1.21.1 готов для строительства механических стрижки на основе библиотеки. (B) HMW ДНК из шага 1.21.2 для строительства на основе фрагментации библиотеки Транспозаза. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 4: QC результаты иглы стриженый HMW ДНК электрофорезом геля импульсного поля. L1: Быстрый нагрузки 1 kb ДНК лестница; L2: Быстрый нагрузки 1 КБ продлить лестница ДНК. 1-8: ДНК с различными проходящей раз через иглу стрижки. 1-3, не резки; 4, 10 раз; 5, 20 раз; 6, 30 раз; 7, 40 раз; 8, 50 раз. Этот шаг КК является необязательным. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}

Рисунок 5: ожидаемый размер распределения библиотек долговечный ДНК Нанопор. MS, механические библиотеки на основе сдвига. TF, Транспозаза на основе фрагментации библиотек. Пожалуйста, нажмите здесь, чтобы посмотреть большую версию этой фигуры.
{kind=link}
| Механические shearing_rep1 | Механические shearing_rep2 | Транспозаза fragmentation_rep1 | Транспозаза fragmentation_rep2 | |
| Клеточная линия | HG00733 | HG00733 | HG00733 | HG00733 |
| N50 гласит: | 55,180 | 63,007 | 98,237 | 95,629 |
| Количество операций чтения больше чем 100 КБ | 2500 | 3,082 | 2,386 | 2355 |
| Количество всего читает | 97,859 | 80,465 | 24,166 | 21,032 |
| Максимальная длина (bp) | 348,482 | 387,113 | 454,660 | 489,426 |
| Средняя длина (bp) | 17.861 | 20,395 | 33,528 | 38,175 |
| Средней длины (bp) | 5,335 | 5,894 | 10,249 | 15,656 |
| Среднее качество гласит: | 10,0 | 10.1 | 9,9 | 10,0 |
| Общая основы сырья чтений | 1,747,849,822 | 1,641,058,932 | 810,229,733 | 802,886,304 |
| Общая основы унифицированных чтений | 1,693,300,832 | 1,607,975,925 | 791,422,077 | 778,417,627 |
| Сопоставленные соотношение всего баз (hg19, Minimap2) | 96,9% | 98.0% | 97,7% | 97,0% |
| Количество активных поры | 1225: 480, 402, 254, 89 | 1058: 480, 356, 176, 46 | 958: 452, 328, 148, 30 | 1092: 487, 367, 195, 43 |
Таблица 1: Резюме от метрики производительности работает с различными протоколами, стрижка.
| Библиотека 1 | Библиотека 2 | |
| Клеточная линия | K562 | GM19240 |
| Ячейка, информация о заказе | ATCC, Кот. LOL CCL-243 | Институт Coriell, Кот. LOL GM19240 |
| Протокол | механический стрижка | механический стрижка |
| N50 гласит: | 60,063 | 55,295 |
| Количество всего читает | 193,783 | 120,807 |
| Средней длины (bp) | 1,843 | 4,688 |
| Средняя длина (bp) | 9,825 | 17,408 |
| Максимальная длина (bp) | 548,780 | 212,338 |
| Общая основы сырья чтений | 1,903,989,686 | 2,103,015,331 |
| Общая основы унифицированных чтений | 1,837,350,047 | 1,997,419,761 |
| Сопоставленные соотношение всего баз (hg19, Minimap2) | 96,6% | 95,0% |
| Количество активных поры | 1111: 482, 371, 203, 55 | 1032: 447, 333, 196, 56 |
Дополнительная таблица 1: Резюме двух РНБ seq запусков с помощью других клеточных линий с механических ножниц протоколом.
Обсуждение
В принципе секвенирование Нанопор способен генерировать 100 КБ до megabase читает в длину11,12,13. Четыре основных фактора влияют на производительность последовательности выполнения и качества данных: 1) числа активных поры и деятельность поры; 2) мотор белок, который контролирует скорость ДНК, проходя через Нанопор; 3) ДНК шаблон (длина, чистоту, качество, массовые); 4) последовательности адаптер лигирование эффективность, которая определяет полезной ДНК из образца ввода. Первые два фактора зависят от версии потока ячейки и комплект последовательности, представленной изготовителем. Вторая два фактора являются важнейшие шаги в настоящем Протоколе (экстракции ДНК HMW, стрижка и маточных труб).
Этот протокол требует терпения и практики. Для ультра-долгий библиотеки ДНК6важно качество HMW ДНК. Протокол начинается с клетки, собранные с высокой жизнеспособности (> 85% жизнеспособных клеток предпочитали), ограничивая деградации ДНК от мертвых клеток. Следует избегать любых суровых процесс, который может ввести повреждений ДНК (например, сильное беспокойство, пожимая, вихря, несколько дозирования, неоднократные замораживания и оттаивания). В разработке протокола мы опускаем, дозирование в весь процесс экстракции ДНК. Широкое отверстие советы должны быть использованы когда закупорить необходим после механической резки во время строительства библиотеки и последовательности. Как Нанопоры чувствительны к химия в камеру буфера12, должна существовать как несколько остаточных загрязнителей (например, моющие средства, ПАВ, фенол, этанол, белки РНК, и т.д.) как можно скорее в ДНК. Учитывая длину и урожайности метод экстракции фенольных показывает лучшие и наиболее воспроизводимые результаты, по сравнению с несколькими различных извлечения методы испытания пока.
Несмотря на способность производить Лонг чтения последовательности, этот протокол по-прежнему остаются некоторые ограничения. Во-первых этот протокол был оптимизирован на основе Нанопор последовательности устройства, имеющиеся на момент публикации; Таким образом он ограничивается выборочной основе Нанопор последовательности химии и может быть неоптимальной, когда выступал в других типов устройств Лонг чтения последовательности. Во-вторых результат сильно зависит от качества ДНК, извлеченные из исходного материала (ткани или клетки). Чтение длина будет снижена, если начальный ДНК уже деградированных или повреждены. В-третьих хотя несколько КК шаги включены в протокол для проверки качества ДНК, окончательный выход и длина гласит могут быть затронуты в ячейку потока и поры деятельность, которая может быть переменной на этой ранней стадии Нанопор виртуализации платформы развития.
Протокол, в описанный здесь использует образцы линии клетки человека подвеска для экстракции ДНК. Мы оптимизировали проходящей раз в иглу, стрижка, соотношение HMW ДНК Транспозаза и перевязка времени для получения результатов, описанных. Протокол может быть расширен четырьмя способами. Во-первых пользователи могут начать с других культивируемых клеток млекопитающих и различное количество клеток, тканей, клинические образцы или других организмов. Потребуется дальнейшая оптимизация на время инкубации лизиса, том реакции и центрифугирования. Во-вторых это трудно предсказать размер целевого для ультра-долгий чтения последовательности. Если чтение длина короче, чем ожидалось, пользователи могут настроить проходящей раз в механический метод, основанный на стрижки или изменить отношение HMW ДНК в Транспозаза в методе Транспозаза на основе фрагментации. Длиннее время привязки и элюции во время очистки шаги полезны, потому что HMW ДНК вязкие. В-третьих с различными Нанопор последовательности устройств, один можно настроить количество и объем ДНК, чтобы соответствовать критериям программы sequencer. В-четвертых будет виртуализированных только ДНК, лигируют последовательности адаптерам. Для дальнейшего повышения эффективности перевязки, одно может попытаться Титруйте адаптер и лигаза концентрации. Изменение лигирование время и молекулярных скоплению агентов, таких как PEG18 может применяться в будущем. Ультра-длинный протокол секвенирования ДНК в сочетании с ТРИФОСФАТЫ19,20 может предложить эффективный инструмент для обогащения последовательности целевого объекта.
Раскрытие информации
Авторы заявляют, что они не имеют никаких финансовых интересов.
Благодарности
Авторы благодарят Y. Чжу за ее замечания по рукописи. Исследования, сообщили в настоящем издании частично поддерживается национального института рака национальных институтов здоровья под награду номер P30CA034196. Содержание является исключительно ответственности авторов и не обязательно отражают официальную точку зрения национальных институтов здоровья.
Материалы
| Name | Company | Catalog Number | Comments |
| Reagents | |||
| Absolute ethanol | Sigma-Aldrich | E7023 | |
| Agencourt AMPure XPbeads | Beckman | A63881 | magnetic beads for cleanup |
| BD conventional needles | Becton Dickinson | 305136 | 27G, for mechanical shearing |
| BD Luer-Lok syringe | Becton Dickinson | 309628 | for mechanical shearing |
| Blunt/TA Ligase Master Mix | NEB | M0367S | |
| Countess Cell Counting Chamber Slides | Invitrogen | C10228 | for cell counting |
| EDTA | Invitrogen | AM9261 | pH 8.0, 0.5 M, 500 mL |
| Flow Cell | Oxford Nanopore Technologies | FLO-MIN106 | R9.4.1 |
| HG00773 cells | Coriell Institute | HG00733 | cells used in this protocol |
| Ligation Sequencing Kit 1D | Oxford Nanopore Technologies | SQK-LSK108 | nanopore ligation kit |
| MaXtract High Density tubes | Qiagen | 129073 | gel tubes |
| NEBNext FFPE DNA Repair Mix | NEB | M6630S | |
| NEBNext Ultra II End Repair/dA-Tailing Module | NEB | M7546S | |
| Nuclease-free water | Invitrogen | AM9937 | |
| Phosphate-Buffered Saline, PBS | Gibco | 70011044 | 10X, pH 7.4 |
| Phenol:chloroform:IAA | Invitrogen | AM9730 | |
| Proteinase K | Qiagen | 19131 | 20 mg/mL |
| Qubit dsDNA BR Assay Kit | Invitrogen | Q32850 | fluorometer assays for DNA quantification |
| Rapid Sequencing Kit | Oxford Nanopore Technologies | SQK-RAD004 | nanopore transposase kit |
| RNase A | Qiagen | 19101 | 100 mg/mL |
| SDS | Invitrogen | AM9822 | 10% (wt/vol) |
| Sodium chloride solution | Invitrogen | AM9759 | 5.0 M |
| TE buffer | Invitrogen | AM9849 | pH 8.0 |
| Tris | Invitrogen | AM9856 | pH 8.0, 1 M |
| Triton X-100 solution | Sigma-Aldrich | 93443 | ~10% |
| Name | Company | Catalog Number | Comments |
| Equipment | |||
| Bio-Rad C1000 Thermal Cycler | Bio-Rad | 1851196EDU | |
| Centrifuge 5810R | Eppendorf | 22628180 | |
| Countess II FL Automated Cell Counter | Life Technologies | AMQAF1000 | for cell counting |
| DynaMag-2 Magnet | Life Technologies | 12321D | magnetic rack |
| Eppendorf ThermoMixer | Eppendorf | 5382000023 | for incubation |
| Freezer | LabRepCo | LHP-5-UFMB | |
| GridION | Oxford Nanopore Technologies | GridION X5 | nanopore device used in this protocol |
| HulaMixer Sample Mixer | Thermo Fisher Scientific | 15920D | rotator mixer |
| MicroCentrifuge | Benchmark Scientific | C1012 | |
| NanoDrop ND-1000 Spectrophotometer | Thermo Fisher Scientific | ND-1000 | for UV reading |
| Pippin Pulse | Sage Science | PPI0200 | pulsed-field gel electrophoresis instrument |
| Qubit 3.0 Fluorometer | Invitrogen | Q33216 | fluorometer |
| Refrigerator | LabRepCo | LABHP-5-URBSS | |
| Vortex-Genie 2 | Scientific Industries | SI-A236 | |
| Water bath | VWR | 89501-464 |
Ссылки
- Mardis, E. R. Next-generation sequencing platforms. Annual Review of Analytical Chemistry. 6, 287-303 (2013).
- Goodwin, S., McPherson, J. D., McCombie, W. R. Coming of age: ten years of next-generation sequencing technologies. Nature Reviews Genetics. 17 (6), 333-351 (2016).
- Shendure, J., et al. DNA sequencing at 40: past, present and future. Nature. 550 (7676), 345-353 (2017).
- Alkan, C., Coe, B. P., Eichler, E. E. Genome structural variation discovery and genotyping. Nature Reviews Genetics. 12 (5), 363-376 (2011).
- Weischenfeldt, J., Symmons, O., Spitz, F., Korbel, J. O. Phenotypic impact of genomic structural variation: insights from and for human disease. Nature Reviews Genetics. 14 (2), 125-138 (2013).
- Pollard, M. O., Gurdasani, D., Mentzer, A. J., Porter, T., Sandhu, M. S. Long reads: their purpose and place. Human Molecular Genetics. 27 (R2), R234-R241 (2018).
- Cretu Stancu, M., et al. Mapping and phasing of structural variation in patient genomes using nanopore sequencing. Nature Communications. 8 (1), 1326(2017).
- Gong, L., et al. Picky comprehensively detects high-resolution structural variants in nanopore long reads. Nature Methods. 15 (6), 455-460 (2018).
- Sedlazeck, F. J., et al. Accurate detection of complex structural variations using single-molecule sequencing. Nature Methods. 15 (6), 461-468 (2018).
- Jain, M., et al. Nanopore sequencing and assembly of a human genome with ultra-long reads. Nature Biotechnology. 36 (4), 338-345 (2018).
- Jain, M., et al. Improved data analysis for the MinION nanopore sequencer. Nature Methods. 12 (4), 351-356 (2015).
- Deamer, D., Akeson, M., Branton, D. Three decades of nanopore sequencing. Nature Biotechnology. 34 (5), 518-524 (2016).
- Jain, M., Olsen, H. E., Paten, B., Akeson, M. The Oxford Nanopore MinION: delivery of nanopore sequencing to the genomics community. Genome Biology. 17 (1), 239(2016).
- Editorial, The long view on sequencing. Nature Biotechnology. 36 (4), 287(2018).
- Jain, M., et al. Linear assembly of a human centromere on the Y chromosome. Nature Biotechnology. 36 (4), 321-323 (2018).
- Li, H. Minimap2: pairwise alignment for nucleotide sequences. Bioinformatics. 34, 3094-3100 (2018).
- De Coster, W., D'Hert, S., Schultz, D. T., Cruts, M., Van Broeckhoven, C. NanoPack: visualizing and processing long-read sequencing data. Bioinformatics. 34, 2666-2669 (2018).
- Akabayov, B., Akabayov, S. R., Lee, S. J., Wagner, G., Richardson, C. C. Impact of macromolecular crowding on DNA replication. Nature Communications. 4, 1615(2013).
- Gabrieli, T., Sharim, H., Michaeli, Y., Ebenstein, Y. Cas9-Assisted Targeting of CHromosome segments (CATCH) for targeted nanopore sequencing and optical genome mapping. bioRxiv. , (2017).
- Gabrieli, T., et al. Selective nanopore sequencing of human BRCA1 by Cas9-assisted targeting of chromosome segments (CATCH). Nucleic Acids Research. , (2018).
Перепечатки и разрешения
Запросить разрешение на использование текста или рисунков этого JoVE статьи
Запросить разрешениеСмотреть дополнительные статьи
This article has been published
Video Coming Soon
Авторские права © 2025 MyJoVE Corporation. Все права защищены